
Introducing GreyNoise Block: Fully configurable, real-time blocklists
Discover why traditional blocklists fail and how GreyNoise Block offers real-time, configurable, low-noise IP blocking powered by primary-sourced intelligence.

The Model Context Protocol (MCP) lets AI systems securely connect to external data and tools — a key building block for emerging AI-driven operations. It’s also a new piece of internet-facing infrastructure, which means defenders are asking the same question they ask of anything exposed online: is anyone attacking it yet?
To find out, GreyNoise deployed a series of MCP honeypots to observe what actually happens when AI middleware meets the open internet.
Each honeypot mimicked a plausible MCP deployment, instrumented for full packet-level visibility. We built three configurations:
All were isolated from production systems.
Every instance was discovered within days — proof that anything listening on the internet will be found quickly. After that, activity leveled off. We saw the usual: HTTP probes, SSH touches, and other one-shot scans indistinguishable from the constant hum that hits everything else online.
Across the deployment, no MCP-specific payload or exploitation attempts appeared.
GreyNoise’s broader MCP Scanner tag, which tracks reconnaissance against MCP endpoints, shows that threat actors are indeed discovering exposed MCP servers — and increasingly so.
In October 2025, independent researchers demonstrated a prompt-hijacking flaw in a custom MCP build that used a deprecated protocol handler. It was a contained proof-of-concept, not an attack in the wild — and it supports the same conclusion: present-day MCP exposure risk lies in implementation errors, not in deliberate targeting of MCPs as a class.
Sometimes the absence of activity is the signal. Knowing what “normal” internet noise looks like gives defenders a baseline to detect the first real deviation — the point where interest becomes intent. Today, MCP traffic sits squarely within that background noise. When that changes, we’ll see it.
While defenders experiment with AI-enabled workflows, advanced adversaries are doing the same. Some threat actors are reportedly using MCP-style architectures to process stolen telemetry and correlate infrastructure, perhaps faster than human analysts could.
That marks a growing asymmetry: machine-speed offense versus human-speed defense. Bridging that gap requires AI SOCs — operations centers where AI agents assist analysts using verified, transparent data rather than opaque automation.
MCP offers one path to that balance: a structured, auditable way for both humans and AI systems to access and reason over trustworthy intelligence. Defensive AI only works when its data can be traced and its reasoning explained, and findings evidenced.
GreyNoise’s MCP honeypot experiment found no evidence of targeted attacks on AI middleware. MCPs are being noticed, but not pursued — yet.
This quiet defines the current baseline for AI middleware exposure. For defenders building toward AI-assisted operations, that baseline is the starting point.
GreyNoise recently launched its own MCP server, intentionally connected only to our API to ensure sound security. Human analysts and AI agents alike can use our MCP server to explore GreyNoise’s telemetry, automate jobs, and more.
Pair GreyNoise’s MCP server with our new offering, GreyNoise Block, to automate dynamic IP blocking based on custom deviations from baseline threat activity.

From August through October 2025, we observed (GreyNoise Visualizer) a clear ramp-up in exploitation attempts against PHP and PHP-based frameworks as actors push to deploy cryptominers. The query below captures a range of attempts (ThinkPHP, PHP CGI, PHPUnit, the recent PHP CVE-2024-4577, etc.), and the telemetry shows seven distinct attack patterns that move in parallel: steady in August–September, then spiking into October and November.
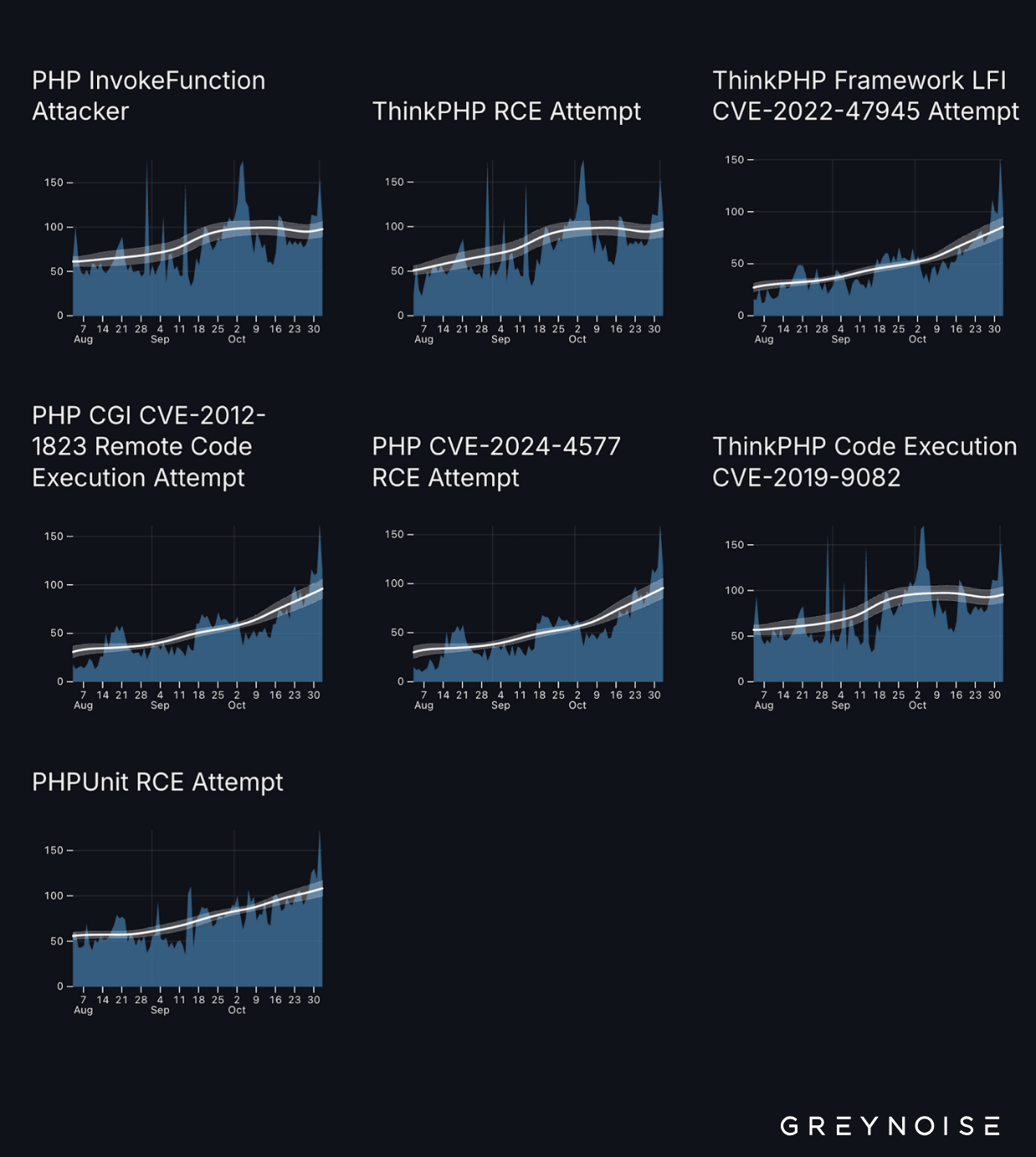
The loudest campaigns exploit ThinkPHP Framework LFI (CVE-2022-47945), PHP CGI (CVE-2012-1823), and PHP CVE-2024-4577, all of which show steep growth. Older chains (ThinkPHP Code Execution CVE-2019-9082, PHPUnit RCE) still produce meaningful volume—roughly 50–150 attempts per day—and the network graph implies these campaigns aren’t independent: they share infrastructure and tools, pointing to coordination or communal tooling.
Cloud providers constitute the majority of attacking IPs. Top offenders by IP count include Cloudflare (1,000 IPs), DigitalOcean (688), Google (536), and Contabo (512). The top 21 organizations account for about one-third of all attacking IPs—a mix of compromised customer VMs, misconfigured services, and rented infrastructure used for mining at scale.
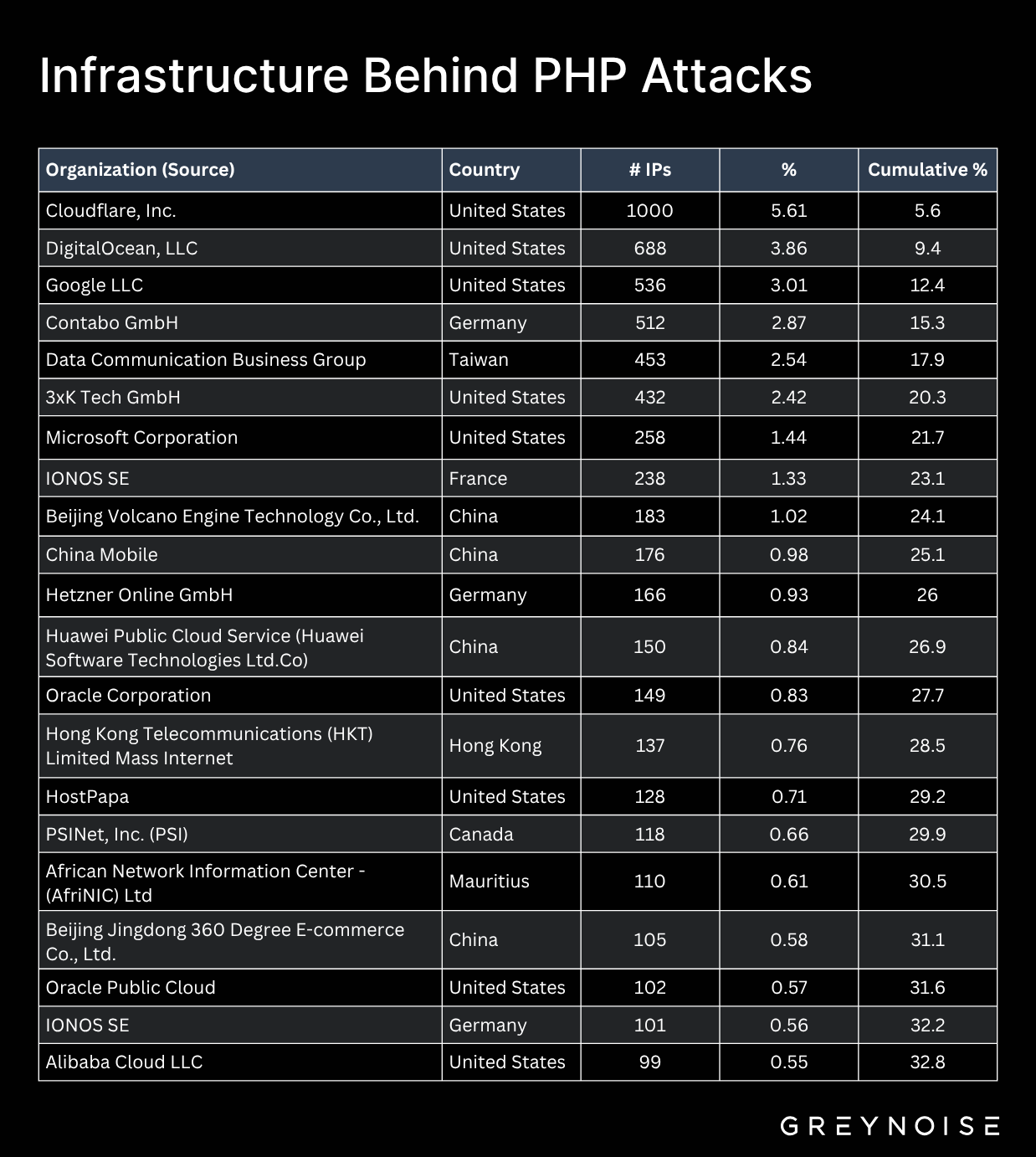
Geographically, the attacks are global: German hosters (Contabo, Hetzner), Taiwanese carriers, and Chinese cloud platforms (Beijing Volcano Engine, Huawei, Alibaba) alongside large North American providers. Attackers are simply using whatever compute they can either rent or compromise.
Timing matters. With Bitcoin trading above $110,000 and the crypto market cap over $3.71 trillion, the math for miners is attractive. November has historically been a strong month for Bitcoin—the dataset going back to 2013 shows outsized gains in November (some years dramatically so). If Bitcoin rises from $70k to $110k, identical mining power suddenly produces ~57% more revenue.
Market projections referenced here are bullish—some analysts have mid-month price targets in the $120k–$125k range, and a few institutions have higher year-end targets. Monetary policy has also loosened recently: a 25-basis-point Fed cut in early November, the prospect of another cut in December, and an announced end to quantitative tightening on December 1 all increase liquidity that can flow into risk assets. Those conditions make mining more profitable now than a few months ago.
For attackers, that’s a simple incentive: higher price = higher payoff for the same stolen CPU cycles. They’re trying to scale into the window of maximum short-term profitability.
Cryptomining is attractive because its economics favor stealth and scale. Unlike ransomware, which requires victims and payment infrastructure, mining converts compute to coin with minimal friction. There are no negotiations, no human-in-the-loop—just silent revenue flow.
Cloud cryptojacking activity rose roughly 20% in 2025, showing that mining is now a commodity crime. The playbook is straightforward: scan, compromise, deploy a miner (binary, Docker image, or script), and funnel rewards to mining pools controlled by the attackers. Victims pick up the electricity and infrastructure cost while attackers collect the proceeds.
The barrier to entry is low: exploit kits, prebuilt miners, and scanners are widely available. Often, a successful chain of automated steps—probe, exploit, payload fetch, execute—is all that’s needed to get mining capacity online.
PHP is everywhere: from tiny CMS installs to large web apps. Many sites run unpatched or old framework versions, and ThinkPHP—popular in parts of Asia but also found globally—shows up frequently in these campaigns.
The exploited vulnerabilities span a lengthy timeline (2012–2024), highlighting a core problem: old vulnerabilities don’t go away just because they’re old. Organizations patch parts of their stack, but legacy frameworks and forgotten installs remain exploitable. That persistence creates a reliable attack surface.
Internet-facing servers are preferred mining targets because they have more compute, run continuously, and often tolerate high resource use—so miners get better yield and longer uptime than they would from end-user devices.
These campaigns use methodical internet scanning to find vulnerable PHP installs. Exploitation is typically automated; the same exploit will successfully target hundreds or thousands of identical stacks. Cryptominer deployment follows a standard recipe and is typically fully automated.
Because mining doesn’t exfiltrate sensitive data or immediately crash systems, it can persist for long periods. The miner quietly consumes CPU/GPU cycles and reports work to attacker-controlled pools. Victims notice degraded performance and higher costs long before they realize they’ve been harvested for crypto.
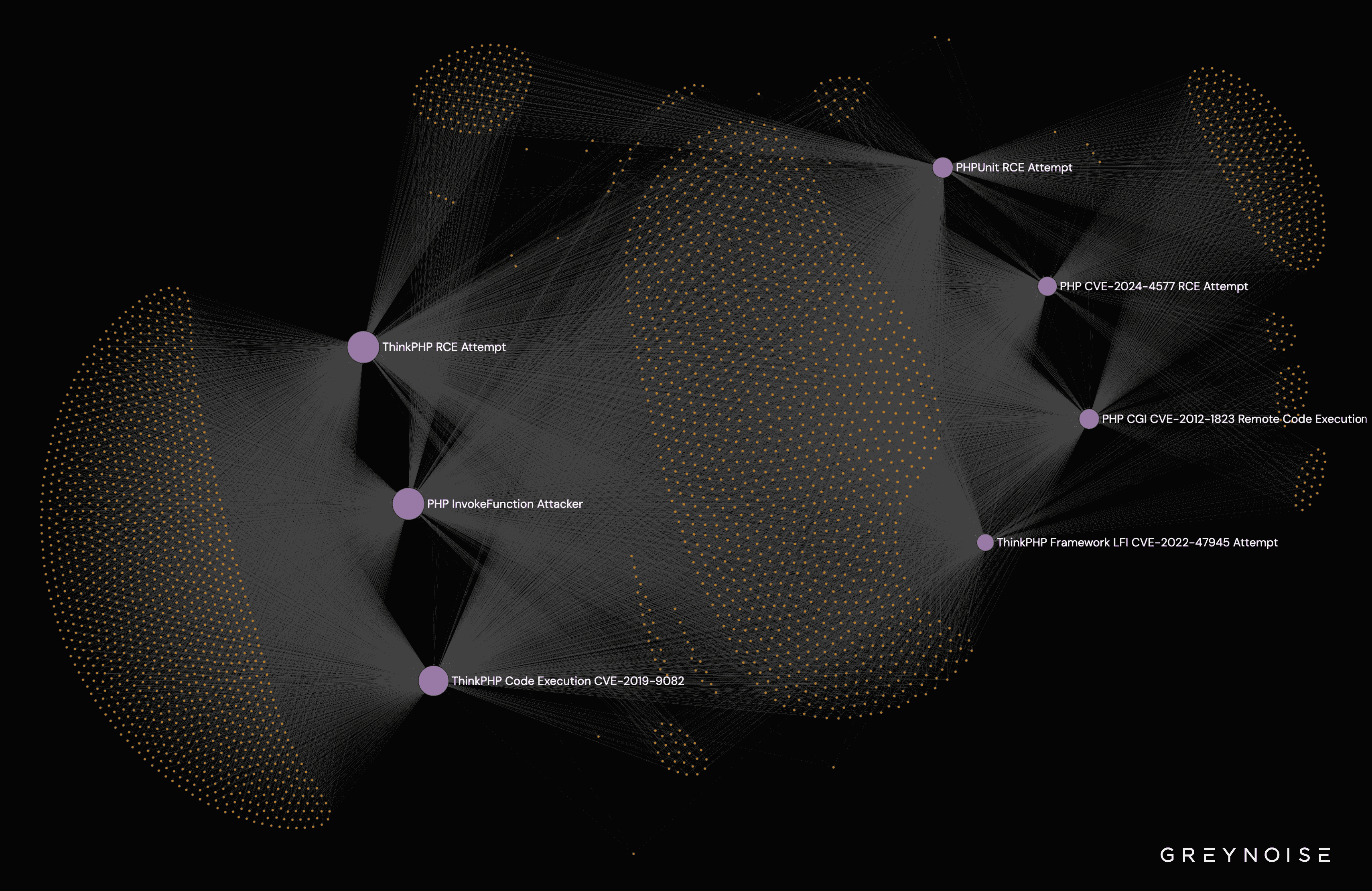
The network graph demonstrates interconnected operations: different vulnerability chains (PHPUnit RCE, ThinkPHP, PHP CGI) share infrastructure, which suggests either a single large group or multiple groups reusing the same toolsets and pool infrastructure.
