I spend a lot of my time in SOAR consoles with security teams, and the same pattern shows up almost every time. The automation is already there. Playbooks fire, tickets open, enrichment runs. However, the decisions underneath are still shaky. Automation moves fast; it doesn't move smart on its own. A playbook that auto-routes a case is only as good as the context it routes on.
That's the gap GreyNoise fills. We don't replace your SOAR or your SIEM, we feed them. We tell your playbooks what not to worry about so the team can spend its hours on the activity that's actually aimed at them. Here are the five integrations I walk through in nearly every deployment.
1. IP enrichment that makes triage and response times faster
This is where almost everyone starts, and for good reason. Most SOCs still have analysts manually looking up IPs to determine whether an alert matters. The process is slow, repetitive, and often leads to inconsistent triage decisions.
We drop a /v3/ip lookup into the front of the playbook (single lookups or bulk, up to 10K at a time) so every alert gets enriched automatically with classification, tags, and threat level. Then you build your routing rules on top of that. The enrichment writes straight back to the case so the analyst sees the reasoning, not just the verdict.
The payoff is what teams care about most: faster response times, more consistent triage decisions, and a 40–60% reduction in alert volume once routine internet noise is identified and filtered.
2. Early warning when your vendors' CVEs start getting hit
Individual organizations often don’t see global exploitation spikes targeting their vendors until it’s too late. A surge in scanning or exploitation against a particular vendor's CVE can be an early sign of a zero-day or novel attack, but those patterns are difficult to detect when you're only looking at activity inside your own environment. By the time you hear about it after the vendor publishes an advisory, it may already be too late.
GreyNoise Event Feeds push an alert into SOAR the moment scanning or exploitation activity against your vendors' CVEs spikes. The playbook takes it from there: assess benign versus malicious activity, enrich with CVE and IP context, open a case, create a VM ticket, update blocklists, and notify the team in ChatOps.
The outcome is simple: detect rising exploitation activity days before vendors announce new vulnerabilities, patch and harden before attacks become widespread, and automatically separate real threats from benign scanning activity.
3. Detect compromised edge devices
This one resonates with anyone who's been burned by a compromised firewall or VPN appliance. You can't run EDR on those boxes, so when one gets popped and starts scanning the internet or calling home to attacker-controlled C2 infrastructure, you typically don't find out until blacklisted or it’s reported by an external party.
We run two feeds into the SOAR for this. First, a webhook fires when GreyNoise observes your IP ranges conducting unsolicited scanning, a strong signal something behind that address is compromised. Second, a callback IP feed alerts whenever we detect a new attacker callback destination, which the SOAR correlates against your outbound traffic. Either one triggers automatic case creation and a containment ticket. That means catching compromise before it leads to reputation damage, responding automatically in seconds, and keeping persistent issues tied together in a single case timeline.
4. Build high-trust blocklists
Every team wants to automate blocklist updates. Almost none of them fully trust the automation, because the nightmare scenario is auto-blocking a business-critical IP and taking down a legitimate service during business hours.
The fix is a validation step. Before an IP gets added to the blocklist, the playbook checks it against GreyNoise business services intelligence. If the IP is tied to a known business service, it routes to a human for manual review. If it's not, the block proceeds automatically. You get fast response to likely-malicious IPs without the over-blocking risk that keeps people from turning automation on in the first place.
The result is greater confidence in automated blocklist updates, reduced over-blocking risk, and faster response to likely malicious IPs. When I show this to a hesitant team, it's usually the thing that unblocks their whole automation roadmap.
5. Build valuable threat intelligence into agentic workflows
Most of the teams I work with are building agentic workflows now, and they keep running into the same wall: an agent is only as good as the context it can reach. Point it at incomplete or low-confidence data and you get confident-sounding nonsense.
GreyNoise plugs into those workflows through APIs, skills, or MCPs, so an agent investigating an alert can pull high-quality threat intelligence directly into its reasoning before it acts. The agent receives a trigger, queries GreyNoise, analyzes the context, and either returns an answer or kicks off a response workflow. This is grounded in observed attacker behavior rather than guesswork.
It's still early days for a lot of these deployments, but the teams seeing the most success are treating threat intelligence as a core input to the agent, not something bolted on afterward. The result is faster, more confident investigation and response grounded in high-quality threat intelligence.
The common thread
Which alerts deserve attention? Which CVEs are actively being exploited? Which IPs are worth blocking? Which signals point to a compromised device?
The reason these workflows work is because they're all built on the same foundation: real observations from across the internet. GreyNoise continuously watches scan and attack activity through our global sensor network, so when a playbook makes a decision, it's based on what an IP is actually doing in the wild, not just what it happened to do in your environment.
That's what gives teams the confidence to automate. Route an alert. Open a case. Block an IP. Escalate an investigation. The decision is backed by observed behavior, not a hunch.
I tell teams all the time that automation isn't the hard part anymore. Most organizations already have playbooks that can move fast. The challenge is making sure they're making the right decisions when they do.
If your SOAR is great at taking action but you're still questioning the inputs behind those actions, these are the first five workflows I'd look at. Explore our SOAR integrations >
Want to see any of these wired up live? Book a demo >
Every organization connected to the internet faces the same background noise: automated exploitation attempts, vulnerability scanning, and credential abuse hitting the perimeter around the clock. The hard part isn't seeing the traffic, it's answering three questions fast enough to matter. What's hitting us? What's getting through? And what's already talking to adversary infrastructure?
GreyNoise continuously observes scan and attack activity across the internet, classifies the source IPs by behavior, and delivers that intelligence into your SIEM. The point isn't more data. It's separating the opportunistic noise, the stuff hitting everyone, from activity that might actually be aimed at you. Here are four ways SOC teams are putting that distinction to work.
1. Reduce alert volume and surface potentially targeted threats
The problem
Detections on perimeter scans and attacks are noisy by nature. Most alerts off edge devices aren't real threats, so they get ignored or suppressed. The alerts worth investigating are in there but they're just buried under scanning noise that hides anything resembling a targeted threat.
The detection
Filter your firewall and WAF logs down to inbound internet traffic, then match source IPs against GreyNoise and exclude the known mass scanners. Prioritize what's left by source-IP volume. Stripping out opportunistic scanning means analysts triage far fewer events, and the detection logic that remains has room to surface traffic more likely to represent targeted reconnaissance or attack activity.
The signal
Fewer alerts, better signal-to-noise. Every remaining alert comes from an IP GreyNoise has never observed scanning the internet, which is a much stronger indicator of potential targeted reconnaissance.
2. Detect allowed inbound traffic from known-malicious hosts
The problem
Perimeter gaps go unnoticed because nothing validates whether traffic that was allowed through should have been. Without external intelligence, traffic that passes through the firewall may not receive additional scrutiny, even when the source IP has a documented history of malicious activity.
The detection
Correlate firewall and WAF allow logs against GreyNoise intelligence. Filter to inbound allowed events, match the source IPs against GreyNoise, and surface the malicious and suspicious matches, prioritized by source-IP volume. That tells you when something you let in originated from a host observed conducting mass scanning or exploitation.
The signal
A list of sessions where known-malicious or suspicious IPs were permitted through your perimeter. Each match is two things at once: a session worth investigating, and a firewall or WAF rule worth re-evaluating.
3. Flag authentication attempts from compromised hosts
The problem
Authentication failures and brute-force attempts from the internet are constant for any perimeter device. The trouble is telling opportunistic account access apart from attempts aimed specifically at your organization. Hosts running mass scans or operating as part of botnet or proxy infrastructure authenticate to VPNs and identity providers all the time, and standard detection logic doesn't flag it.