This is early November 2025—historically a strong month for Bitcoin and, given current prices and recent monetary easing, an attractive window for miners. The activity spike through September and October looks like positioning: compromise now, mine during the high-value period.
If November follows historical patterns and prices climb materially, deployed miners will earn significantly more than they would have months earlier. The Fed’s easing and the end of QT add a tailwind for risk assets, further reinforcing the incentive for attackers to maximize deployed capacity now.
Put bluntly, it’s volume economics. Scan thousands, compromise hundreds, deploy miners, and collect coins. The exploited PHP vulnerabilities range from trivial to complex, but automation compresses the skill requirement. Mining software and scripts are standardized; collection is automated via pools.
The campaigns we see are industrial in scale. Over 1,700 attacking IPs from major cloud providers suggest large botnets or significant rented infrastructure. Upward trends show successful scaling. Shared infrastructure and tooling point to coordination or a robust community market for exploitation and deployment tools.
Computing power → cryptocurrency → monetary value. When that chain lines up with favorable market conditions, criminal actors respond rationally: they increase mining capacity and run it while the window is lucrative.
.png)
One day during my freshman year of college my brother called me in a panic. Our mother had found a few bottles of cheap liquor in the house, and his desperate plan was simple: I should say they were mine. I laughed and agreed - Ann Arbor was nearly four hours away and I was pretty sure my RA wasn’t going to be able to keep me in my room. A few hours later when my mother called her first question was: “Were the bottles I found yours?” In the spirit of brotherly camaraderie I confidently said “yes.”
These days I work at GreyNoise, where the stakes are a bit higher than vodka in the basement. We run a global network consisting of thousands of sensors in more than seventy countries. These sensors are designed to look very tempting to attackers: unpatched, exposed, and vulnerable. We believe the design is pretty good, since on an average day more than 600,000 different IPs complete hundreds of millions of sessions, with about half being attacks. It’s like we left our front door wide open and can watch who walked in.
Of course, the problem with leaving the door open is that sometimes an intruder can make themselves a bit too comfortable. Every now and then an attacker actually compromises one of our sensors and starts using it to do something malicious - scanning for targets, deploying malware, etc. We usually detect this and then automatically repair and restore the sensor long before any activity can occur. Occasionally, however, an attacker moves fast enough to briefly start their work. That’s when we get the notification:
Subject line: AWS Abuse Report.
Translation: Amazon is politely asking us to get our act together, and quickly.
When that happens, we don’t get defensive. We get to work, shutting down the sensor and figuring out how to better detect and remediate quickly. We never get upset that the sensor was compromised, however. After all, the whole point of GreyNoise is to ensure that no attack works twice; that means we have to be the ones attacked first. Every time a new exploit or attack technique hits our honeypots, we learn from it, detect it, and share information so that it won’t work again on anyone else.
Let me make an important point: AWS is a great partner to work with, and we’re grateful whenever they help us catch something we missed. We hope AWS never has to send us an abuse report — because ideally, we should catch a popped sensor before they do. That’s the goal. And when one does slip through the cracks, it’s a reminder that our job is working: we take the hits so you don’t have to.
We think we’re doing a good job of this, and hope you feel the same. Either way, we’re doing better than I did back then. I tried to be a decoy for my brother and took the heat — just not very well. At GreyNoise, being the decoy is the job, and we’re a lot better at it.
“That’s sweet of you to lie for your brother; he’s grounded, and we’ll talk about you next time you come home for break,” my mother said.
Turns out, taking the blame works best when it’s part of the plan.
.png)
When I decided to join GreyNoise, it wasn’t just about the role—it was about the mission. As a first-generation American and a veteran with 25 years of military service, I’ve spent my life focused on protecting others and finding clarity in complex environments. GreyNoise stands out because it approaches cybersecurity from an angle that few others do: cutting through the noise of the internet to identify real threats. In a world where cyber operators are overwhelmed by volumes of data, endless alerts, and meaningless traffic, GreyNoise delivers clarity. Its unique position—collecting and analyzing background internet noise—empowers security teams to focus on what truly matters, turning chaos into actionable intelligence.
What truly drew me in, though, was the company’s culture. At GreyNoise, there’s an unwavering focus on outcomes over ego. People here genuinely care about helping security teams operate with greater precision, reducing wasted effort and accelerating decision-making. That shared purpose creates an energy you can feel across the organization.
As both a father and husband, I value environments where people are supported as whole individuals, not just employees—and that’s exactly what GreyNoise embodies. After decades of service, I’ve learned that true impact comes from strong leadership and cohesive teamwork. Both are essential for success, whether in uniform or in cybersecurity. GreyNoise reflects those same principles—leaders who empower, teams who trust one another, and a collective drive to make a difference.
Joining GreyNoise means being part of something bigger than a job—it’s joining a mission-driven team that’s redefining how the world thinks about security data. It’s a mission I’m proud to stand behind, both as a professional and as someone who has dedicated his life to service, leadership, and purpose.

GreyNoise has observed steady deployments of previously unseen IPs attacking Microsoft RDP services through timing-based vulnerabilities. Attackers are rotating significant volumes of new IPs each day to target two primary vectors — RD Web Access timing attacks and RDP web client login enumeration — likely in an effort to evade detection and blocking.
Use GreyNoise Block to dynamically block all IPs engaged in this activity. On 10 October, GreyNoise partially linked this activity to a global botnet, publishing a blocking template named “Oct-2025 RDP Botnet Campaign.” Applying this template instantly neutralizes the threat actors’ IP rotation strategy.
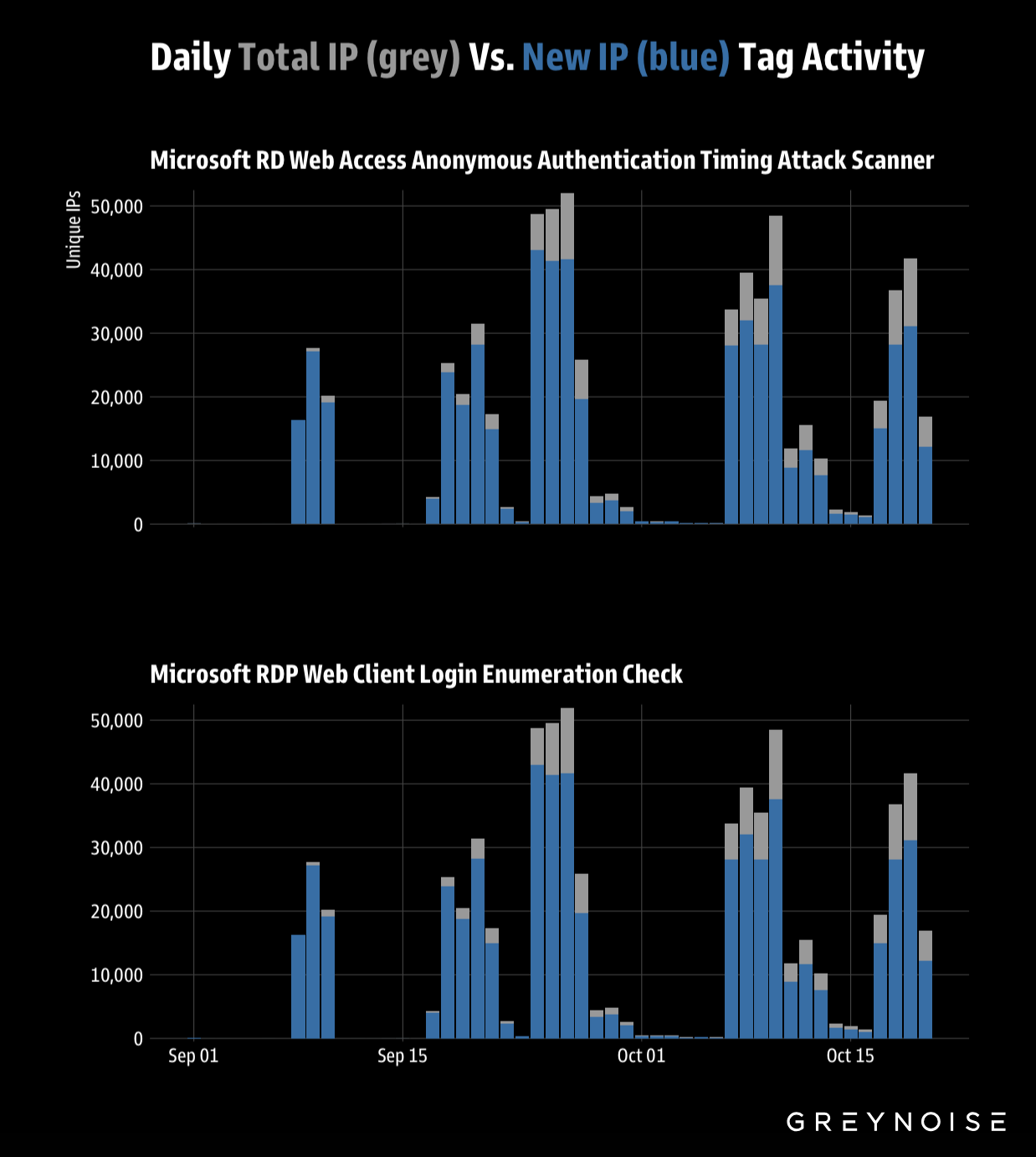
From September 2025 to present, we’ve observed a steady rise in the number of unique IPs targeting RDP — now exceeding 500,000.
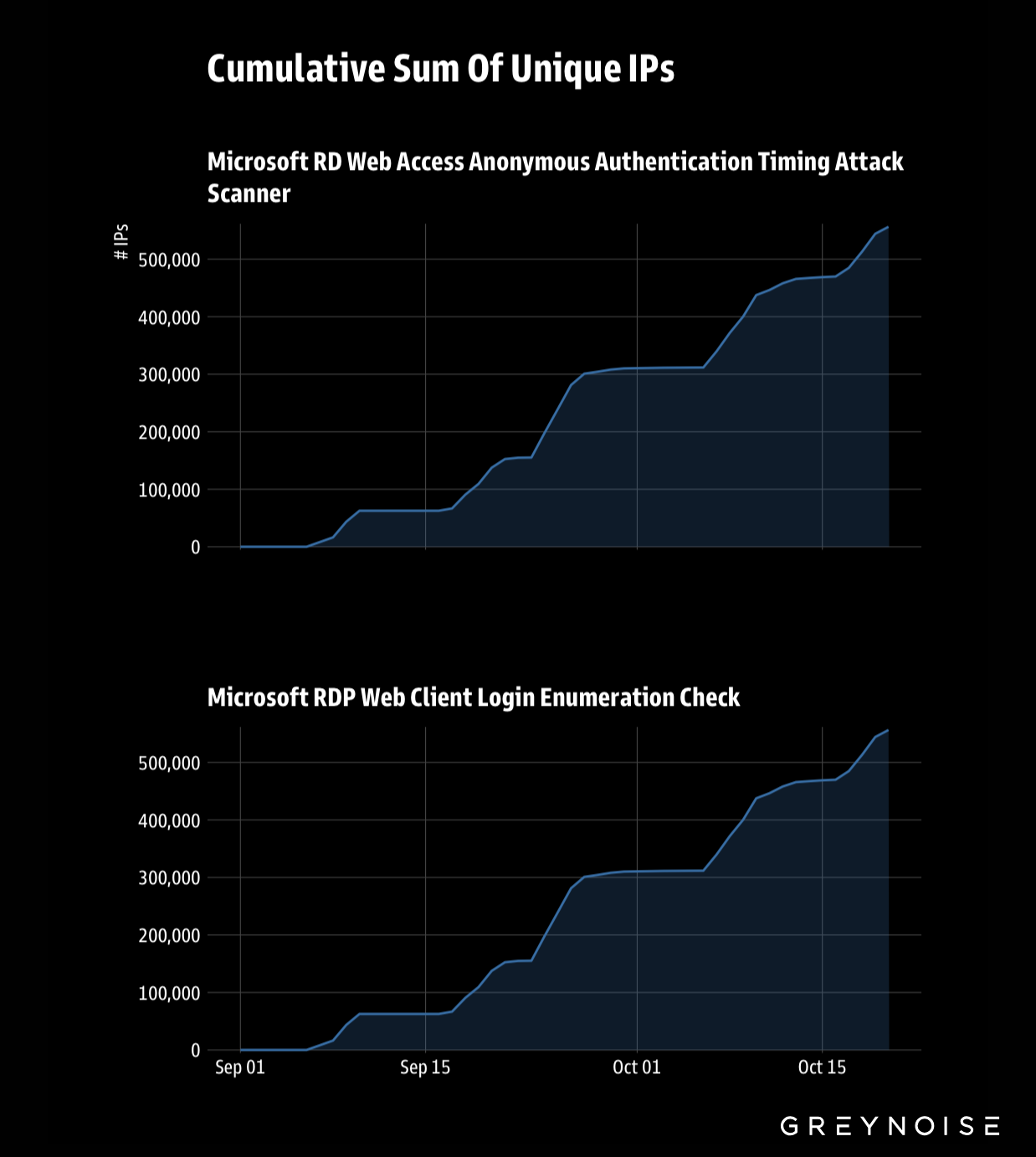
The top three source countries in the past 90 days are:
Nearly 100 percent of targeting has been directed at U.S.-based systems. Source and target patterns remain consistent with the botnet activity first identified on 10 October.
The rapid churn of new IPs underscores an emerging trend: threat actors are increasingly rotating infrastructure to evade static blocking and complicate attribution.
Use GreyNoise Block to dynamically block all IPs engaged in this activity. The “Oct-2025 RDP Botnet Campaign” template remains the most effective method for mitigation. Get started with a free 14-day trial.
GreyNoise will continue to monitor the situation and update this post as necessary.
— — —
This discovery was led by boB Rudis.
.png)
Amid the security incident involving F5 BIG-IP announced on 15 October 2025, GreyNoise is sharing recent insights into activity targeting BIG-IP to aid in defensive posturing. The below anomalies may not necessarily relate to the 15 October incident.
Search the GreyNoise Visualizer to see real-time activity against F5 technologies.
GreyNoise will continue monitoring the situation and make updates as necessary. Please email research@greynoise.io with any tips or feedback on this analysis.
.png)
Security teams already have access to blocklists; commercial feeds, community lists, vendor-curated sets of bad IPs — they’ve been around for decades. And yet, every practitioner has experienced the same frustrations: the lists are too noisy, too static, too opaque, too slow to update, or just not quite meeting the right criteria.
That’s why GreyNoise built Block, a blocklist approach designed to be highly configurable, grounded in primary-sourced intelligence, and updated in real-time as attacker behavior changes.
Most blocklists share common issues:
As a result, network security teams struggle to balance security and availability, concerned that they’ll block legitimate traffic or fail to block malicious traffic.
GreyNoise approaches blocklists from a different angle:
GreyNoise Block delivers practical benefits to cybersecurity teams:
Creating blocklists within GreyNoise Block could not be easier. To optimize flexibility, each blocklist is associated with a GNQL query. For ease of use, GreyNoise includes a set of query templates that provide pre-built blocklists. Start by either selecting a pre-built template or writing a query from scratch.