The detection
Correlate VPN and identity-provider authentication logs with GreyNoise. Filter to authentication events, match source IPs against GreyNoise, include the not-spoofable matches, and prioritize by source-IP volume. That surfaces auth attempts coming from hosts already observed scanning the internet, early enough to intervene on both successful and failed attempts.
The signal
A successful auth from a GreyNoise-flagged IP is an immediate, high-priority alert. Failed attempts from flagged IPs are worth a look too, as they can indicate active targeting of your identity infrastructure rather than random background noise.
4. Detect outbound connections to threat infrastructure
The problem
Outbound connection volume is so high that alerting on or investigating anomalous connections individually is impractical, so connections from internal infrastructure to known-malicious systems slip by. Most threat intel feeds don't help here either because they lack the real-time behavioral data needed to tell which outbound connections actually warrant a look.
The detection
Internal hosts reaching out to malicious infrastructure is a clear sign of compromise. Take outbound network and EDR logs, filter to public connections that egress allowed, match destination IPs against GreyNoise, and surface the malicious matches, prioritized by internal source-IP volume. When an internal host lights up here, the correlation points at a possible indicator of compromise - C2 beaconing, data exfiltration, or botnet participation.
The signal
Any successful outbound connection to GreyNoise-classified malicious infrastructure warrants immediate investigation of the internal host for indicators of compromise.
The operational payoff
Stacked together, these four detections move the needle on the things that security teams actually care about:
Reduce alert volume by removing opportunistic scanning from SIEM telemetry.
Improve signal-to-noise by prioritizing events more likely to represent targeted threats.
Surface perimeter gaps by identifying malicious infrastructure that made it through your defenses.
Detect compromise earlier by flagging suspicious authentication and outbound activity sooner.
None of this replaces the tooling you already run. GreyNoise is the context layer that makes your firewall, WAF, identity provider, EDR, and SIEM better at separating the internet's constant background noise from the activity worth your analysts' time.
If you defend an enterprise network, you almost certainly trust an IP blocklist somewhere in your stack. That blocklist was almost certainly built for a different threat landscape than the one you are defending against today.
We measured it. On a single day, May 14, 2026, the GreyNoise Global Observation Grid recorded 119,842 malicious, non-spoofable IPs targeting edge infrastructure. We compared that set against eleven of the most widely deployed OSINT and commercial IP feeds in the industry. The average coverage was 2.0%. The strongest individual feed closed less than five percent of the gap.
That is not a flaw in any single feed. It is the cost of static curation in 2026.
What the Numbers Look Like
Feed
List Size
Coverage of Source
Gap
FireHol Level 2
16,242
4.30%
95.70%
Blocklist.de (All)
22,404
3.91%
96.09%
FireHol Level 3
14,306
3.51%
96.49%
CINS Army List
15,000
2.97%
97.03%
FireHol Level 4
78,104
2.53%
97.47%
Avastel 1-Day Proxy/Bot IPs
500,000
1.85%
98.15%
ShadowWhisperer Malware/Hackers
6,894
1.40%
98.60%
FireHol Level 1
4,456
1.18%
98.82%
Binary Defense Ban List
2,719
0.32%
99.68%
Palo Alto High Risk EDL
2,776
0.28%
99.72%
Palo Alto Known Malicious EDL
4,000
0.24%
99.76%
Eleven feeds tested. None broke five percent. The list with the largest absolute size (Avastel, half a million IPs) caught fewer than two percent of the malicious traffic we observed in the same window. The vendor-curated EDLs that ship by default in many enterprise firewalls came in under half a percent.
This is not because those feeds are bad. They are doing the job they were designed to do, which is to flag IPs that meet a high bar for confidence. The problem is that "high bar" is often the result of a manual and slow review process.
Why Static Lists Are Losing Ground
The pace of attacker infrastructure has changed. Three forces are compressing the useful life of an indicator faster than any curated list can keep up.
1. AI-assisted scanning
Automated reconnaissance no longer requires a human in the loop. Threat actors can spin up scanners at a scale and speed that was operationally impractical even two years ago, then rotate the source infrastructure once it gets noisy.
2. Residential proxy botnets
A growing share of malicious traffic now originates from compromised consumer devices and rented residential IP pools. These IPs do not look like traditional badness. They sit inside ISP ranges that you cannot blanket-block without breaking legitimate traffic, and they recycle constantly.
3. Ephemeral cloud and hosting infrastructure
Attackers stand up VPS instances, run a campaign, and tear them down before most curation pipelines have rotated through their next refresh cycle. The same IP that was scanning Cisco IOS XE on Monday belongs to someone else's WordPress blog by Friday.
The result: list turnover at most curated feeds is measured in dozens of IPs per day. The threat infrastructure those feeds are trying to track is churning by the tens of thousands. A list refreshed weekly, or even daily, is staring at yesterday's attackers.
What GreyNoise Actually Is
GreyNoise is primary-source intelligence. Every IP in our dataset was observed by a GreyNoise sensor doing the thing we say it was doing. We do not aggregate other vendors' lists or infer from reputation. We have the receipts: raw session data captured at the moment of the event, whether that was a scan, an exploit attempt, or a brute-force payload.
The Global Observation Grid is a globally distributed sensor network specifically designed to attract and classify internet-wide scanning and exploitation activity. When an IP shows up in our 1D / Malicious / Non-Spoofable feed, it is there because we watched it do something malicious in the last 24 hours, and we can show the evidence behind the verdict for any IP, tag, or CVE in the dataset.
This matters for two reasons.
First, the data is primary-source. We are not synthesizing a confidence score from third-party reports. The classification is grounded in observed traffic on infrastructure we control.
Second, the IPs are non-spoofable. The GreyNoise sensor architecture eliminates the class of IPs that look malicious in scan logs but are actually forged source addresses in reflection or amplification attacks. When we tell you an IP was scanning your edge, that IP was scanning your edge.
That combination is what makes the data viable for the use cases the static lists were built for, and a lot of use cases they were never designed to support.
Turning the Data Into a Blocklist You Can Actually Deploy
Closing the 98% gap is only useful if the intelligence can get into the box that does the blocking. GreyNoise offers two ways to do that, and they are intentionally separate products built for different audiences and different levels of customization.
The Primary Path: GreyNoise Platform Blocklists
The GreyNoise Platform, best suited for large security teams, enterprises, and governments, includes advanced blocklist functionality built directly into the Visualizer. These Query-Based Blocklists are built using GNQL: you write or refine the query yourself, validate the results, and convert that query into a managed blocklist with one click.
This is the right path for teams that already live in the Visualizer and want full GNQL expressiveness without leaving the platform. The workflow is:
Run a GNQL query in the search bar. For example, last_seen_malicious:1d AND spoofable:false ANDtags:*Cisco* will block recently malicious IPs hitting Cisco gear.
Review the returned IPs to confirm the list looks right.
Click "Create Blocklist," name it, set an IP limit, and submit.
Wait 1-3 minutes for provisioning, then pull the tokenized URL (or use header-based auth with your API key) into your firewall. The list refreshes hourly from there.
Common starting queries documented by GreyNoise include recent malicious or suspicious activity, vendor-tagged activity (Cisco, Palo Alto, Fortinet, and so on), CVE-specific exploitation attempts, and geographic scoping. Anything you can express in GNQL, you can turn into a deployable list.