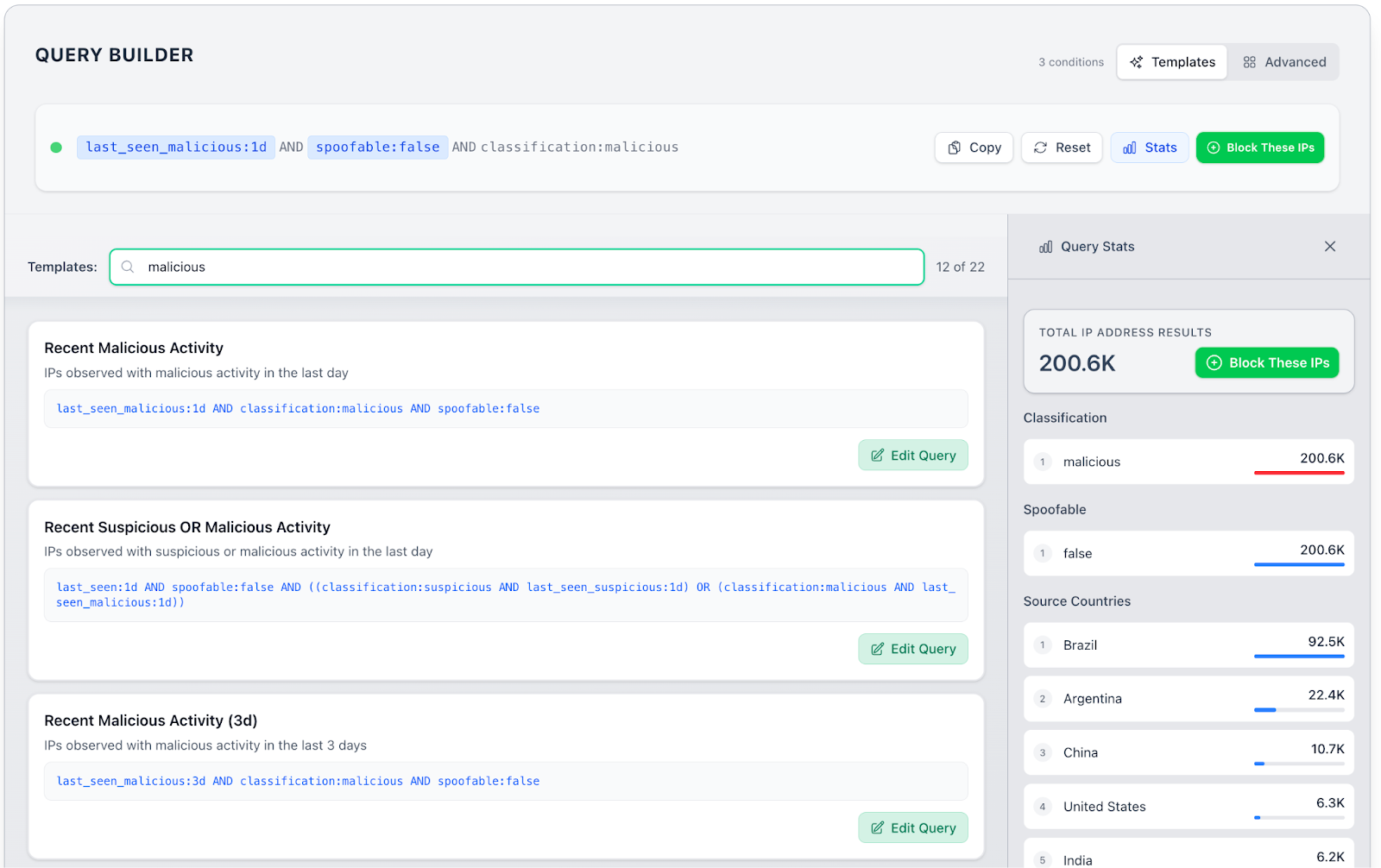
When selecting a template, you can click “Block These IPs” to create a blocklist immediately or click “Edit Query” to refine the blocklist’s criteria even further. When editing the query, you can add, remove, or modify fields and group them logically through and/or clauses. As you modify fields, the Query Stats panel on the right updates automatically.
Once you have the query looking as you want it in the Query Builder, click the “Block These IPs” button to turn the query into a blocklist.
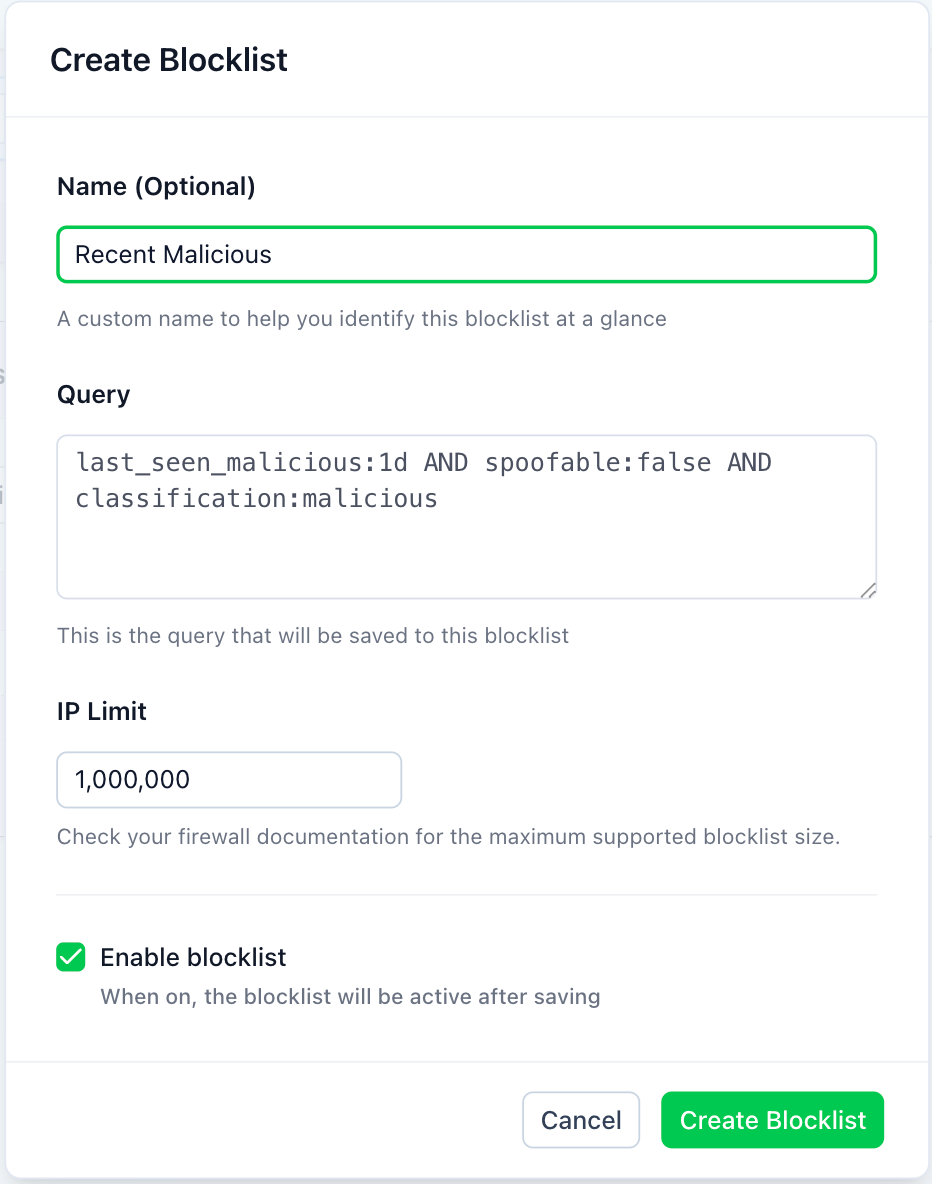
In the Create Blocklist dialog box, give the query a name and assign it an IP limit, which might be necessary if your firewall has a maximum supported size.

Once the block list is created, click the My Blocklists link at the top of the page to view the new block list and any others you have created. From the list, you can copy the blocklist URL to your firewall.
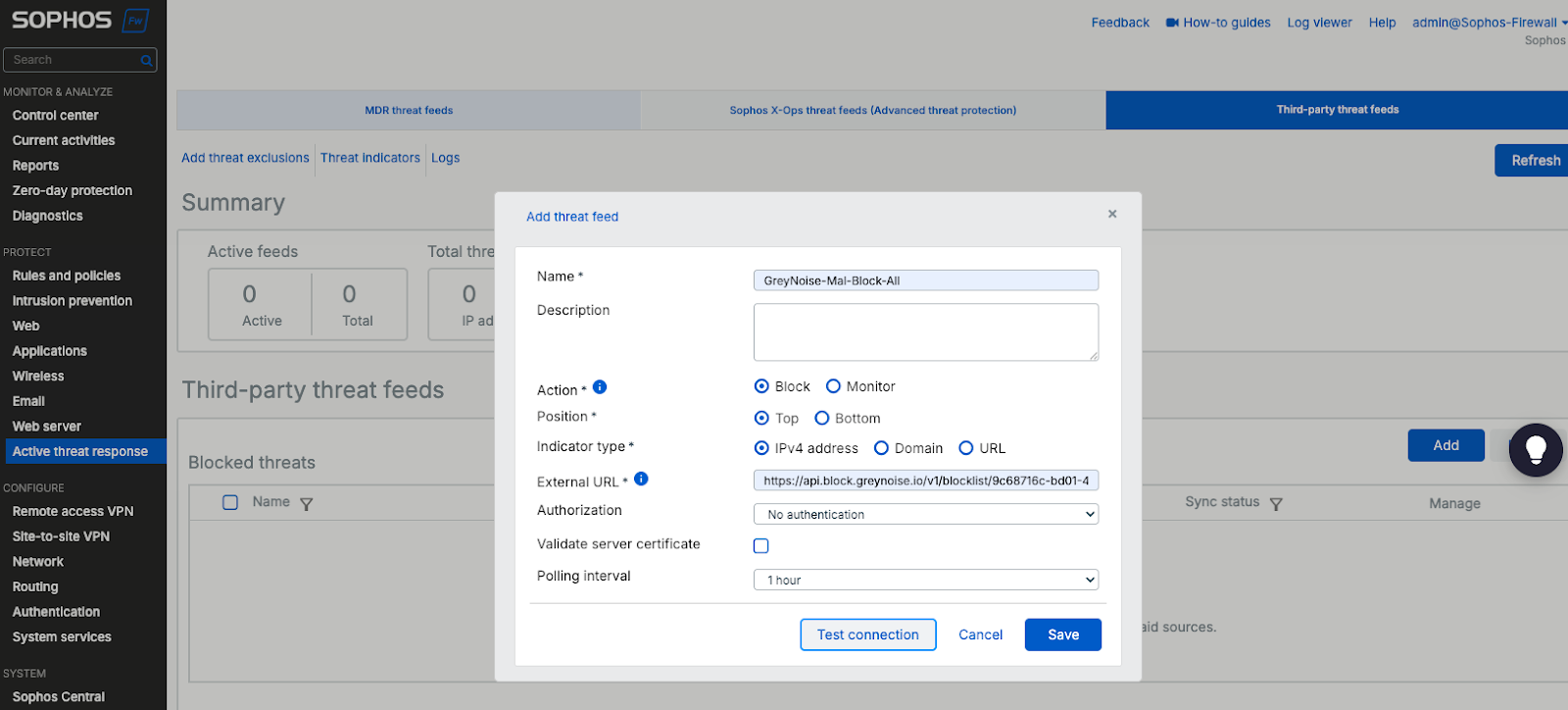
That’s all there is to it. Your firewall will periodically poll the blocklist URL and keep that bad traffic out of your network.
GreyNoise Block is available now with a free trial for 14 days.
.png)
GreyNoise is sharing an Executive Situation Report (SITREP) for this event, providing leadership with actionable judgments and evidence to support decision making.
In a significant escalation, the botnet has grown to ~300,000 IPs — more than tripling in size. The threat actor(s) continues its focus on RDP infrastructure in the United States, leveraging IPs from Brazil, Argentina, Singapore, and other countries.
The associated threat actor(s) is rapidly activating new botnet nodes to target U.S. RDP infrastructure. Therefore, static defense measures will not be effective at mitigating this threat.
Since October 8, 2025, GreyNoise has tracked a coordinated botnet operation involving over 100,000 unique IP addresses from more than 100 countries targeting Remote Desktop Protocol (RDP) services in the United States. The campaign employs two specific attack vectors — RD Web Access timing attacks and RDP web client login enumeration — with most participating IPs sharing one similar TCP fingerprint, indicating centralized control.
Use GreyNoise Block to dynamically block all IPs engaged in this activity. New users can try GreyNoise Block free for 14-days.
The botnet was discovered after GreyNoise detected an unusual spike in Brazilian IP space this week, which prompted investigation into broader traffic patterns.
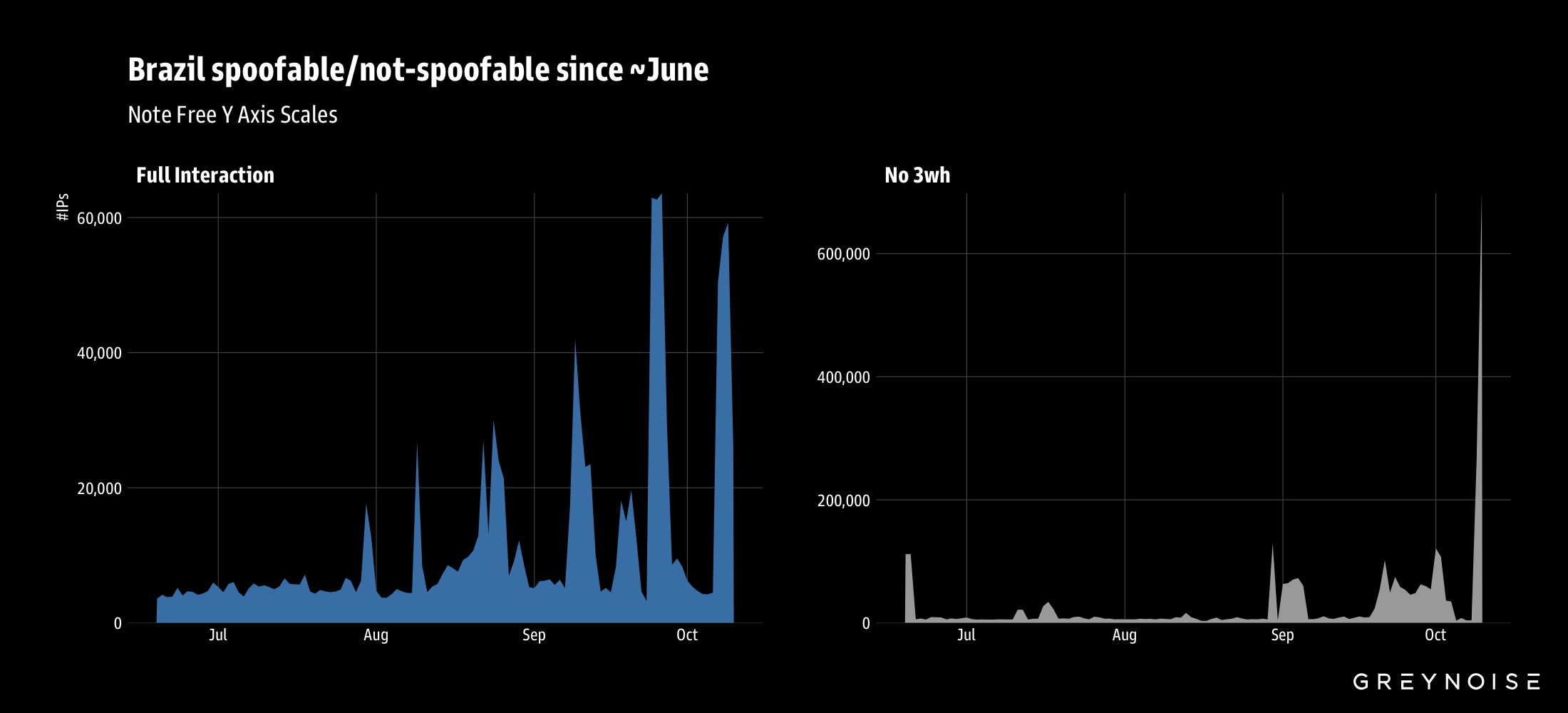
Note: Full interaction = completed three-way handshake; No 3wh = no three-way handshake
Broadening our analysis, we observed additional surges in activity across many source countries since the beginning of October.