A configuration walk-through for Palo Alto Networks External Dynamic Lists is published here, and the same pattern applies to most NGFW vendors that support URL-based dynamic lists.
Try the GreyNoise Platform free — explore query-based blocklists and enterprise-grade threat intelligence firsthand. Request a trial >
The Alternative: GreyNoise Block for SMBs
GreyNoise Block is a separate product built specifically for small and mid-sized organizations that only need blocking capabilities.
Block gives you two ways to define a list:
Templates. Pre-built blocklists curated by GreyNoise, ready to deploy with a click. You pick the template, name the list, set an IP limit that matches what your firewall can ingest, and Block produces a URL. The template handles the GreyNoise Query Language (GNQL) behind the scenes. For a firewall admin who wants a small, targeted blocklist running by lunch, this is the path.
Advanced Query Builder. A drag-and-drop interface for building custom queries against the GreyNoise Global Observation Grid's data. You can scope by classification (malicious, suspicious, benign, unknown), source country, tag, CVE, actor, CIDR block, first-seen window, and lookback period. Group conditions and NOT operators are supported, so you can build queries like "malicious activity in the last day, excluding US-based infrastructure and a specific CIDR you operate." The builder shows you the resulting query and the IP count in real time, and the same "Block These IPs" button turns it into a deployable URL.
Deployment is the same either way: copy the blocklist URL, paste it into your firewall's external dynamic list configuration, and authenticate with either an inline ?key=YOUR_API_KEY parameter or a request header named key. Lists refresh hourly after the initial 5–10 minute provisioning window.
Try GreyNoise Block for 14 days with a free trial. Try it free >
The Bottom Line
The blocklists that defended the perimeter for the last decade were good products built for a slower-moving adversary. They are still doing useful work today, and we are not suggesting anyone rip them out.
What we are suggesting is this: if 98% of the malicious activity hitting your edge on a given day is invisible to your current feeds, the right response is to add a source that can see it, not to keep waiting for static curation to catch up to something that has fundamentally changed.
GreyNoise enriches the tools you already run with continuously updated, primary-source intelligence. No list maintenance overhead. No second curation team. The customers who have done the integration get the benefit of seeing what we see, in the systems they are already running.
By the way, there is nothing special about May 14th. The 119,842 IPs we saw on that day are not a number that will hold tomorrow. By the time you read this, the count has already turned over. That is the point.
----
Data collected 2026.05.14. Source: GreyNoise 1D / Malicious / Non-Spoofable. Comparison destinations include FireHol Levels 1 through 4, Blocklist.de, CINS Army List, Palo Alto Known Malicious EDL, Palo Alto High Risk EDL, ShadowWhisperer Malware/Hackers, Binary Defense Ban List, and Avastel 1-Day Proxy/Bot IPs.
Between May 9 and May 18, 2026, GreyNoise observed a significant new spike in scanning of SonicWall SonicOS management interfaces. The May 12 peak — approximately 597,000 sessions — was the largest single-day total recorded on the SonicWall SonicOS API Scanner tag in the past 90 days, roughly 46× the typical daily volume for this tag in the 30 days before the elevation.
Similar elevations in activity against this GreyNoise tag have preceded new vulnerability disclosures affecting SonicWall (Ten Days Before Zero, GreyNoise 2026).
Activity on this tag spiked three times in an earlier sequence — on January 18, January 30, and February 14 — at 37, 25, and 10 days before the February 24 disclosure of CVE-2026-0400. The current spike may be a similar early warning.
The relationship is one observed precedent, not a rule. The current spike could be the first of a multi-event sequence like the Q1 pattern, a single event preceding a disclosure, or unrelated activity. Three documented spikes on this tag preceded a single CVE — a precedent, not an established cadence, and not a definitive rule.
GreyNoise is publishing the signal, not predicting a CVE.
Single-day session volume on the SonicWall SonicOS API Scanner tag. Three Q1 activity spikes — January 18, January 30, and February 14, 2026 — preceded the February 24 disclosure of CVE-2026-0400. The May 12 peak is the largest single-day total recorded on this tag in the past 90 days.
What We're Seeing
Tooling: Approximately 99% of requests carry a single browser user-agent — Chrome 119 on Linux x86_64 — the same fingerprint that dominated the January–February SonicWall scanning (94.5% of Q1 traffic, per Ten Days Before Zero). The tooling appears unchanged.
Source infrastructure: Approximately 56% of sessions originate from networks announced in the Netherlands and 44% in Ukraine — together more than 99% of total volume.
Concentration: A single ASN (AS211736) carries roughly half of total session volume. The IPs involved are overwhelmingly classified by GreyNoise as Suspicious.
Targeted services: Ports 80 and 8080 (HTTP) carry virtually all the scanning.
What Defenders Should Do
Immediate:
Restrict SonicOS management API and SSL VPN portal access to known administrative ranges. Eliminate public exposure of management interfaces.
Require MFA on all SSL VPN accounts.
Audit SonicOS configuration for new administrative accounts created since May 1, 2026.
Here at GreyNoise, we’ve spent years building one of the most advanced deception networks on the internet. Our Global Observation Grid has over 5,000 sensors across 80 countries processing more than 500 million sessions per day, allowing us to see the internet's attack traffic before it reaches your doorstep. We've used that visibility to alert the world to mass scanning surges, vuln exploitation waves, and early reconnaissance patterns that signal what's coming next.
But there's a class of adversaries we can't catch alone.
The Perimeter Was Never “Dead”
The most advanced threat actors, state-sponsored adversaries like the Typhoon groups, have figured something out: the network edge is still a blind spot. Firewalls, VPN gateways, routers, load balancers — these devices can't run EDR agents. They often don't even support basic telemetry like logging. And they sit at the most critical exposure point: the network edge.
These adversaries have made edge devices their preferred point of initial access. They exploit vulnerabilities in firewalls and VPN gateways, hijack built-in tools on perimeter devices to maintain persistence, and send quiet, targeted probes designed to blend into the background. The Typhoon actors have demonstrated the most sophisticated version of this approach, building massive residential botnet proxies by compromising edge devices with little-to-no monitoring. APT41 has exploited zero-days in Fortinet VPNs, Cisco routers, and Citrix appliances. And well-funded ransomware crews are increasingly following the same path. The edge is where advanced adversaries go first, because it's where defenders see least.
Meanwhile, the exposure window keeps widening. The average patch time for edge devices is roughly 32 days, but exploit time is often near zero. For an entire month, your critical internet-facing infrastructure sits exposed to adversaries who are already watching.
The perimeter was never dead — it's the hardest attack surface to defend, and threat actors know it.
Deception Is the Best Answer
When the adversary specializes in staying quiet, you have to change the game. We believe deception is the best way to provide visibility into edge attacks — you can’t detect the threat; but you can make the threat reveal itself.
GreyNoise deploys sensors that emulate the exact assets attackers are looking for. When an adversary probes a sensor, they believe they've found a real target. Instead, they've exposed their tools, their payloads, their behavioral fingerprints, and their intent.
But here's the problem: no single organization can build the deception infrastructure needed to cover the internet's entire attack surface. We need more IP diversity, more device profiles, and faster detection rules than any one company can produce on its own.
That's why we're opening up our platform.
Announcing Project Swarm
Today, we're launching Project Swarm — a research initiative that opens the GreyNoise deception platform to the global security community.