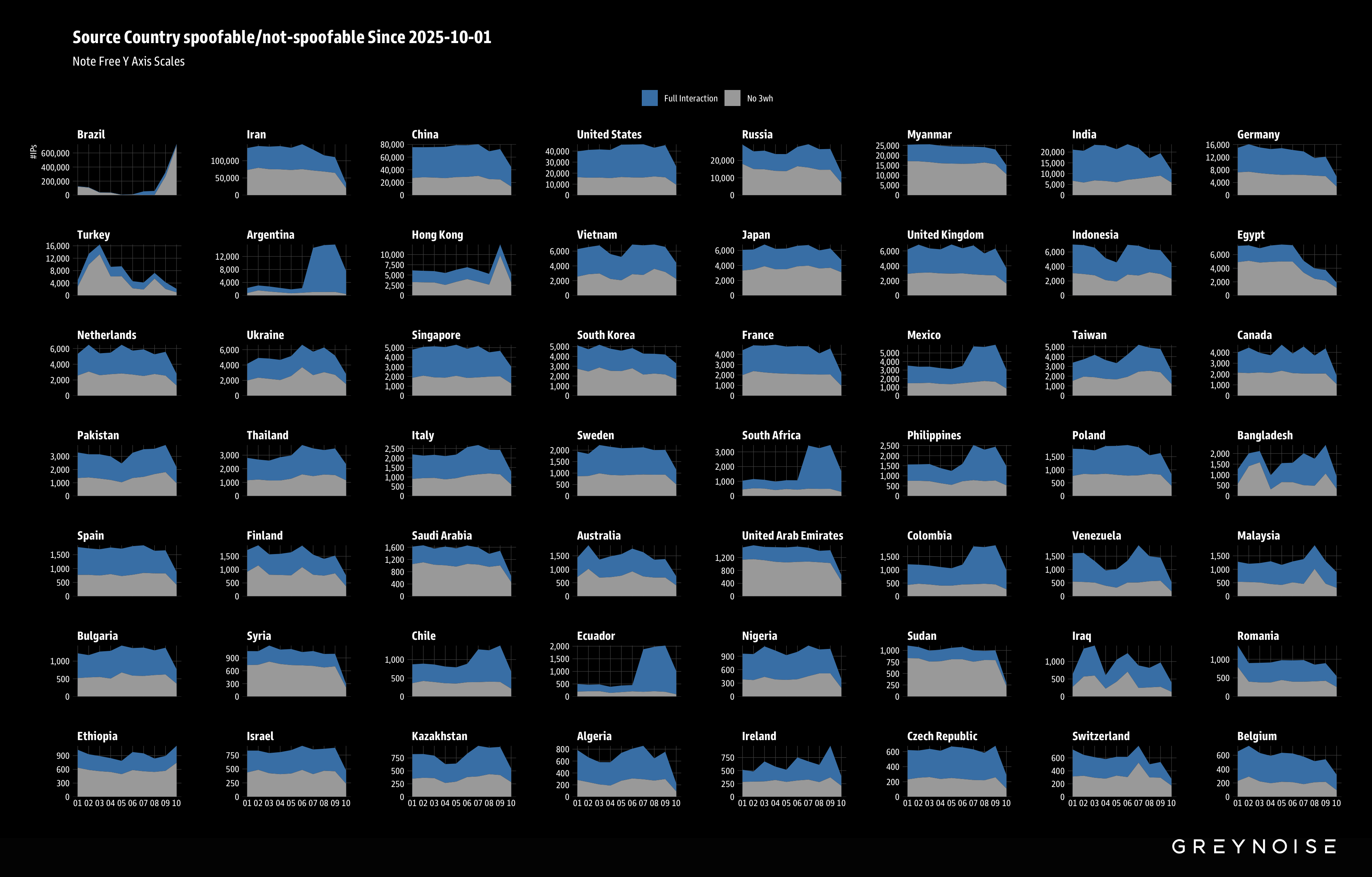
Pivoting from these findings, we then discovered a repeated pattern in RDP targeting — originating from many countries, sharing a similar client fingerprint, and all targeting US RDP infrastructure.

Several factors suggest this activity is originating from one botnet:
GreyNoise will continue monitoring the situation and provide updates here as necessary.
---
This discovery was led by boB Rudis with contributions from the broader GreyNoise team.

Time is critical in incident response. The gap between exploit disclosure and patching, between compromise and containment, or between detection and recovery often determines the difference between a near miss and a major breach. Attackers automate everything from recon to exploit creation. Defenders need to close the speed gap.
Most threat intelligence workflows still rely on polling. Analysts or automated systems query APIs or dashboards on fixed schedules—every few minutes, every hour, sometimes even less frequently. By the time new data is pulled in, attackers may have already rotated infrastructure, moved laterally, or pivoted to a new exploit. This delay undermines automation investments, keeping defenders stuck in reaction mode.
GreyNoise Feeds eliminate the need for polling by delivering event-driven webhook-based push notifications the moment something changes. Instead of waiting for the next scheduled query, your automation receives the update as soon as GreyNoise sees it. Teams can subscribe to three types of events:
GreyNoise Feeds are designed to be wired directly into automation platforms like SIEMs and SOARs. With feeds in place, teams can:
GreyNoise Feeds are quite easy to configure. Give the Feed a name, specify the type, that is whether IP classification change, CVE status change, or CVE activity spike, indicate the direction of the change (such as from unknown to malicious), and specify whether to notify on all IP addresses and CVEs or a select subset.
You will also need to configure where GreyNoise should deliver the notifications, and each feed can have a unique delivery address. The address is a url that has been configured to receive webhook feeds. In order to support authentication and other features, GreyNoise Feeds supports adding custom HTTP headers.

GreyNoise Feeds take intelligence out of batch mode. Instead of asking what changed after the fact, your systems can respond the moment GreyNoise sees new exploitation, malicious activity, or infrastructure shifts. For defenders racing against automated attackers, that time advantage matters.
Learn more and watch videos on how to use at GreyNoise docs.
.png)
GreyNoise has identified several links between three recent campaigns:
We assess with high confidence that all three campaigns are at least partially driven by the same threat actor(s), evidenced by:
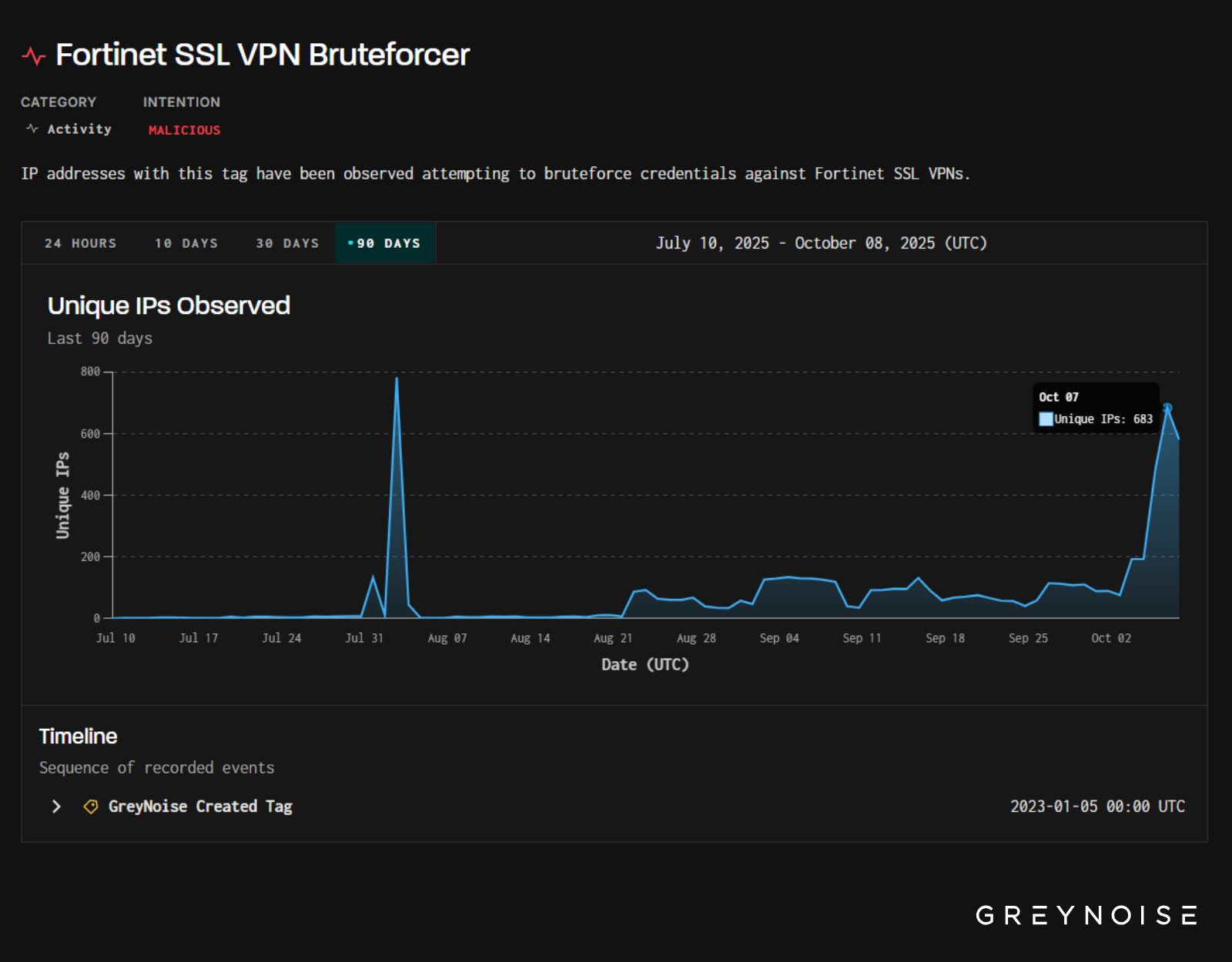
In addition to continued escalation of login attempts against Palo login portals, GreyNoise has identified likely related and coordinated credential brute forcing against Fortinet SSL VPNs. We are providing lists of credentials used in both campaigns:
All three campaigns — Cisco ASA scanning, Palo login attempts, and Fortinet VPN brute forcing — heavily rely on the same subnets:
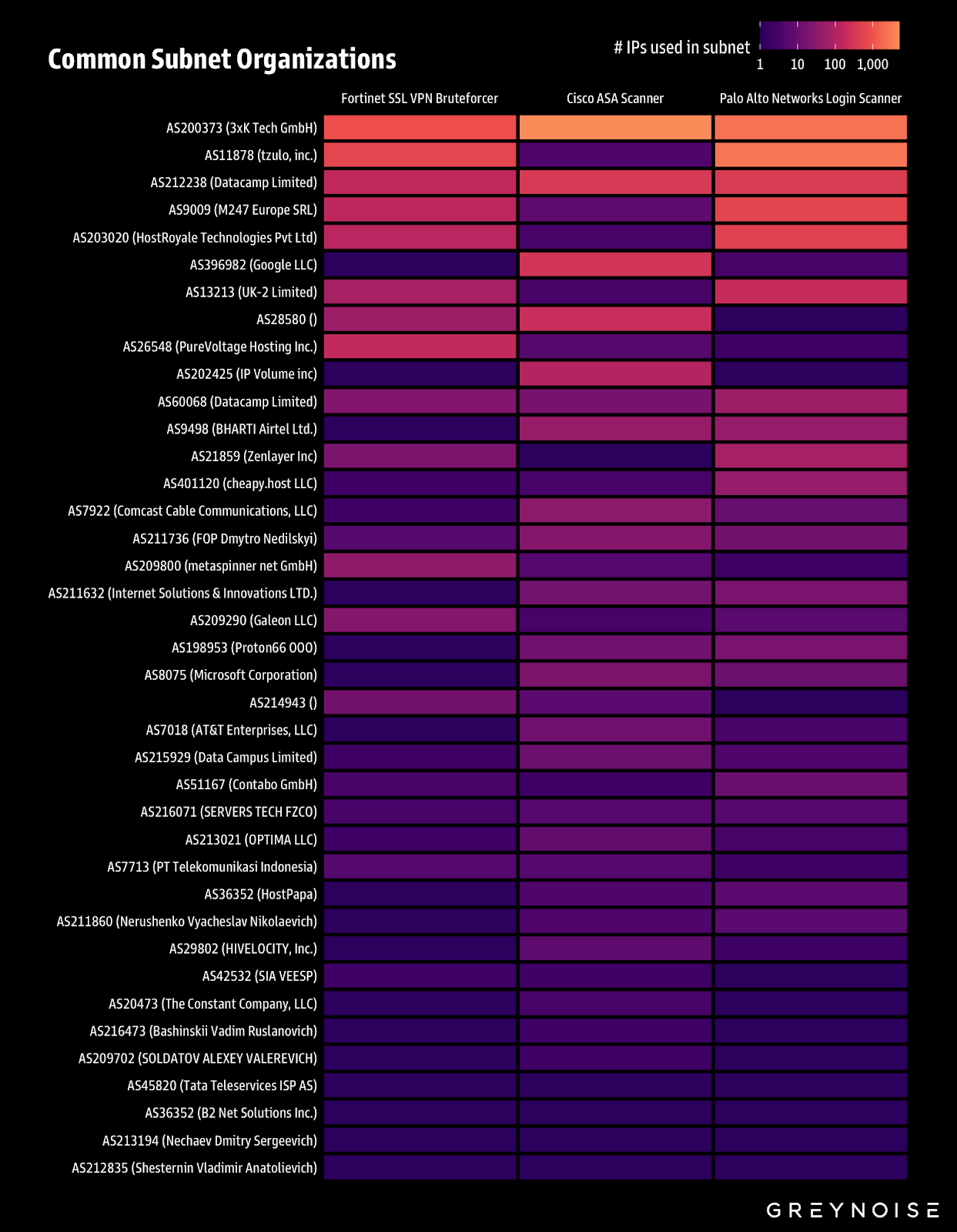
Use GreyNoise Block to directly block threat IPs from all relevant GreyNoise tags (ASA Scanner, Fortinet VPN Bruteforcer, Palo Scanner) and the below ASNs:
Defenders can use GreyNoise Block to craft custom blocklists, instantly mitigating risk at the perimeter.
In July, GreyNoise research identified a significant correlation:
Spikes in Fortinet VPN brute force attempts are typically followed by Fortinet VPN vulnerabilities disclosures within six weeks.
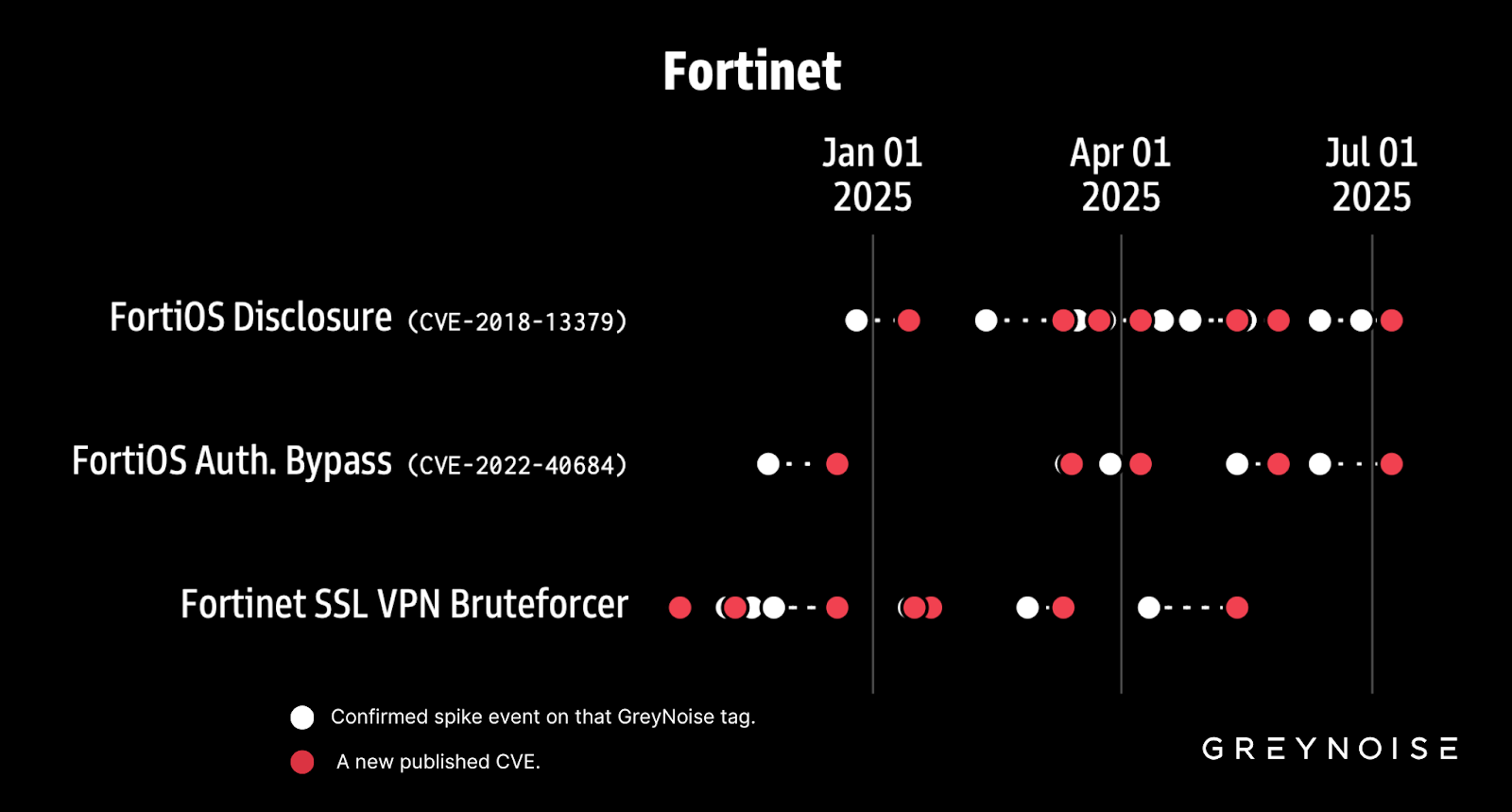
Block all IPs brute forcing Fortinet SSL VPNs, and consider hardening defenses for firewall and VPN appliances amid these findings.
For defender review, GreyNoise has published a list of all unique usernames and passwords from Palo login attempts observed in the last week.
GreyNoise has produced an Executive Situation Report (SITREP) on the situation, intended for decision makers.
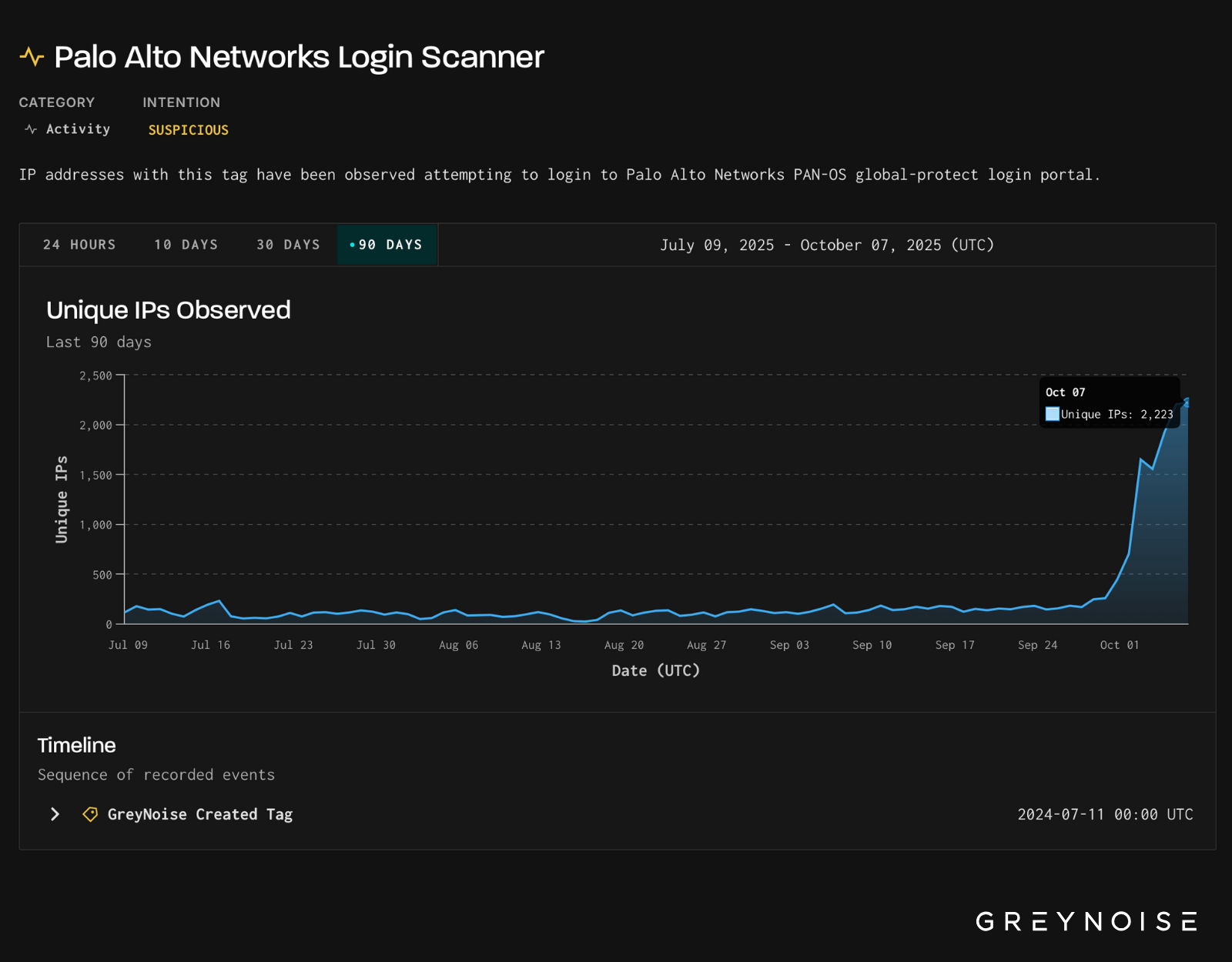
In the past days, GreyNoise has observed an escalation in scanning against Palo Alto Networks PAN-OS GlobalProtect login portals. Since our original reporting of ~1,300 IPs in the afternoon of 3 October, we have observed a sharp rise in the daily number of unique IPs scanning for Palo login portals. Peaking today on 7 October, over 2,200 unique IPs scanned for Palo login portals.
In addition to an increase in the number of IPs involved, GreyNoise has observed a sharp increase in the unique count of ASNs involved in scanning Palo login portals, suggesting an increase in the number of threat actors involved.
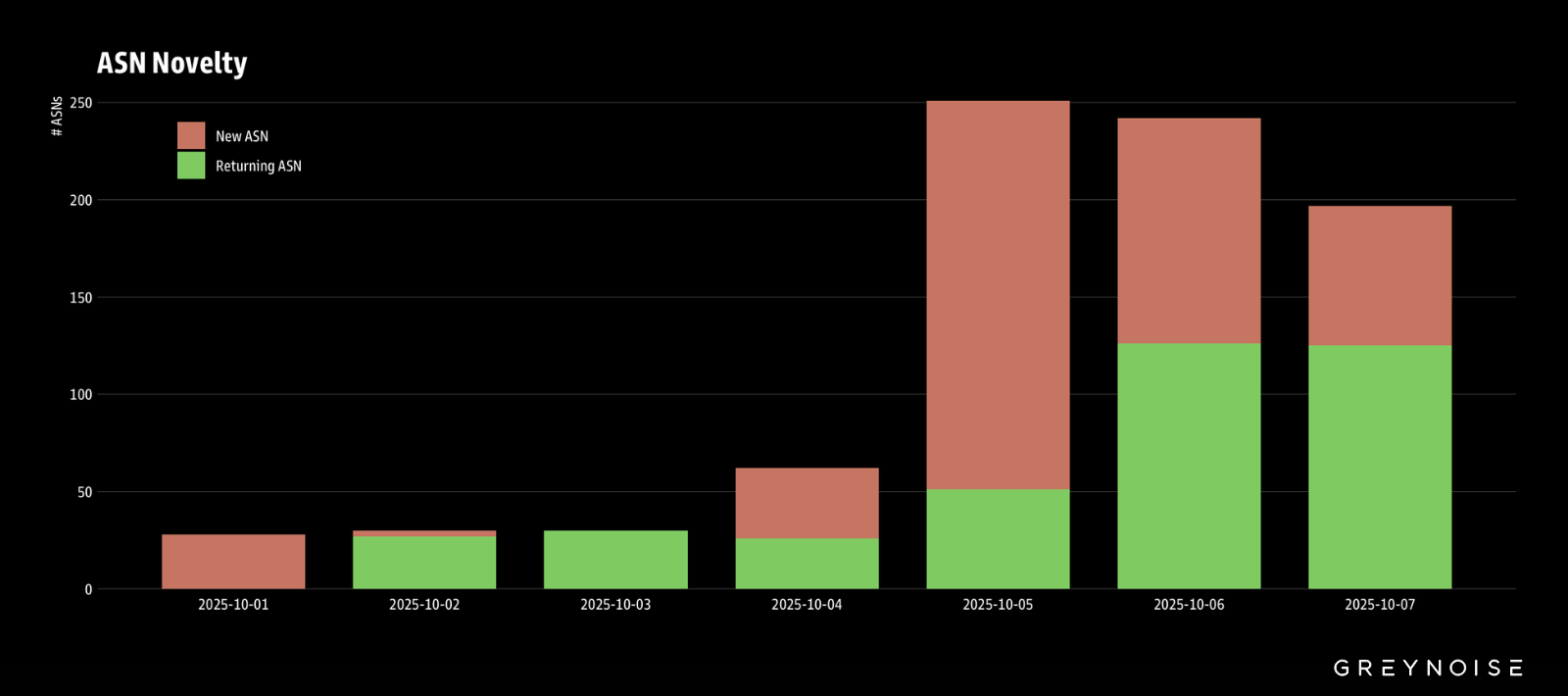
Separately, we discovered that approximately 12 percent of all ASN11878 subnets are allocated to scanning Palo login portals.
The pace of login attempts suggests elevated activity may be driven by a threat actor(s) iterating through a large dataset of credentials.
.png)
On October 3, 2025, GreyNoise observed a ~500% increase in IPs scanning Palo Alto Networks login portals, the highest level recorded in the past 90 days.
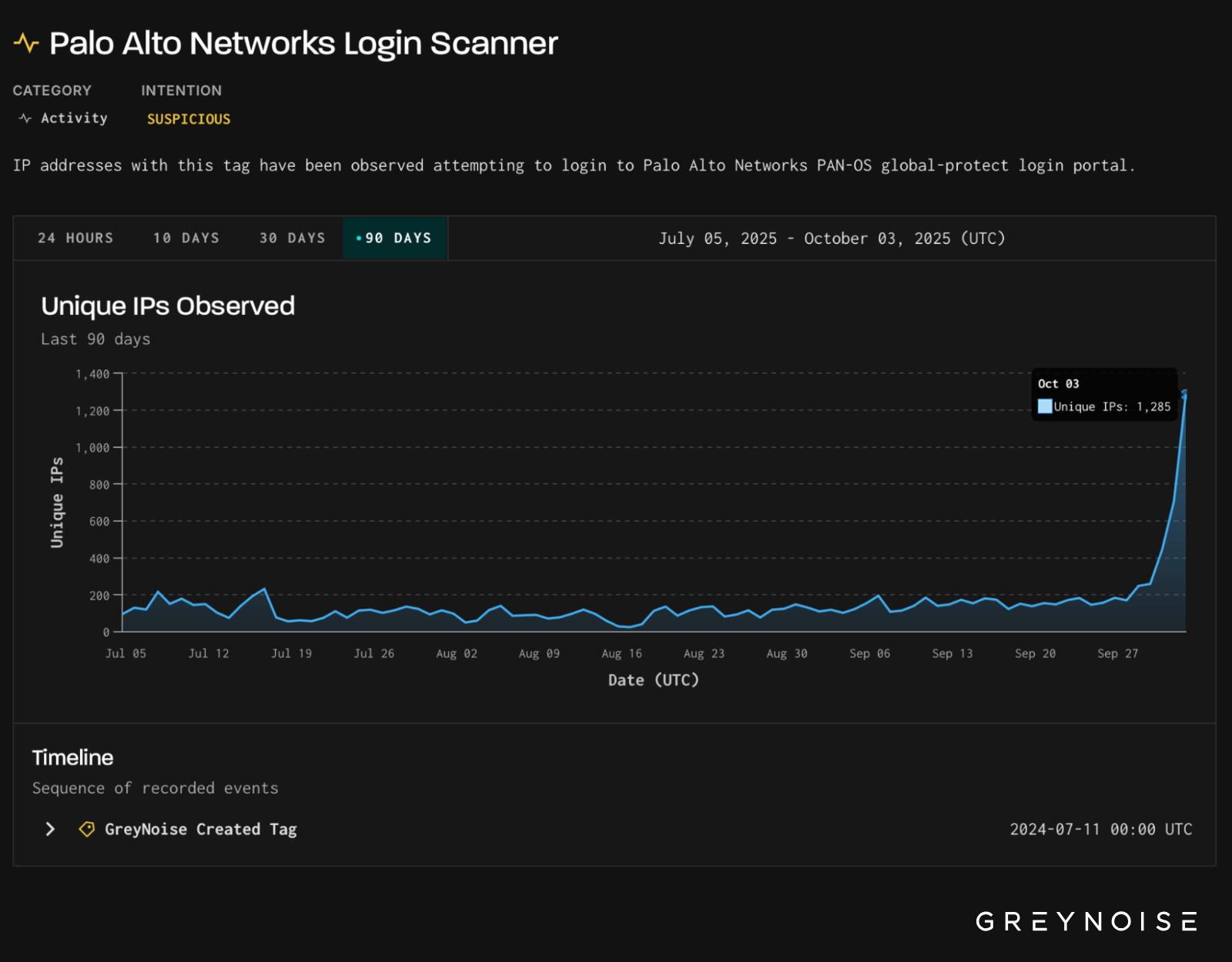
GreyNoise research in July found that surges in activity against Palo Alto technologies have, in some cases, been followed by new vulnerability disclosures within six weeks (see chart below). However, surges against GreyNoise’s Palo Alto Networks Login Scanner tag have not shown this correlation. GreyNoise will continue monitoring in case this activity precedes a new Palo Alto disclosure, which would represent an additive signal to our July research.
GreyNoise analysis shows that this Palo Alto surge shares characteristics with Cisco ASA scanning occurring in the past 48 hours. In both cases, the scanners exhibited regional clustering and fingerprinting overlap in the tooling used. Both Cisco ASA and Palo Alto login scanning traffic in the past 48 hours share a dominant TCP fingerprint tied to infrastructure in the Netherlands. This comes after GreyNoise initially reported an ASA scanning surge before Cisco’s disclosure of two ASA zero-days.
These similarities indicate the activity may be related through shared tooling or centrally managed infrastructure, but GreyNoise cannot confirm whether it was carried out by the same operators or with the same intent.
In addition to a possible connection to ongoing Cisco ASA scanning, GreyNoise identified concurrent surges across remote access services. While suspicious, we are unsure if this activity is related.
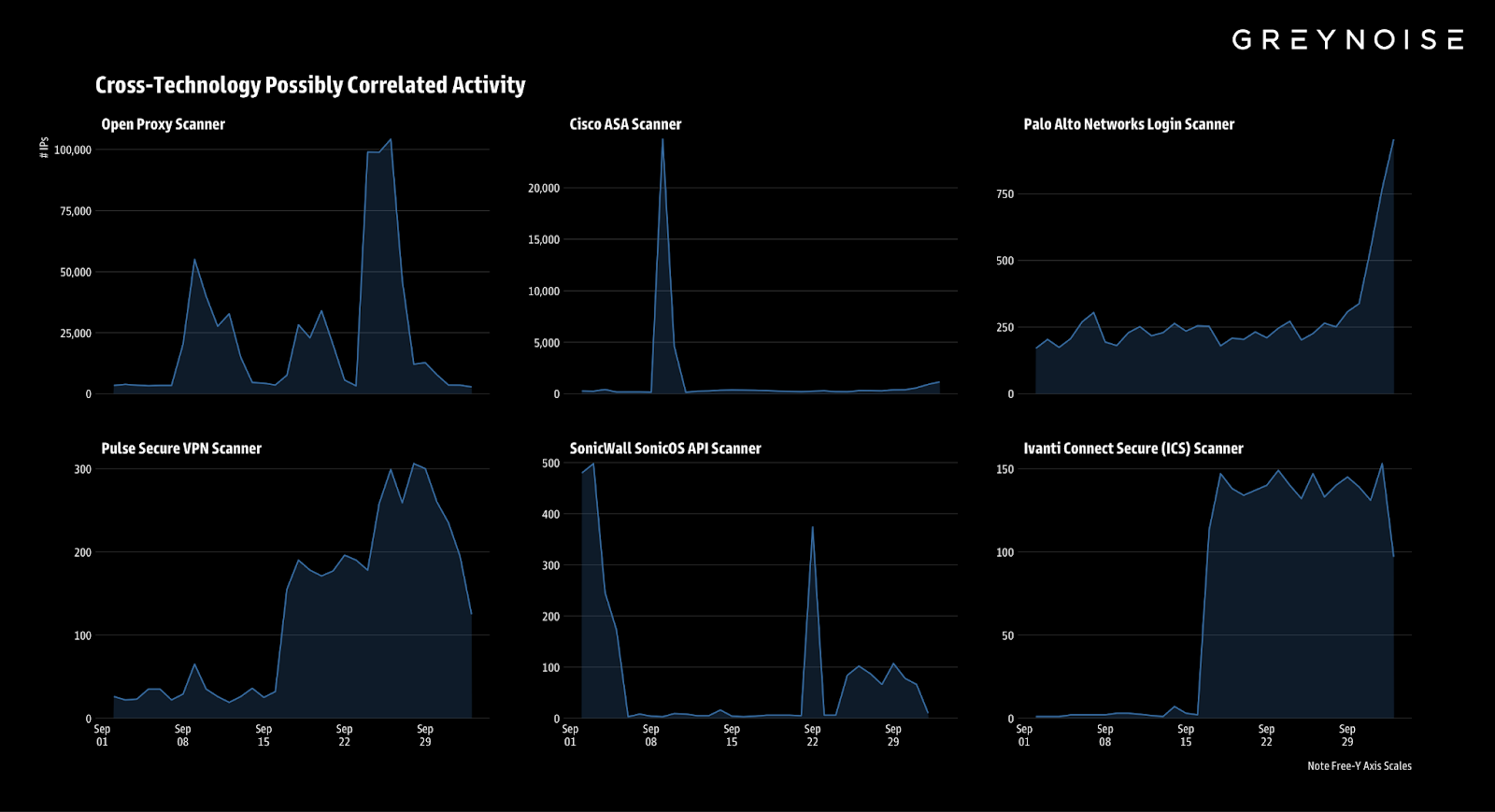
These factors distinguish the surge from background noise and mark it as a clear reconnaissance event. GreyNoise will continue monitoring for potential follow-on exploitation attempts.