Project Swarm transforms GreyNoise from a proprietary sensor network into a collective intelligence platform. We're inviting security researchers, universities, non-profits, ISPs, and OEM manufacturers to contribute to three pillars that make edge deception work at scale:
IP Coverage — Deploy sensors on your infrastructure to expand the geographic and network diversity of the Global Observation Grid.
Device Coverage — Bring device profiles for the edge assets you know best — firewalls, routers, VPN gateways — so sensors look like real, high-value targets to attackers.
Detection Velocity — Contribute detection rules and tags to identify attacker TTPs faster than GreyNoise can alone.
What You Get
When you deploy a GreyNoise sensor through Project Swarm, you get visibility into all the traffic hitting that sensor, and everything your sensor captures is yours to work with.
Every session is recorded with full fidelity: raw PCAPs, payloads, HTTP headers, TLS metadata, and behavioral artifacts. That means you're not just seeing that something probed you — you're seeing exactly what it did, what it sent, and how it behaved.
For researchers, this opens up a world of possibilities. Here are some ideas to get you started:
Analyze captured payloads to reverse-engineer exploit attempts and study attacker tooling in the wild.
Track how scanning and exploitation campaigns evolve over time by watching the same vulnerability get targeted with different techniques over time.
Study the behavioral patterns that distinguish targeted reconnaissance from opportunistic noise — timing, sequencing, header fingerprints, TLS characteristics.
Correlate early-stage recon activity against eventual CVE disclosures to build predictive models for what's coming next.
Write and contribute detection rules based on what you observe, improving the GreyNoise tag library for the entire community.
Compare your sensor traffic against the GreyNoise global baseline to identify what's specifically targeting your sensor versus what's hitting the broader internet.
The possibilities are limited only by what IPs, emulators, and devices you can bring to Project Swarm.
Join the Collective
We believe deception is the best and only way to gain real visibility on the edge. You can't install agents on embedded systems. You can't rely on logs that don't exist.. But you can put something in the attacker's path that looks real enough to make them show their hand. When they probe a deceptive asset, they reveal themselves — their tools, their intent, their techniques — without ever knowing they've been caught.
The challenge is scale. To see the full picture, deception infrastructure needs to span more IP space, emulate more device types, and develop detection rules faster than any single organization can manage. That's what Project Swarm is about — turning the security community's collective reach into the world's most advanced deception network.
The era of defending in isolation is over. The adversaries targeting the edge are patient, precise, and well-resourced. But together, we can be everything, everywhere, all at once. Security is a collective team sport.
Before Cisco published its advisory for CVE-2026-20127 — a CVSS 10.0 zero-day cited in a Five Eyes joint warning — GreyNoise sensors had already observed eight distinct surges of Cisco-targeting activity. The earliest arrived 39 days before disclosure. Each one came closer than the last. A new study finds this pattern is not an anomaly.
What the Data Shows
Over 103 days, GreyNoise tracked 147.8 million sessions across 276 vendor-specific tags covering 18 network infrastructure vendors. Of 104 detected surge events, 68 preceded a vendor-matched CVE — spanning 33 vulnerabilities across 16 vendor families. Statistical testing confirmed the pattern is not coincidence.
Median lead time: 11 days. 49% of surges arrived within 10 days of disclosure. 78% within 21 days.
Session volume is the primary signal. Session volume carries the early warning. IP count alone is a weaker predictor, but when both spike simultaneously, the warning is highest confidence and the lead time extends to 21 days.
Countdown compression. SonicWall CVE-2026-0400: six surges from 37 to 3 days, peaking at 69x median volume. Fortinet CVE-2026-24858 (CVSS 9.4, zero-day): one day of warning.
Concentrated targeting shortens the window. Distributed surges averaged 21.3 days of lead. Concentrated hosting surges: 7.5 days. 11 ASNs appeared across 3+ vendor families.
Why This Matters
Mandiant's M-Trends 2026 found that mean time-to-exploit has gone negative. VulnCheck documented that 28.96% of KEVs in 2025 were exploited on or before publication day. The traditional model — wait for the advisory, then act — leaves a measurable gap. The signals that narrow that gap are already visible in GreyNoise data.
A fleet of 21 IP addresses is now generating nearly half of all the RDP scanning traffic on the public internet. On April 7, 2026 alone, those IPs produced 1,856,167 of the 2,753,274 RDP Crawler sessions observed globally by the GreyNoise Observation Grid (GOG) — 67.4% of the worldwide total. Across a 48-hour window from April 5–7, the same fleet accounted for 49.7% of global RDP Crawler activity, while the other 3,644 sources on the internet produced the rest combined.
RDP — short for Remote Desktop Protocol — is how Windows lets people log into a computer remotely. Attackers scan the internet for exposed RDP endpoints, initiating connection requests at scale to map targets. Once they find an open service, brute-force password attempts typically follow. RDP has been one of the top entry points into corporate networks for years, which is why the sudden concentration of scanning activity in one small network matters.
The 21 RDP fleet IPs are part of a larger cluster of active addresses in a single autonomous system: AS213438, registered in RIPE WHOIS to ColocaTel Inc. of Mahe, Seychelles. This is the same ASN GreyNoise previously reported on for producing roughly 10.7 million sessions the week of March 5–11, 2026 — before activity collapsed 97.7% overnight on March 7 and went quiet for most of the month. In the first week of April, the ASN came back: smaller fleet, tighter geography, single-protocol focus on RDP. Then, just as before, it crashed — dropping 99.9% in a single day and going fully silent by April 9.
On April 7, 21 IPs in AS213438 produced 1,856,167 RDP Crawler sessions — 67.4% of global RDP Crawler activity that day. Across a 48-hour window (April 5–7), the fleet accounted for 49.7% of the global total.
The RDP fleet concentrates in four /24 network blocks.
Total AS213438 volume scaled roughly 11x in 24 hours — from 180,293 sessions on April 6 to 2,011,365 sessions on April 7. RDP Crawler accounted for the overwhelming majority of this traffic.
The Netherlands' global share jumped from 7.17% to 53.86%. Romania's share fell from 29.89% to 15.78% — not because Romania dropped, but because the Netherlands grew ~15x and changed the denominator.
The fleet crashed on April 8 and went silent on April 9 — the same burst-and-crash pattern observed in March. RDP Crawler sessions from AS213438 fell from 1,856,167 on April 7 to 1,795 on April 8 to zero on April 9. Two burst-and-crash cycles from the same ASN, same IPs, same pattern, 30 days apart.
What the Data Does and Does Not Show
GreyNoise sensors observe unsolicited traffic hitting the public internet — scanning, probing, exploitation attempts, payload delivery, credential-harvesting requests, and RCE attempts. We do not observe successful compromises on real production systems. Every number in this post describes attacker activity reaching GreyNoise sensors, not confirmed impact on third-party environments.
GreyNoise does not attribute this activity to a named actor. ColocaTel Inc. is the RIPE-registered holder of AS213438. IP geolocation describes where infrastructure is routed, not where operators sit.
Why This Matters
For most of the past year, Romania was the largest single country-level source of RDP scanning traffic observed by GreyNoise. That changed in two days. Romania dropped from 29.89% to 15.78% of global share, and the Netherlands — where the 21 RDP fleet IPs are hosted — rose from 7.17% to 53.86%. AS213438 accounts for the majority of that country-level shift.
Two things make this notable. First, 21 IPs generating half of a global scanning category is not normal — typical source distributions are spread across thousands of IPs and hundreds of networks. Country-level or broad reputation feeds tuned to the old distribution are now pointing at the wrong place. Second, the same ASN was recently the loudest thing on the GOG, then fell silent, then came back smaller and narrower — and then crashed again. That repeating burst-and-crash rotation pattern is a defensive consideration on its own.