GreyNoise has developed an enhanced dynamic IP blocklist to help defenders take faster action on emerging threats. Click here to learn more about GreyNoise Block.
— — —
This research and discovery was a collaborative effort between boB Rudis and Noah Stone, with additional contributions from Towne Besel.
.png)
For executive audiences, please see the accompanying Situation Report (SITREP) for this activity.
On 28 September 2025, GreyNoise observed a sharp one-day surge of exploitation attempts targeting CVE-2021-43798 — a Grafana path traversal vulnerability that enables arbitrary file reads. Over the course of the day, 110 unique IPs attempted exploitation against GreyNoise’s Global Observation Grid (GOG). All 110 IPs are classified as malicious.
Grafana exploitation had been largely quiet in recent months. On 28 September, activity spiked sharply:
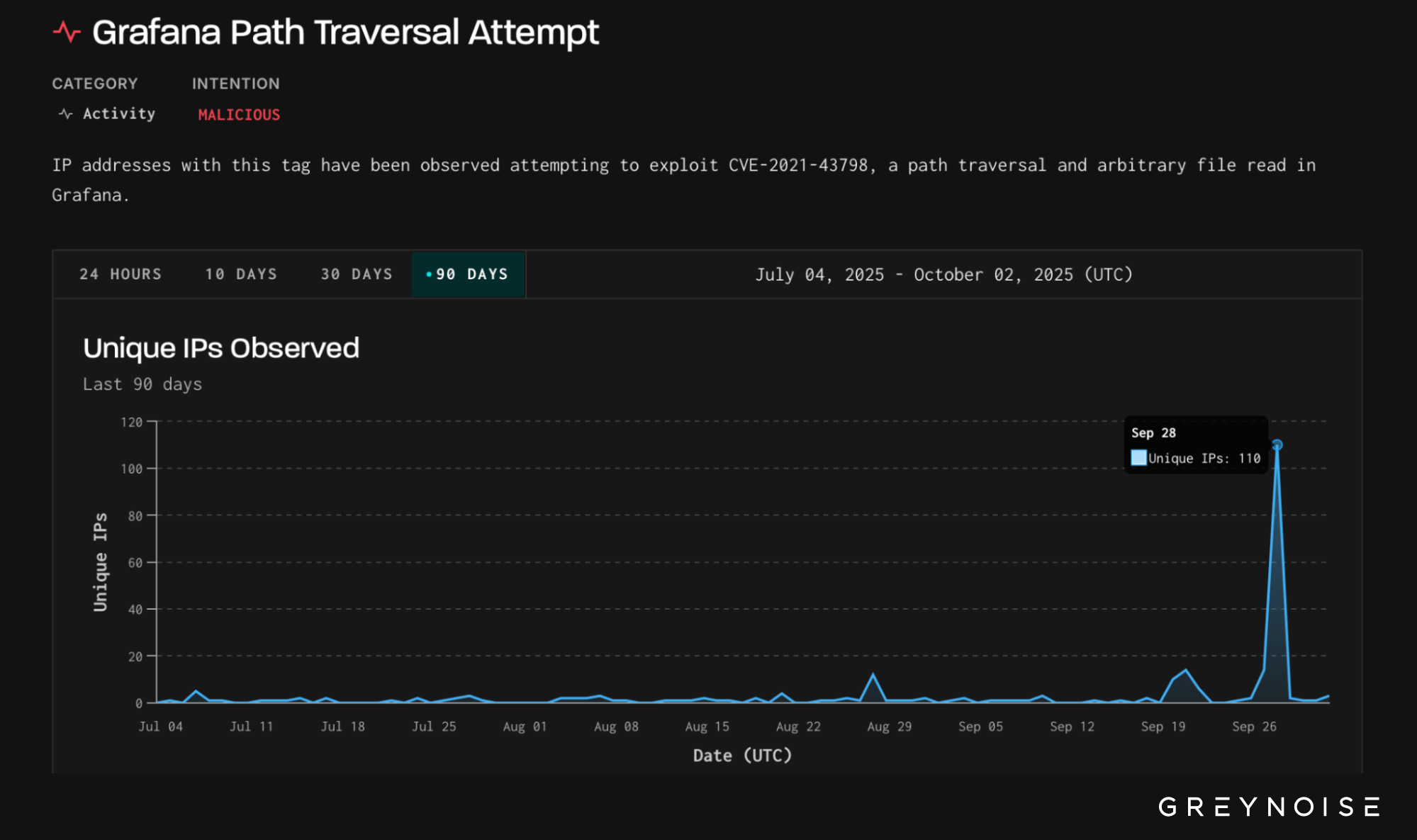
Two elements stand out in the data:
The alignment across both geography and tooling suggests shared tasking or a common target list, not uncoordinated traffic.
Two IPs geolocated to China are worth highlighting:
Both belong to CHINANET-BACKBONE, were first observed on 28 September, active only that day, and overwhelmingly focused on Grafana.
Exploitation of older, high-impact vulnerabilities like CVE-2021-43798 is common across different threat categories:
This activity reflects a coordinated push against a known, older vulnerability. The uniform targeting pattern across source countries and tooling indicates common tasking or shared exploit use. GreyNoise does not attribute this to a specific threat actor, but the convergence suggests either one operator leveraging diverse infrastructure or multiple operators reusing the same exploit kit and target set.
We anticipate old vulnerabilities — like CVE-2021-43798, and even older ones — will continue resurging in the future. Read GreyNoise’s research from earlier this year to learn more about the patterns and behaviors resurgent vulnerabilities tend to exhibit, and how defenders can stay ahead.
Please contact your GreyNoise support team if you are interested in the JA4+ signatures in this investigation.
GreyNoise has developed an enhanced dynamic IP blocklist to help defenders take faster action on emerging threats. Click here to learn more about GreyNoise Block.
— — —
This research and discovery was a collaborative effort between Glenn Thorpe, Noah Stone, Towne Besel, and boB Rudis.
.png)
While we may not know when the agentic SOC will arrive, we do know it will need timely and accurate intelligence to make good decisions. To provide that intel, we’re making the GreyNoise MCP Server available today, enabling easy integration of GreyNoise intel by Model Context Protocol (MCP) compatible AI agents.
When an AI agent sees an IP address or CVE in a workflow, it can query GreyNoise in real time and learn:
This grounding mitigates the risk of hallucinations and prevents agents from treating every alert equally, enabling more realistic, risk-based automation.
With GreyNoise data inside the reasoning loop, agents can handle several critical tasks more effectively:
SOC teams already use GreyNoise to separate background scanning from true threats. What changes with the MCP Server is that the same logic is now available directly to AI agents.
This combination makes GreyNoise data especially well-suited to agentic SOC environments, where decisions need to be fast but also defensible.
Let’s say your manager wants an intelligence report, perhaps regarding an external threat, a set of IP addresses, or a vulnerability. For example, I may need to create a report based on a CVE, so I open Claude with the GreyNoise MCP server installed and enter the prompt:

Notice how Claude is making several calls to the GreyNoise MCP server as well as other sources so that it can combine these sources into a report.

Because of the GreyNoise MCP, the report includes details about IP address counts and recent surges in activity. Adding more to the prompt, such as “Tell me about the source geography of the attacks”, causes Claude to generate a much more detailed report. With minimal effort, you can write a prompt that creates just the report that you need. You can even ask for vendor risk reports and threat hunting plans. It’s a great way to reliably use AI to lighten your workload.
Agentic SOCs are still an emerging concept, but the risks can be mitigated and the value better realized if AI agents make decisions grounded in trustworthy data. The GreyNoise MCP Server provides a way to embed that grounding directly into agentic workflows.
For security teams, this doesn’t mean replacing analysts—it means giving agents access to the same noise-filtering and exploitation-awareness that practitioners already rely on, so that automation can act responsibly at scale.
Indeed, analysts can make great use of the MCP just by interacting with an LLM application that supports MCP, such as Claude. Conduct research. Look into trends. Generate reports. It’s as easy as it is fun.
Find everything you need to know in the GreyNoise MCP Server docs.

GreyNoise identified a connection between three campaigns targeting Cisco, Palo Alto, and Fortinet firewalls and VPNs. We observed infrastructure overlap between recent Cisco ASA scanning, Palo login attempts, and Fortinet brute force attempts:
See the full update here.
GreyNoise has produced an Executive Situation Report (SITREP) on the situation, intended for decision makers.
Yesterday, Cisco announced two zero-day vulnerabilities affecting their Adaptive Security Appliance (ASA) and Firepower Threat Defense (FTD) platforms. These disclosures come just weeks after GreyNoise reported a surge in scanning activity against Cisco ASA devices (see initial reporting below). The timing is notable because recent research found that spikes in attacker activity against a specific technology (white dots) may serve as an early warning signal for future vulnerability disclosures affecting that same technology (red dots).
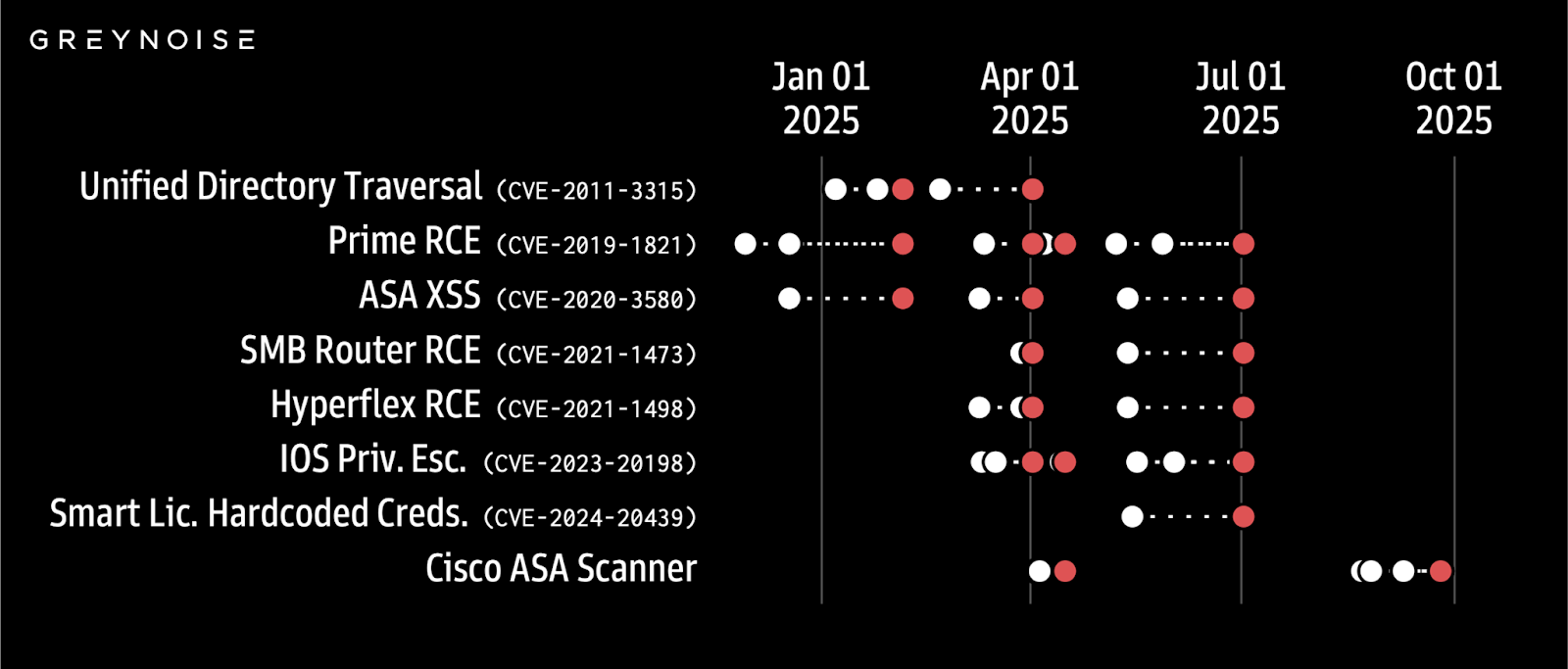
GreyNoise’s detection of 25,000 IPs scanning Cisco ASA in the weeks leading up to two zero day disclosures is a clear example of this research turning into reality:
“This is a real signal we’re seeing in our data across enterprise edge tech,” said boB Rudis, VP of Data Science and Security Research at GreyNoise. “We see elevated attacker activity against XYZ tech and then weeks later, new CVEs are disclosed affecting XYZ tech. This has repeatedly happened across enterprise edge, with Cisco ASA being the most recent example. So, yes, we’re very excited to learn our data may serve as an early warning signal for future vulnerability disclosures and we hope defenders will use this information to make the world a little safer.”
CISA issued an Emergency Directive (ED 25-03), requiring federal agencies to apply mitigations within 24 hours — representing the third-ever emergency directive since the agency’s founding. Both vulnerabilities, tracked as CVE-2025-20333 and CVE-2025-20362, have been added to CISA’s Known Exploited Vulnerabilities (KEV) catalog.
After investigating activity against our Cisco profiles, GreyNoise identified resurgent brute force attacks targeting Cisco SSL VPNs occurring yesterday at approximately 1:00pm EST. This activity was preceded by a period of inactivity, ceasing on September 24 at 6PM EST and restarting yesterday. All traffic during this period shares the same client fingerprint and source organization (Global Connectivity Solutions LLP), along with other shared characteristics:
CISA has issued guidance and mitigation instructions related to CVE-2025-20333 and CVE-2025-20362. We encourage defenders to review CISA’s official resources and apply recommended actions.
GreyNoise will continue monitoring its Cisco profiles for anomalous behavior, and will provide updates here as necessary.
---
GreyNoise observed two scanning surges against Cisco Adaptive Security Appliance (ASA) devices in late August. The first involved more than 25,000 unique IPs in a single burst; the second, smaller but related, followed days later. This activity represents a significant elevation above baseline, typically registering at less than 500 IPs per day.
Both events targeted the ASA web login path (/+CSCOE+/logon.html), a common reconnaissance marker for exposed devices. Subsets of the same IPs also probed GreyNoise’s Cisco Telnet/SSH and ASA software personas, signaling a Cisco-focused campaign rather than purely opportunistic scanning.
.png)
In the past 90 days, GreyNoise has observed traffic triggering its Cisco ASA Scanner tag originating from and targeting the following countries:
Note: Target country percent sum may exceed 100% due to one source IP targeting several IPs based in different countries.
Analysis of the August 26 wave shows that it was driven primarily by a single botnet cluster concentrated in Brazil. By isolating a specific client fingerprint, and reviewing two months of activity, GreyNoise determined that this fingerprint was used exclusively to scan for Cisco ASA devices.
On August 26:
The client signature was seen alongside a suite of closely related TCP signatures, suggesting all nodes share a common stack and tooling. This makes the August 26 spike attributable to a coordinated botnet campaign dominated by Brazil-sourced infrastructure.
GreyNoise’s Early Warning Signals research shows that scanning spikes often precede disclosure of new CVEs. In past cases, activity against GreyNoise’s Cisco ASA Scanner tag surged shortly before a new ASA vulnerability was disclosed (see last row in chart below). The late-August spikes may represent a similar early warning signal.