The Drop and the Resumption
The week of March 5–11, 2026, AS213438 was among the top source ASNs on the GOG, generating roughly 10.7 million sessions across mixed scanning behavior. On March 6, the ASN produced 3,756,496 sessions. On March 7, that figure crashed to 86,953 — a 97.7% single-day drop. The ASN stayed quiet through mid-March.
In the first week of April, it came back.
Date (UTC)
Sessions Observed
Mar 28
4,934
Apr 1
46,005
Apr 4
49,532
Apr 5
156,322
Apr 6
180,293
Apr 7
2,011,365
Apr 8
130,006
Apr 9 (through 17:17 UTC)
91,868
Figure 1 — Daily scanning activity from AS213438 (ColocaTel Inc.), Mar 28 to Apr 9, 2026. Bars show total sessions observed by GreyNoise (RDP Crawler accounted for ~85% of volume). Teal bars indicate the ramp and peak; rose bars show the crash. April 9 is partial-day data, through 17:17 UTC.
The April 7 jump is the operational detail: session volume went from 180,293 to 2,011,365 (11.1x) in a single day. By the end of April 7, AS213438 was the single largest source ASN for RDP Crawler activity on the GOG.
Then it crashed. The RDP Crawler fleet — the core of AS213438's activity — went from 1,856,167 sessions on April 7 to 1,795 on April 8, a 99.9% single-day drop. The last RDP Crawler session from AS213438 was observed at 2026-04-08T06:22:49Z. By April 9, the fleet had produced zero RDP Crawler sessions. The remaining AS213438 sessions on April 8–9 are non-RDP activity from other IPs in the same ASN.
This mirrors March exactly: a steep ramp, a volume peak, and then a near-total collapse overnight. Two burst-and-crash cycles from the same ASN, the same IP addresses, and the same operational pattern — 30 days apart.
A note on verification.
April 7's activity spike coincided with a routine change in GreyNoise's sensor observation infrastructure — the kind of change that can, in some cases, make traffic appear to increase when it hasn't actually changed. GreyNoise cross-checked the spike using five independent tests, including comparison against the structurally identical March spike (which involved no infrastructure change), per-sensor rate normalization, and peer-ASN isolation analysis. The result: the spike is real. It presents identically to earlier observed behavior that did not involve an infrastructure change.
The verification also surfaced something interesting about the fleet's scanning speed. When new observation points came online as part of the infrastructure change, AS213438 traffic appeared on them almost immediately — suggesting these IPs are scanning the internet aggressively enough that newly reachable hosts are discovered and probed within minutes.
The current activity profile is also narrower than early March's. Instead of mixed scanning, it is overwhelmingly focused on RDP:
Tag (as observed by GreyNoise)
Sessions in 48h
RDP Crawler
1,834,859
RDP Bruteforce Attempt
57,838
RDP Protocol
14,100
Web Crawler
6,122
Go HTTP Client
5,592
MySQL Protocol
3,067
MySQL Login Attempt
1,571
RDP Crawler alone accounts for roughly 85% of AS213438's total observed sessions in the window. Adding the other two RDP tags pushes the RDP-related share to ~88%.
Inside the Fleet
AS213438 had 32 active IP addresses in the 48-hour window, but only 21 of them are tagged by GreyNoise as RDP Crawler — the fleet behind the headline numbers. The remaining 11 IPs in the ASN are engaged in unrelated activity: web scanning, MySQL probing, Oracle WebLogic exploitation, and broad-spectrum reconnaissance.
The 21 RDP fleet IPs span four /24 network blocks:
Those four /24s hold 20 of the 21 RDP fleet IPs. One additional low-volume RDP Crawler IP (5.253.86[.]23, Lelystad) sits in a fifth /24. All 21 RDP fleet IPs are geolocated to the Netherlands.
The Amsterdam-and-Lelystad concentration, on infrastructure routed through a single ASN registered to one trading name, looks like hosting concentration — not a distributed botnet built from compromised devices. Two details reinforce that read:
Shared protocol fingerprints. GreyNoise observed the same TLS fingerprints across multiple higher-volume IPs in the fleet, consistent with centralized tool deployment. Commodity scanners with default configs could produce the same pattern.
A broad, non-standard port set. The fleet targets RDP on 3389 plus alternates 3390, 3391, 3392, and PostgreSQL on 5432 plus 5430, 5431, 5433, 5434, 15432, 25432, 30432, 35432, and 55432. The same alternate ports appearing across multiple IPs is consistent with a coordinated scanning configuration drawing from a shared target list.
Other Notable IPs in AS213438
One IP in the ASN — 31.56.110[.]107, geolocated to Colchester, UK — has been on GreyNoise's radar since May 2019 and operates as a broad-spectrum reconnaissance host classified as suspicious, not malicious. It is responsible for 259,925 of AS213438's 2,172,094 total sessions in the window, but contributes zero RDP Crawler sessions. The headline numbers are not affected by it: all RDP Crawler sessions come from the 21-IP RDP fleet, and the 67.4% global share holds whether you include the broader ASN or not.
The Country-Level Shift
RDP Crawler is one of the most consistent high-volume tags in the GreyNoise dataset. For months, Romania led it. Here is what the composition looks like now:
Country
14d Baseline (Mar 22 – Apr 5)
48h Window (Apr 5 – Apr 7)
Netherlands
7.17%
53.86%
Romania
29.89%
15.78%
United States
16.79%
7.37%
Russia
4.30%
6.25%
Bulgaria
7.74%
3.45%
All others
33.91%
13.29%
Figure 2 — Composition of global RDP Crawler activity observed by GreyNoise. The Netherlands' share rose from 7.17% to 53.86% in the 48-hour window, surpassing Romania as the top source country.
The Netherlands' daily rate went from ~64,894 sessions/day across the baseline to ~997,200 sessions/day in the window — a 15.4x increase. Romania's daily rate actually rose about 8% over the same comparison. Romania's share dropped because the Netherlands' volume grew much faster, not because Romania withdrew. This is a composition change driven by additive new volume.
For defenders, the effect is the same: any country-level RDP scanning weighting built from baselines before April 5 is misaligned with the current source distribution.
The ColocaTel Continuity
In the Ghost Fleet Hong Kong blog published March 25, 2026, GreyNoise reported on 109.205.211[.]101 — one of the most active source IPs in the dataset the week of March 12–18, 2026, producing roughly 7.97 million sessions (99.5% of which were RDP Crawler). That IP's route is announced by AS201814, a Polish hosting network operated by MEVSPACE sp. z o.o. The /24 containing it, however, is registered in RIPE WHOIS to an organization carrying the ColocaTel Inc. trading name at a Seychelles address.
Two RIPE organization records — one holding AS213438, one holding the /24 that contained 109.205.211[.]101 — are registered to the same ColocaTel Inc. name at the same Seychelles address (306 Victoria House, Victoria Mahe), with the same abuse contact (`abuse@colocatel.com`). The two records have distinct RIPE org IDs (ORG-CI158-RIPE and ORG-CI159-RIPE) and distinct maintainer handles, so GreyNoise cannot assert operational continuity from RIPE metadata alone. What we can say is that the same trading name, at the same Seychelles address, with the same abuse contact, has been linked to two separate high-volume RDP scanning incidents in GreyNoise data within the past 30 days — first on a /24 routed through MEVSPACE, now on /24s routed through AS213438 itself.
Recommendations
Security Operations
Add the four /24 blocks below to inbound RDP scanning watchlists or block rules. One rule materially reduces exposure.
Review authentication logs on internet-facing RDP services for activity from these blocks since April 5. Failed-auth patterns from these sources look like scanning, not users.
Audit non-standard RDP ports (3390, 3391, 3392) and non-standard PostgreSQL ports (5430–5434, 15432, 25432, 30432, 35432, 55432) on your edge.
Threat Intelligence
Track AS213438 for further profile shifts — it has now demonstrated two burst-and-crash cycles within 30 days, and the operational pattern suggests further rotations are likely.
Treat ColocaTel Inc. as a persistent registration identity worth tracking across RIPE records, not a single ASN.
Cross-reference the four /24s and AS213438 against pivot sets from the March Ghost Fleet HK reporting.
Security Leadership
Internet-facing RDP is continuously under scanning pressure regardless of which ASN is loudest that week. If you run it, assume it is being probed right now.
Country-level feeds that rank Romania, Russia, or China as the top RDP scanning sources are incomplete for this tag. The Netherlands has moved into the dominant position in this window.
Source Indicators (AS213438 / ColocaTel Inc.)
These are source IPs and CIDRs from which GreyNoise observed scanning. They are not compromise indicators — a match in outbound traffic from your environment is not evidence of infection. Treat them as inbound block/monitoring candidates.
Attribution note. GreyNoise does not attribute this activity to a named threat actor or nation-state. ColocaTel Inc. is the RIPE-registered organization for AS213438. The /24 holding the IP referenced from the prior Ghost Fleet HK reporting is registered to a separate RIPE organization carrying the same ColocaTel Inc. trading name and Seychelles address. IP geolocation describes where infrastructure is routed, not where operators are located. GreyNoise has not made contact with ColocaTel and cannot confirm whether the registered organization is aware of, complicit in, or unaware of the activity sourced from address space registered to its name.
Methodology. All counts come from the GreyNoise Observation Grid (GOG). The 48-hour window is April 5, 2026 19:49 UTC through April 7, 2026 19:49 UTC. The 14-day baseline is March 22, 2026 19:49 UTC through April 5, 2026 19:49 UTC. Daily figures for April 7 reflect a full UTC day of observations. "21 IPs" refers to the count of unique AS213438 source addresses tagged by GreyNoise as RDP Crawler during the observation window; the broader ASN had 32 active IPs, with the remainder engaged in unrelated scanning activity. RDP Crawler is a stable long-running GreyNoise behavioral tag — tag-deployment artifacts are not a factor here. AS213438 registration details were independently verified against RIPE WHOIS on April 7, 2026. Historical AS213438 activity from March 5–11, 2026 and the early-March drop are drawn from the Ghost Fleet Hong Kong blog, published March 25, 2026. Volume verification details are described in the body of this report.
When a firewall gets exploited, nothing happens, at least, nothing you can see. No EDR alert. No endpoint log. The device just quietly reaches out to an attacker-controlled server, downloads a payload, and waits for instructions.
From the attacker's perspective, access is established. From yours, it's Tuesday.
Edge and perimeter devices, routers, firewalls, VPN concentrators, are the most actively exploited assets on the internet right now. They're also the ones your security stack has the least visibility into. EDR doesn't run on them. Their native telemetry is sparse. And when they're compromised, the only evidence is an outbound connection buried somewhere in your firewall logs.
Today, we're launching C2 Detection, a new GreyNoise intelligence module that gives you two distinct, high-confidence signals that a device in your environment has been compromised.
Detect Compromise Through Outbound Traffic
C2 Detection is a new GreyNoise intelligence capability that surfaces the attacker-controlled infrastructure, malware-hosting servers, C2 nodes, and associated file hashes that compromised devices phone home to after a successful exploit.
Here's how it works: GreyNoise reads the exploit payloads that attackers send to its global sensor network and extracts the callback destinations embedded in those payloads. It then collects the malware hosted at those destinations and analyzes it to map the next stages of the attack chain — from staging servers to command-and-control infrastructure. This is payload-derived intelligence. GreyNoise doesn't need to wait for an exploit to succeed. It reads the payload directly, observes the post-exploitation chain, and delivers the results as a continuously updated dataset of confirmed callback IPs and associated malware hashes.
In the Visualizer, you'll see this as callback IP intelligence and malware hash data — two new layers that extend GreyNoise beyond inbound scanning into outbound threat detection.
Turn Outbound Traffic Into a Detection Signal
Detect active compromise from outbound traffic. Export your egress logs from edge devices and match destination IPs against the GreyNoise callback dataset. If there's a hit, the attack stage tells you how serious it is and what to do next.
Enrich your SIEM and SOAR with callback context. Pull callback stage and metadata via the API and use it to branch your playbooks. A Stage 1 match (confirmed file download) opens a case. A Stage 2 match (suspected C2 activity) triggers immediate escalation and containment.
Investigate historically. Callback infrastructure persists for weeks or months, far longer than scanning IPs. Use time range filters and the callback_ips query parameter to trace when GreyNoise first observed the infrastructure and which scanner IPs are linked to the same attack network.
Three Stages, One Severity Framework
Every callback IP is classified into one of three stages based on what GreyNoise has confirmed:
Stage
What It Means
Recommended Action
Unconfirmed
IP appeared in a payload, but no file was successfully downloaded.
Investigate. Don't escalate yet.
Stage 1: File Downloaded
GreyNoise confirmed this IP is actively serving file payloads.
Treat contacting devices as potentially compromised. Open a case.
Stage 2: C2 Suspected
Behavioral analysis including VirusTotal detections, sandbox network activity, and malware associations indicates active C2 infrastructure.
Assume active exploit presence. Escalate immediately.
This stage-based model gives you a built-in severity framework. Instead of a binary "good or bad," you get a signal calibrated to where the attacker is in their kill chain so your response matches the actual risk.
Two Signals. One Answer: You’re Compromised
C2 Detection strengthens a use case GreyNoise customers already know, detecting compromised assets by adding a second, independent signal:
Signal A (existing): Your organization's IP appears in GreyNoise as a scanner. That device has been recruited into a botnet and is scanning the internet on the attacker's behalf.
Signal B (new): Your outbound traffic matches a confirmed callback IP. That device is calling home to attacker-controlled infrastructure.
C2 Detection expands GreyNoise coverage beyond inbound activity, bringing high-confidence visibility into outbound communication with attacker-controlled infrastructure.
What This Adds to GreyNoise
This is entirely net-new. GreyNoise previously tracked only IPs actively scanning the internet, inbound threat intelligence. C2 Detection is the first GreyNoise capability focused on post-exploitation, outbound-facing threat intelligence. It introduces:
A new dataset: Callback IPs
A new classification model: Three attack stages
New data types: Malware files and hashes (with VirusTotal correlation)
A new query parameter: callback_ips
None of these existed in GreyNoise before.
Same Workflow. Stronger Signal.
If you're already enriching alerts with GreyNoise, the integration model doesn't change. The Callback IP dataset is accessed through the same API and Visualizer you already use. It's a different dataset, a different API call, but the workflow pattern is identical: take an IP, ask GreyNoise about it, act on the answer.
The difference is that Greynoise now extends beyond inbound activity to surface high-confidence signals from outbound traffic. What was once context is now a detection signal.
Start Using C2 Detection
C2 Detection is available as a dataset add-on for existing GreyNoise customers, with access delivered directly in the Visualizer and via API.