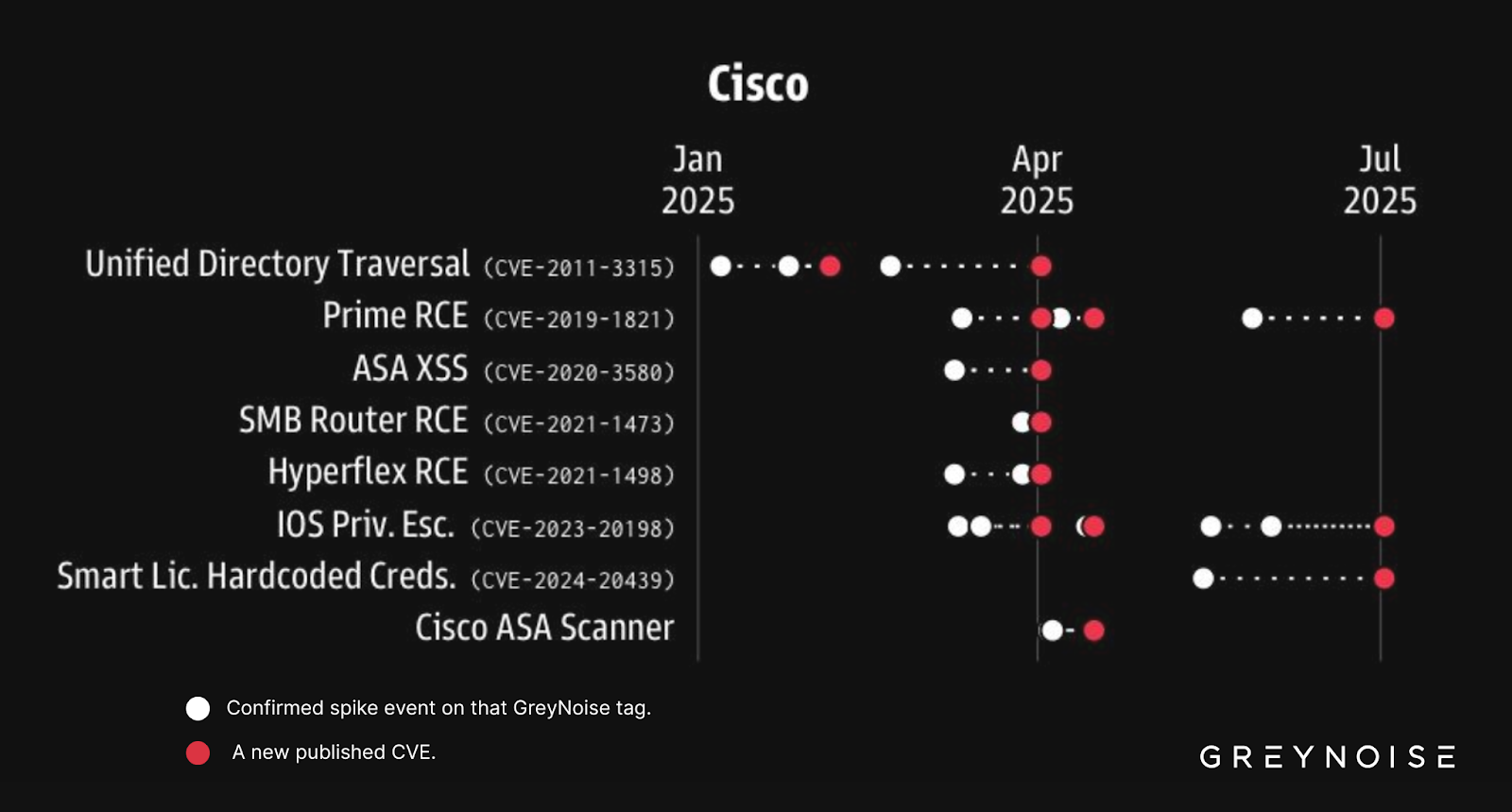
Even if organizations are fully patched, blocking these IPs now may reduce the likelihood of appearing on target lists used to exploit new CVEs in the future.
Monitor GreyNoise’s Cisco ASA tags for real-time scanning and exploitation activity:
GreyNoise will continue monitoring the situation and update this blog as necessary. Concentrated reconnaissance bursts, such as those in August, should be treated as potential early indicators of future vulnerability disclosures.
Please contact your GreyNoise support team if you are interested in the JA4+ signatures in this investigation.
GreyNoise has developed an enhanced dynamic IP blocklist to help defenders take faster action on emerging threats. Click here to learn more about GreyNoise Block.
— — —
This research and discovery was a collaborative effort between Towne Besel and Noah Stone.

Hours after publishing this blog, GreyNoise identified a much larger wave: on August 24, over 30,000 unique IPs simultaneously triggered both Microsoft RD Web Access and Microsoft RDP Web Client tags, largely from the same client signature behind the August 21 spike we reported below.
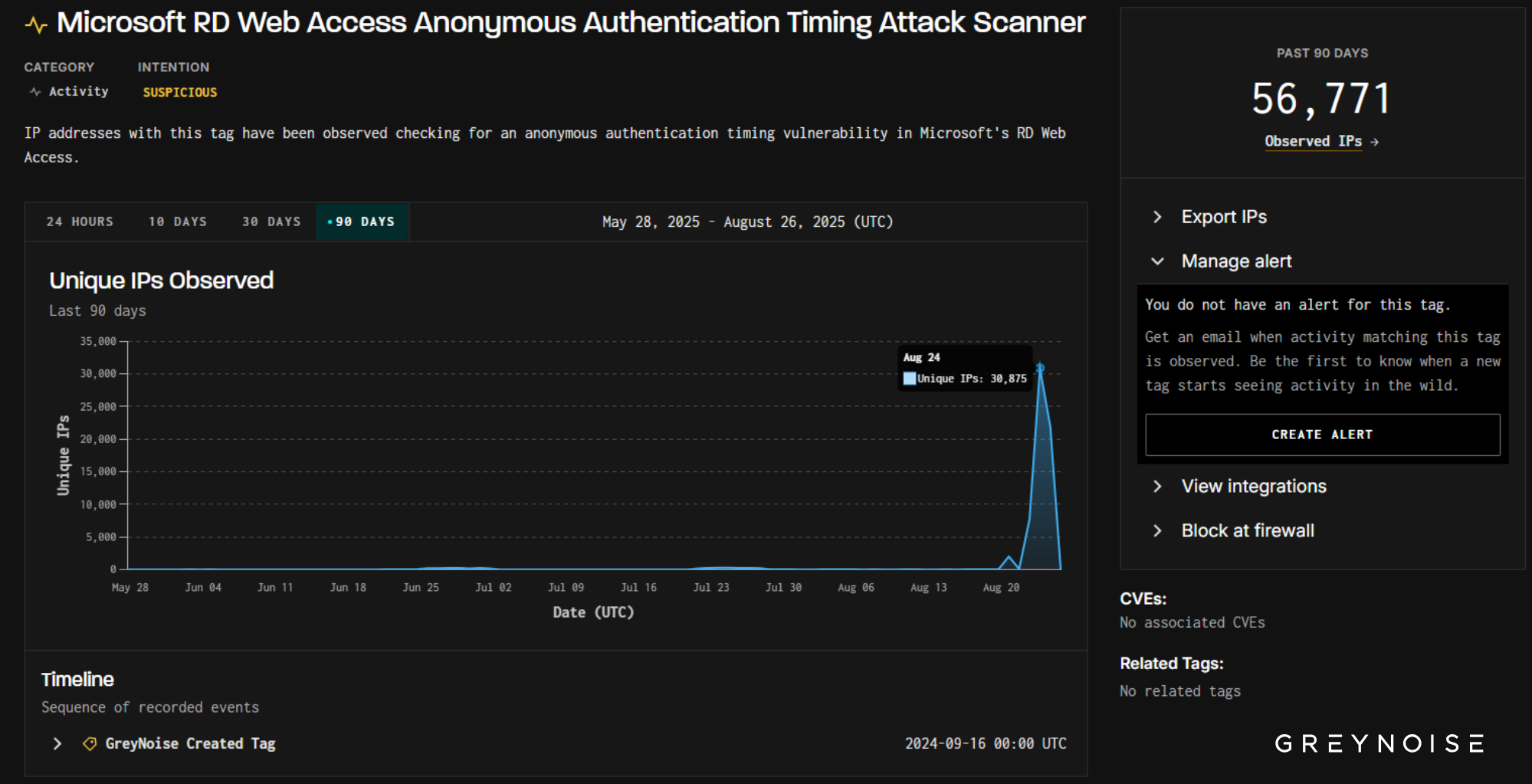
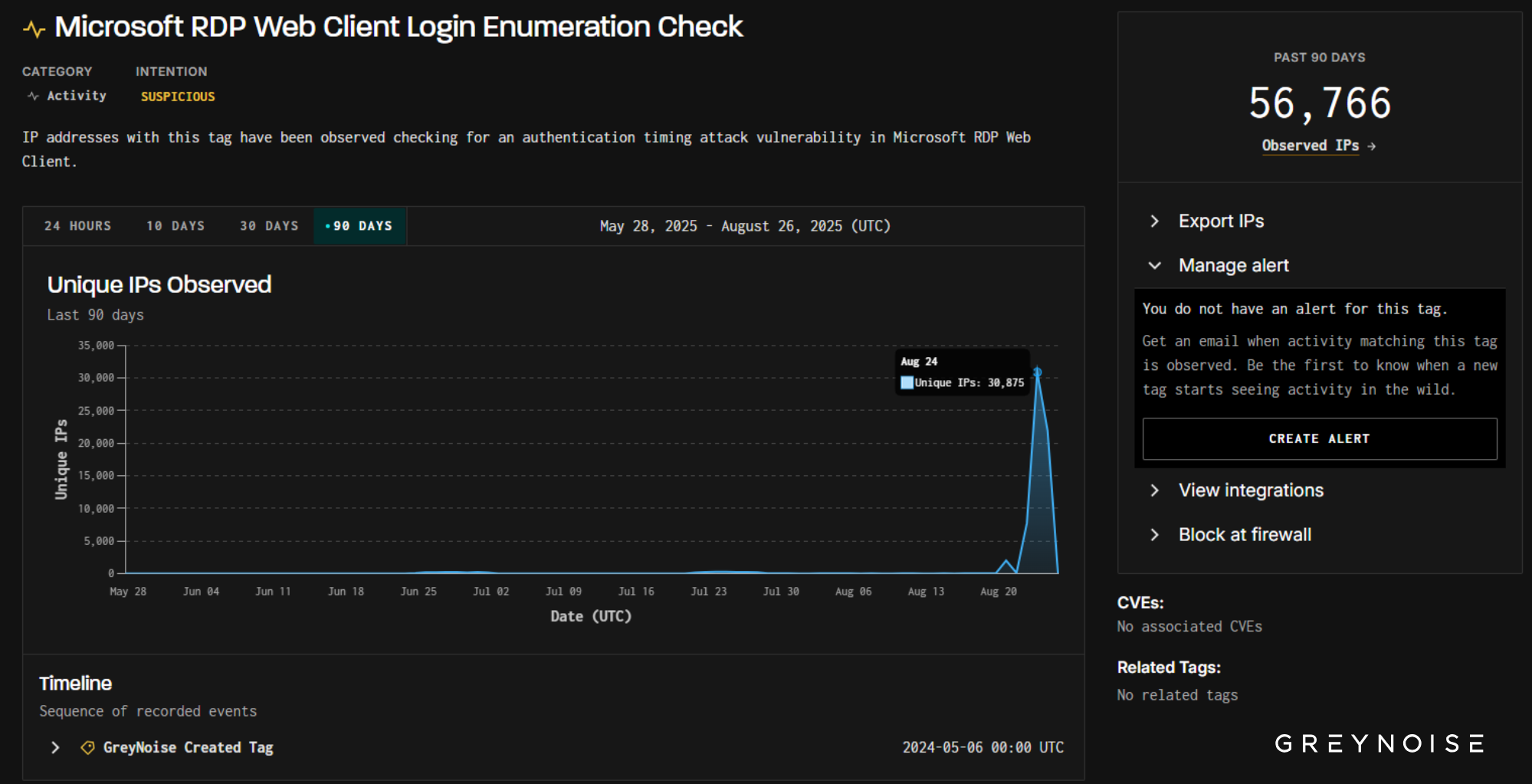
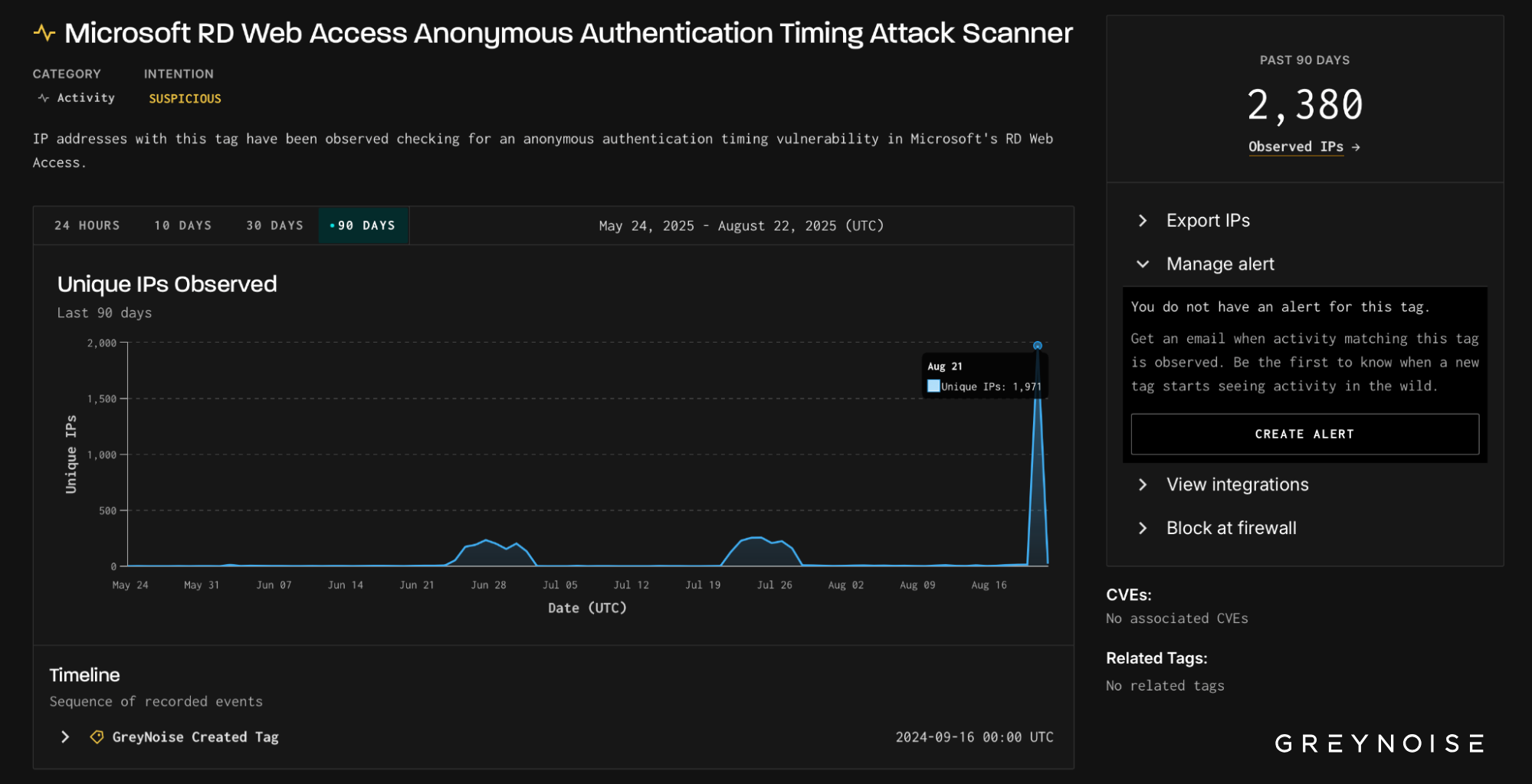
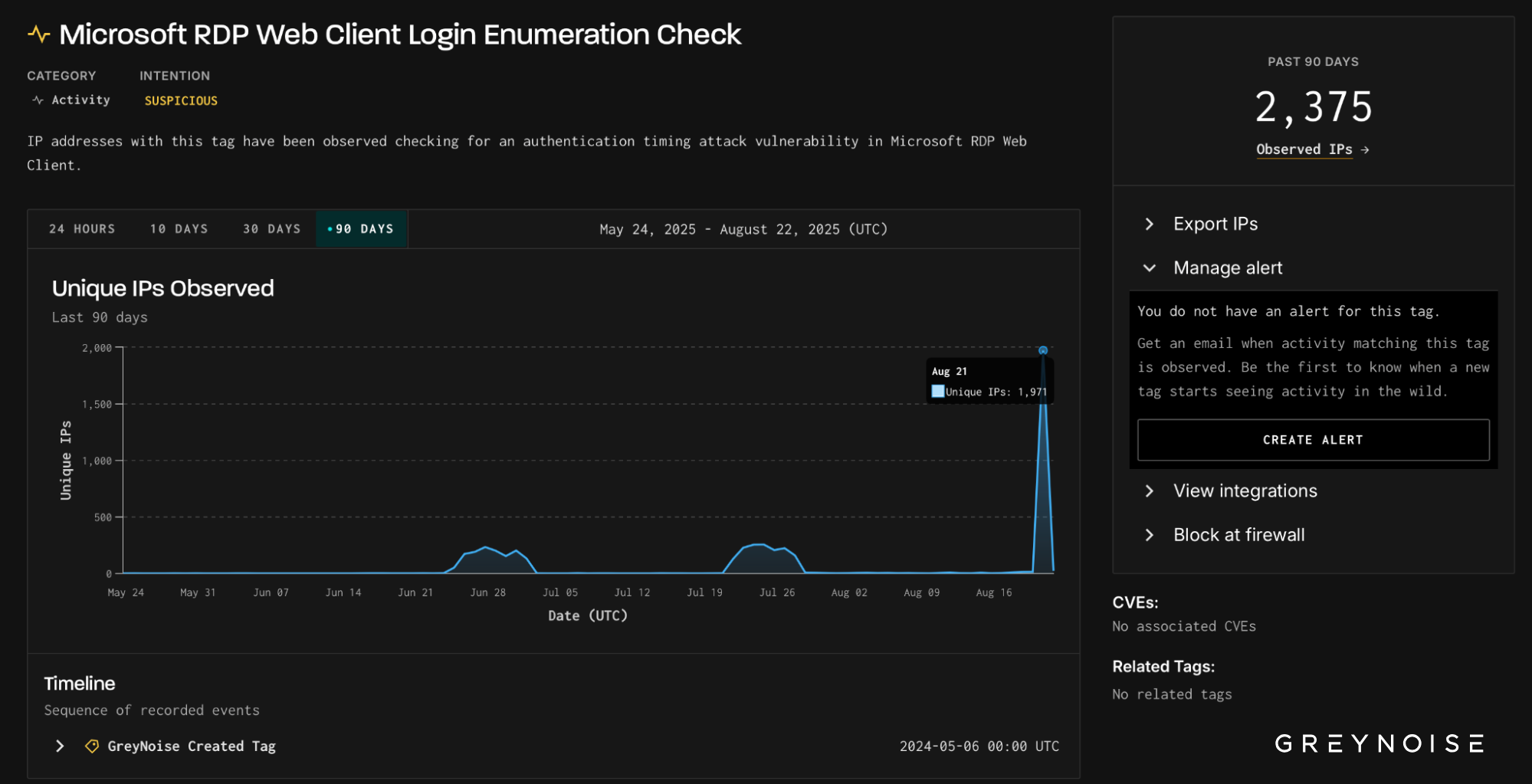
On August 21, GreyNoise observed a sharp surge in scanning against Microsoft Remote Desktop (RDP) services. Nearly 2,000 IPs — the vast majority previously observed and tagged as malicious — simultaneously probed both Microsoft RD Web Access and Microsoft RDP Web Client authentication portals. The wave’s aim was clear: test for timing flaws that reveal valid usernames, laying the groundwork for credential-based intrusions.