Already a customer? Contact your account team or email support@greynoise.io to enable access.
Not a customer? Get access with an Enterprise Trial.
GreyNoise observed 4 billion sessions targeting the edge over 90 days. The data challenges a core assumption of network defense: that you can tell attackers from legitimate users by where the traffic comes from.
What is a Residential Proxy
A residential proxy is a compromised home internet connection used as a disguise. Attackers route malicious traffic through ordinary home broadband, mobile data, and small-business connections — the same IP address ranges used by employees, customers, and partners. To a reputation feed, the source IP is indistinguishable from a legitimate user's connection — the same ISPs, the same address ranges.
What the Data Shows
39% of unique IPs targeting the edge come from home internet connections — nearly double their 22% share of sessions. Each residential IP averages fewer than 3 sessions before disappearing, and the median is just 1. They are everywhere, briefly.
78% of residential IPs are observed at most twice across the entire Global Observation Grid before rotating. By the time a reputation feed flags a residential IP, the malicious behavior has already rotated to a new address. The rotation rate makes feed-based detection structurally ineffective.
0.1% of residential sessions carry exploitation payloads, versus 1.0% from hosting infrastructure. Residential proxies map the terrain; the exploitation payloads come later from hosting infrastructure.
Traffic from IPs geolocating to India drops 34% between daytime peak and overnight trough. The most likely explanation is that the infected machines are physically powered off. Server traffic varies less than 3%. The device owners are victims — these are home PCs infected with worms, not willingly enrolled proxy nodes.
SMB worm propagation runs 84% residential, with zero overlap between SMB and Telnet source IP populations — confirming completely separate device populations rather than general-purpose scanning infrastructure.
Why This Matters
The residential proxy problem is not theoretical. Google Threat Intelligence Group disrupted IPIDEA in January 2026 — a network with 9 to 11 million daily active proxies used by over 550 distinct threat groups. The DOJ dismantled 911 S5 (19 million IPs across 190 countries) and indicted operators of AnyProxy/5Socks (over 7,000 proxies, $46 million in revenue). Mandiant M-Trends 2025 documented state actors routing operations through residential infrastructure. Every major takedown produces the same result — temporary disruption, then regeneration.
What's Inside the Report
The landscape: residential vs. hosting traffic at internet scale
The rotation economy: why IP reputation is structurally broken against residential proxies
The sleep cycle: circadian patterns in compromised home PCs
The supply side: worm propagation and IoT botnets as separate ecosystems
Commercial proxy fleets: SDK-enrolled devices as exit nodes
When networks die: ecosystem resilience after takedowns
The detection gap: what GreyNoise sees, what it cannot, and what defenders can do
The report presents both the data and its limitations — including a Censys ground-truth validation and an explicit discussion of what GreyNoise can and cannot observe.
Last week, the GreyNoise Observation Grid (GOG) observed something unusual: 242,666 new scanning IPs geolocating to Hong Kong appeared in seven days — nearly half of all new scanning IPs observed by GreyNoise that week. And 99.7% of them never completed a single TCP connection.
These IPs are ghosts — they appeared in GreyNoise data but never proved they were real. Because they never completed a TCP handshake, GreyNoise cannot verify that the traffic actually originated from those addresses. They carried no payloads, triggered no detection signatures, and performed no exploitation. All they left behind were a quarter-million unverified IP addresses now sitting in observation datasets.
Geographic references throughout this post describe where IPs are registered, not where the traffic necessarily originated or where operators are located.
Here's why that matters: any detection system that observed this traffic and doesn't distinguish between verified and unverified source addresses just absorbed a quarter-million ghost IPs into its dataset. Meanwhile, the 702 IPs geolocating to Hong Kong that actually completed connections — the ones observed scanning MySQL, SSH, SMB, and RDP, hitting GOG sensors in 20+ countries — could easily get lost in the noise. One provider alone, UCLOUD, surged 472% in session volume to become the largest ASN by session volume in GreyNoise data, with 38% of its IPs classified malicious. That's the signal. The other 242,000 IPs are the noise.
On top of that, the entire scanning landscape reshuffled last week. A top ASN disappeared overnight. Traffic from IPs geolocating to Australia dropped 72%. New infrastructure geolocating to Poland and Germany appeared. The scanning sources that dominated the prior week were not the same ones that dominated last week.
Key Findings
242,666 new IPs geolocating to Hong Kong — 48.9% of all new scanning IPs observed by GreyNoise last week. 99.7% never completed a TCP handshake.
One organization, GNET INC., contributed 143,340 IPs — 28.9% of all new IPs observed by GreyNoise. Zero were classified malicious.
Only 702 IPs geolocating to Hong Kong (0.3%) completed TCP handshakes. Of those, 362 are classified malicious.
UCLOUD (AS135377) surged +472% in session volume, becoming the top ASN by session volume in GreyNoise data — with only 1,746 IPs but 38% classified malicious.
The scanning landscape rotated: a top ASN from the prior week disappeared entirely, traffic from IPs geolocating to Australia dropped 72%, and new infrastructure geolocating to Poland and Germany appeared.
The Ghost Fleet
Between March 12 and 18, GreyNoise observed 242,666 new IPs geolocating to Hong Kong — nearly equal to the rest of the world combined (253,646). Six hosting providers account for 93.3%:
Organization
ASN
New IPs
Spoofable
Malicious
Tags
GNET INC.
AS9294
143,340
99.998%
0
Virtually none
Yancy Limited
AS138415
34,051
99.998%
1
Virtually none
Cloudie Limited
AS55933
20,517
99.91%
45
Minimal
Zillion Network Inc.
AS54801
10,329
—
—
—
LARUS Limited
AS17561
9,433
100%
0
None
Netsec Limited
AS45753
8,759
99.96%
1
Minimal
Figure 1: New IPs geolocating to Hong Kong, by organization. GNET INC. alone contributed 28.9% of all new IPs observed by GreyNoise.
When GreyNoise labels an IP "spoofable," it means the IP was observed sending traffic but never completed a TCP three-way handshake — the source address is unverified. Of these 242,666 IPs, 241,964 are spoofable. They are classified "unknown," categorized as "hosting" infrastructure (92.3%), and carry almost no GreyNoise tags.
One Organization, 143,340 IPs, Zero Malicious
GNET INC. (AS9294) is the single largest contributor — one organization that added 28.9% of all new IPs observed by GreyNoise in a single week:
Metric
Value
Total active IPs (including pre-existing)
163,051
Spoofable
99.998% (only 3 completed TCP handshakes)
Classification
100% unknown
Malicious IPs
0
GOG sensor countries reached
Primarily United States
Tags
QUIC Protocol on 30 IPs. Nothing else.
No exploitation. No brute-force activity. No web crawling. Incomplete connections only.
Names That Don't Match Registration Geography
Several ghost fleet entities are registered under names that don't align with where their IPs geolocate:
Entity
ASN
Total IPs
Discrepancy
LUOGELANG (FRANCE) LIMITED
AS135097
62,617
"France" in name — 0% of IPs geolocate to France (62% HK, 38% US)
LARUS Limited
AS17561
19,687
Split between Hong Kong (9,832) and Russia (8,751)
Taiwan Li Run Ltd
AS131147
5,119
"Taiwan" in name — 4,096 IPs geolocate to mainland China, 1,023 to Hong Kong
The Signal Behind the Noise: UCLOUD
The ghost fleet is the noise. The signal is UCLOUD (AS135377).