Separately but potentially relevant, on August 22 GreyNoise observed a spike in scanning for open proxies. This heightened activity follows recent anomalies observed on July 31 and August 9 against GreyNoise’s Open Proxy Scanner tag. Early research indicates there is partial overlap in client signatures between this spike and the RDP scan detected on August 21.
The timing may not be accidental. August 21 sits squarely in the US back-to-school window, when universities and K-12 bring RDP-backed labs and remote access online and onboard thousands of new accounts. These environments often use predictable username formats (student IDs, firstname.lastname), making enumeration more effective. Combined with budget constraints and a priority on accessibility during enrollment, exposure could spike.
The campaign’s US-only targeting aligns with that calendar — education and IT teams should harden RDP now and watch for follow-up activity from this same client signature.
The RDP scanners were doing more than just touching login pages:
This is enumeration: confirming accounts on exposed systems so later credential stuffing, password spraying, or brute force has a much higher chance of success.
A large, uniform, maliciously-classified scanner set is actively mapping Microsoft RDP authentication surfaces for account discovery weaknesses. Even without immediate exploitation, the output of this campaign (which endpoints exist, which accounts likely exist) is directly reusable for:
Recent research found spikes in attacker activity against a given technology tend to precede new vulnerabilities in that technology. In 80 percent of cases, a new vulnerability emerged within six weeks of a spike.
RDP has been leveraged by threat actors in the past to conduct espionage, deploy ransomware, and run global exploit campaigns:
GreyNoise will continue monitoring the situation and update this blog as necessary.
Please contact your GreyNoise support team if you are interested in the JA4+ signatures in this investigation.
GreyNoise has developed an enhanced dynamic IP blocklist to help defenders take faster action on emerging threats. Click here to learn more about GreyNoise Block.
— — —
Stone is Head of Content at GreyNoise Intelligence, where he leads strategic content initiatives that illuminate the complexities of internet noise and threat intelligence. In past roles, he led partnered research initiatives with Google and the U.S. Department of Homeland Security. With a background in finance, technology, and engagement with the United Nations on global topics, Stone brings a multidimensional perspective to cybersecurity. He is also affiliated with the Council on Foreign Relations.

On August 3, GreyNoise observed a significant spike in brute-force traffic targeting Fortinet SSL VPNs. Over 780 unique IPs triggered our Fortinet SSL VPN Bruteforcer tag in a single day — the highest single-day volume we’ve seen on this tag in recent months.
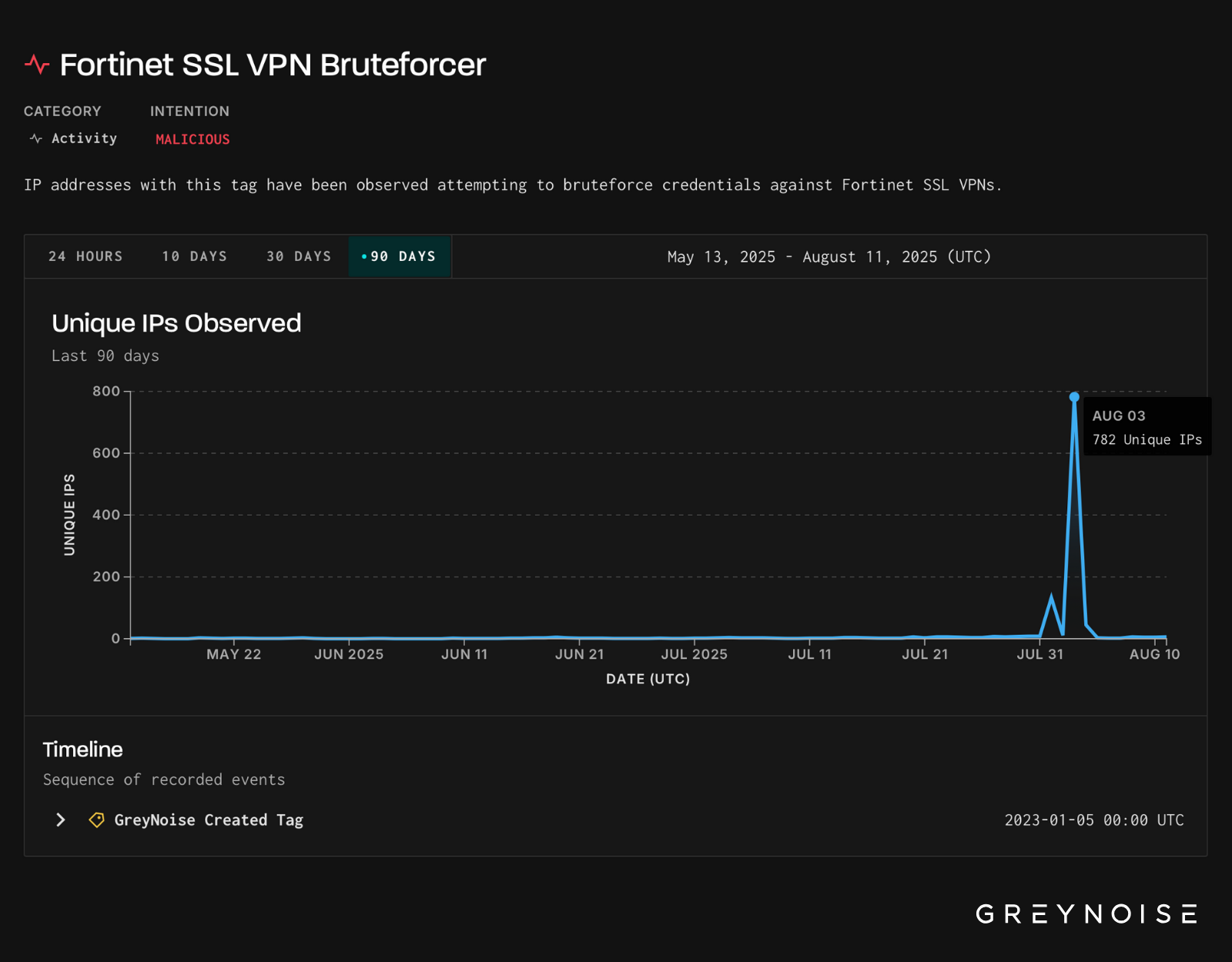
New research shows spikes like this often precede the disclosure of new vulnerabilities affecting the same vendor — most within six weeks. In fact, GreyNoise found that spikes in activity triggering this exact tag are significantly correlated with future disclosed vulnerabilities in Fortinet products. The below chart shows spikes in activity against Fortinet tags (white dots) and CVE disclosures affecting Fortinet products (red dots):
.png)
Critically, the observed traffic was also targeting our FortiOS profile, suggesting deliberate and precise targeting of Fortinet’s SSL VPNs. This was not opportunistic — it was focused activity.
The top target countries in the past 90 days are Hong Kong and Brazil.
When we reviewed a two week window of traffic matching the Fortinet SSL VPN Bruteforcer tag, two distinct waves emerged:
This made the decision easy: we pivoted to the second wave to learn more.
Once the TCP signature for the second wave was isolated, we paired it with an observed client signature seen in sessions during the same timeframe.
What we found was surprising.
While the August 3 traffic has targeted the FortiOS profile, traffic fingerprinted with TCP and client signatures — a meta signature — from August 5 onward was not hitting FortiOS. Instead, it was consistently targeting our FortiManager - FGFM profile albeit still triggering our Fortinet SSL VPN Bruteforcer tag.
This indicated a shift in attacker behavior — potentially the same infrastructure or toolset pivoting to a new Fortinet-facing service.
IPs associated with the meta signature:
31.206.51.194
23.120.100.230
96.67.212.83
104.129.137.162
118.97.151.34
180.254.147.16
20.207.197.237
180.254.155.227
185.77.225.174
45.227.254.113
One additional lead emerged during the investigation.
When reviewing historical data tied to the same post-August 5 TCP fingerprint, we found an earlier spike in June with a unique client signature that resolved to an IP — a FortiGate device — in a residential ISP block (Pilot Fiber Inc.). This may indicate that the brute-force tooling was initially tested or launched from a home network — or it could reflect use of a residential proxy. A quick search of the device revealed:
Notably, traffic tied to that same client signature in June was later seen paired with the same TCP signature associated with the longer-running brute-force cluster (Wave One) mentioned earlier. This overlap doesn’t confirm attribution, but it suggests possible reuse of tooling or network environments. Simply put, this side quest led us back to the original traffic associated with the August 3 spike.
Use GreyNoise to:
Please contact your GreyNoise support team if you are interested in the JA4+ signatures in this investigation.
GreyNoise will continue monitoring the situation and provide updates as necessary.
GreyNoise is developing an enhanced dynamic IP blocklist to help defenders take faster action on emerging threats. Click here to learn more or get on the waitlist.
— — —
This research and discovery was a collaborative effort between Towne Besel and Noah Stone.

In today’s threat landscape, speed isn’t optional — it’s existential. As attacks get faster, so too must your defense.
Attackers increasingly leverage automation, AI, and vast, ephemeral infrastructure to launch mass exploitation campaigns that scan, breach, and pivot within minutes — sometimes before a CVE is even publicly disclosed. Defenders, meanwhile, are often stuck pulling data manually, querying APIs, or waiting for threat feeds to update.
That’s the speed gap that attackers exploit. Today, we're launching a series of new capabilities to help defenders close that gap. These new capabilities help security teams leverage real-time threat intel to detect, block, and respond faster than ever before
The game has changed:
Yet many defenders still operate in batch mode: querying APIs, pulling feeds manually, or reacting only after the damage is done. GreyNoise is flipping that script. We’re giving defenders real-time, automation-ready intelligence — designed to meet the speed, volume, and precision required by modern security teams.
Stop mass exploitation at the edge — before it gets in.
GreyNoise-verified malicious IPs involved in opportunistic reconnaissance and exploitation are delivered in real time, designed to be integrated directly into your perimeter defenses.
Use it to:
Threat intelligence that comes to you — automatically.
Say goodbye to the delays caused by polling APIs. Our new push-based data delivery means GreyNoise intelligence is streamed directly to your systems via webhooks — the moment we detect something new.
In security, minutes (even seconds) matter. Push-based intelligence closes the speed gap between attack and defense.
From detection to action — with zero manual steps.
GreyNoise now integrates natively with leading SOAR platforms–such as Splunk SOAR, Palo Alto Networks XSOAR, IBM QRadar SOAR–to help teams turn intelligence into action, instantly and automatically.
Automate key workflows like:
The result:
These launches are part of GreyNoise’s commitment to empowering defenders with:
These new capabilities are built for:
GreyNoise is building the future of threat intelligence for defenders who don’t have time to wait.
Meet with us at Black Hat 2025 to learn more — or get started today.
.png)
It’s well known that the window between CVE disclosure and active exploitation has narrowed. But what happens before a CVE is even disclosed?
In our latest research “Early Warning Signals: When Attacker Behavior Precedes New Vulnerabilities,” GreyNoise analyzed hundreds of spikes in malicious activity — scanning, brute forcing, exploit attempts, and more — targeting edge technologies. We discovered a consistent and actionable trend: in the vast majority of cases, these spikes were followed by the disclosure of a new CVE affecting the same technology within six weeks.
This recurring behavior led us to ask:
Could attacker activity offer defenders an early warning signal for vulnerabilities that don’t exist yet — but soon will?
Across 216 spikes observed across our Global Observation Grid (GOG) since September 2024, we found:
Exploit activity may be more than what it seems. Some spikes appear to reflect reconnaissance or exploit-based inventorying. Others may represent probing that ultimately results in new CVE discovery. Either way, defenders can take action.
Blocking attacker infrastructure involved in these spikes may reduce the chances of being inventoried — and ultimately targeted — when a new CVE emerges. Just as importantly, these trends give CISOs and security leaders a credible reason to harden defenses, request additional resources, or prepare strategic responses based on observable signals — not just after a CVE drops, but weeks before.
The full report includes:
This research builds on our earlier work on resurgent vulnerabilities, offering a new lens for defenders to track vulnerability risk based on what attackers do — not just what’s been disclosed.

One of our engineers was reviewing our telemetry dashboard when he came across something unusual:
A tight cluster of red dots — each one representing a malicious IP — lighting up a rural patch of New Mexico:
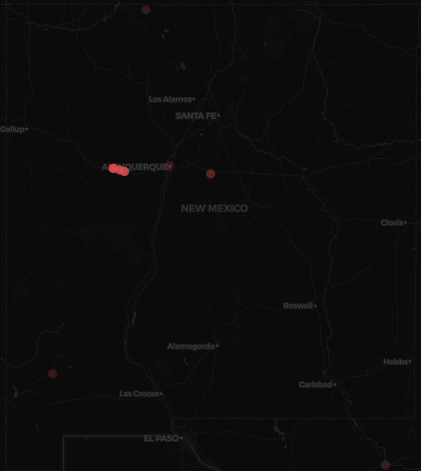
Nothing unusual about botnet traffic. But this time, dozens of malicious IPs were all coming from a single region with a population of just over 3,000 people.
It didn’t fit the pattern. So we dug in.
We zoomed into the map and picked up the first IP: 137.118.82.76.
It had a troubling combination of GreyNoise tags:
This wasn’t just a misconfigured device — it looked like a system actively participating in a botnet.
So we pulled the thread.
Zooming out, we found ~90 IPs in the same New Mexico region, all tied to a single provider: Pueblo of Laguna Utility Authority.
100% of this traffic was Telnet-based.
To dig deeper, we used our internal tooling — including the GreyNoise Model Context Protocol (MCP) server (an AI-powered analysis environment) — to iterate quickly on investigation paths.
We fed IP metadata and network behavior into Claude, exploring ideas in real time. We then used Censys infrastructure data and tshark packet captures to enrich the dataset.
This AI-powered analysis helped confirm that many of the systems were VOIP-enabled devices.
While we did not identify exact device models for each system, enrichment suggested hardware from Cambium Networks was likely involved in a portion of the activity.
It wasn’t a one-off misconfiguration — it appeared to be a coordinated cluster of similar systems likely running comparable stacks.
After confirming the localized activity, we widened the investigation.
Using GreyNoise tags, behavioral similarity, and Telnet traffic patterns, we identified about 500 IPs globally exhibiting similar traits:
Some of these IPs were linked to VOIP-capable devices and shared similar infrastructure characteristics — suggesting a wider class of exposed systems is being targeted for botnet activity.
VOIP devices often run on older Linux-based firmware, sometimes with Telnet exposed by default. They’re also frequently:
Some Cambium routers, for example, may still be running firmware versions impacted by a known remote code execution (RCE) vulnerability from 2017.
While we did not confirm exploitation of that CVE in this case, the activity reinforces a broader point: Vulnerabilities remain part of the attack surface long after disclosure.
We recently explored this dynamic in our latest report on resurgent vulnerabilities, where we highlight how long-patched flaws in edge devices are repeatedly targeted.
Shortly after a member of our team posted a brief mention of the activity on social media, the traffic from the New Mexico utility dropped off — completely.
Whether coincidence or evidence that attackers monitor visibility, it was a sharp cutoff.
And shortly after that, activity spiked yet again and the global behavior continued.
What started as a spike from a single utility in a rural part of the United States became a lens into an ongoing global pattern — one defenders should track closely.
GreyNoise has developed an enhanced dynamic IP blocklist to help defenders take faster action on emerging threats. Click here to learn more about GreyNoise Block.
---
This investigation was sparked by GreyNoise’s keen-eyed Lead Software Engineer Jeff Golden, with contributions from the broader GreyNoise research team.
Please update your search term or select a different category and try again.