Spoofable vs. non-spoofable IPs geolocating to Hong Kong — 242,000 IPs that did not complete TCP handshakes vs. 702 that did.
UCLOUD contributes just 1,746 IPs — 0.4% of the active IPs geolocating to Hong Kong in GreyNoise data. But it accounts for an outsized share of observed scanning and exploitation attempts:
The contrast is stark. The entity generating 82x more IPs (GNET INC.) has zero classified malicious. The entity generating 82x fewer IPs (UCLOUD) has 663 — observed scanning MySQL, SSH, SMB, and RDP, with traffic reaching GOG sensors in more than 20 countries.
The Volume Surge
UCLOUD's session volume went from 9.7 million to 55.4 million in one week — displacing DigitalOcean as the top ASN by session volume in GreyNoise data:
Week
UCLOUD Sessions
DigitalOcean Sessions
UCLOUD Rank
Mar 5-11
9,679,761
31,361,945
#3
Mar 12-18
55,384,799
22,709,383
#1
Change
+472%
-27.6%
Figure 4: Daily session counts showing UCLOUD overtaking DigitalOcean as the top ASN by session volume in GreyNoise data.
The Rotation: Everything Shifted in Seven Days
The ghost fleet wasn't the only change. The entire scanning landscape observed by GreyNoise reshuffled. AS213438, a top ASN the prior week with 10.7 million sessions, disappeared entirely — an abrupt shutoff consistent with infrastructure being decommissioned or rotated.
What declined (source refers to IP geolocation; destination refers to GOG sensor location):
Source (by IP geolocation)
Mar 5-11
Mar 12-18
Change
Australia to US
4,109,617 sessions
1,153,593
-71.9%
Netherlands to US
17,886,273
12,952,923
-27.6%
Netherlands to Spain
5,540,230
3,112,579
-43.8%
Canada to US
3,649,150
2,454,528
-32.7%
What appeared (source refers to IP geolocation; destination refers to GOG sensor location):
Source (by IP geolocation)
Mar 5-11
Mar 12-18
Change
Hong Kong to US
4,744,912
15,427,214
+225%
Poland to Spain
312,708
8,325,850
+2,563%
Hong Kong to Spain
1,410,537
7,117,338
+405%
Thailand to US
966,313
5,468,241
+466%
Nigeria to US
559,975
2,863,781
+411%
Lithuania to US
1,523,952
5,300,605
+248%
Bulgaria to US
1,496,734
3,444,281
+130%
Figure 5: Week-over-week changes in scanning traffic by source-destination pair, as observed by GreyNoise.
Under the Hood
Cross-referencing GreyNoise observations with Censys internet-wide scan data and VirusTotal reputation data reveals infrastructure patterns not visible from any single source.
Templated deployment across borders.
A cluster on infrastructure geolocating to Germany, registered to a Seychelles entity, shows configurations consistent with deployment from a single VM image. A separate Windows VPS cluster uses IPs geolocating to Bulgaria, Romania, and France across three ASNs with an identical service configuration on each node — scanning infrastructure deployed from a common template.
UCLOUD relay infrastructure.
Censys data reveals purpose-built traffic relay and tunneling software deployed across UCLOUD at a density not typical of legitimate hosting. Repeating non-standard port configurations appear identically across multiple subnets — the signature of a single VM template deployed at scale.
Low reputation detection.
The top scanning IPs are barely flagged:
IP
Provider
Vendor Detections
Notable
109.205.211[.]101
MEVSPACE / Colocatel Inc. (AS201814)
2 of 94
Zero communicating files. 7.97M sessions/week. IPs geolocate to Poland; registered to Colocatel Inc. (Seychelles).
79.124.58[.]146
Tamatiya EOOD (AS50360)
5 of 94
IPs geolocate to Bulgaria. Self-signed SSL cert: localhost.localdomain by "VMware Installer"
91.238.181[.]10
Fbw Networks SAS (AS49434)
7 of 94
IPs geolocate to France. Communicating file: mssecsvr.exe (Win32, first seen 2018). Malicious history predating current activity.
What We Don't Know
GreyNoise cannot determine the purpose of the ghost fleet from GreyNoise data alone. Censys confirms these ASNs are active hosting ecosystems — the spoofable traffic uses source addresses in IP ranges distinct from the legitimate hosted infrastructure. What we can say: 242,666 IPs appeared, almost none completed connections, and the source addresses are unverified.
What Defenders Should Do
Detection stacks that don't distinguish spoofable IPs from confirmed scanners may be affected. 242,666 unverified source addresses now exist in observation datasets. Systems that weight activity by IP count without verifying connections should be reviewed.
Update blocklists. The sources that dominated scanning the prior week declined or disappeared, replaced by infrastructure geolocating to Hong Kong, Poland, and Germany — all within seven days.
Monitor UCLOUD (AS135377). GreyNoise observed multi-protocol scanning activity targeting MySQL (3306), SSH (22), SMB (445), and RDP (3389).
Track the ghost fleet ASNs for behavioral changes: AS9294, AS138415, AS55933, AS135097, AS17561, AS45753. If these IPs begin completing TCP handshakes and deploying payloads, the assessment changes.
GreyNoise is not attributing this activity to a named threat actor or state sponsor. The geographic references in this post describe where IPs are registered, not necessarily where the operators are located. Hosting infrastructure is routinely used by actors with no geographic connection to the provider's registration.
GreyNoise integration with Google Security Operations enables improved dashboards, detection rules, playbooks, and webhook support
Your SIEM ingests everything. Every port scan, every crawl, every opportunistic spray across the internet. The problem isn't the collection — it's context. Which of those IPs are scanning everyone, and which ones are targeting you?
That's the question GreyNoise answers. We observe over over 800,000 unique IPs daily across 5,000+ sensors in 80+ countries, classifying each as malicious, suspicious, benign, or unknown, and tagging them with 3,000+ behavioral descriptors. Traditional threat feeds add more indicators to investigate. GreyNoise removes the ones that don't matter.
Today, we're announcing a new and improved integration with Google Security Operations — delivering standardized indicator ingestion, pre-built dashboards, YARA-L detection rules, saved searches, response actions, webhook support, and ready-to-deploy playbooks.
What's New: Event Management
New Ingestion Script
The GreyNoise ingestion script is now available in Google Security Operations ingestion-scripts repository — a standardized process for importing threat intelligence indicators into your environment. Deployed as a Google Cloud function, it pulls IP reputation data and GNQL query results from the GreyNoise API and ingests them via the Google Security Operations API. The default configuration focuses on malicious IPs observed in the last 24 hours, but teams can customize the GNQL query to match their threat profile.
New Dashboards
Two interactive dashboards ship with the integration into Google Security Operations:
Indicator Dashboard — 15+ visualization panels covering classification distribution (Malicious, Suspicious, Benign, Unknown), top 10 rankings for organizations, actors, tags, ASNs, categories, operating systems, and source countries, plus CVE distribution, trend analysis, and business service intelligence.
GreyNoise Indicator Dashboard in Google Security Operations
Correlation Dashboard — Shows IOC matches between GreyNoise intelligence and events from your environment, with geolocation mapping, event match trends, classification breakdowns, and top IP indicator rankings.
GreyNoise Correlation Dashboard in Google Security Operations
Indicators broken down by classification
New YARA-L Detection Rules
Three ready-to-deploy rules that start correlating immediately:
IP Match — Detects events where a source or principal IP matches a malicious or suspicious GreyNoise indicator, correlating over a 1-hour window.
Inbound Network Traffic with ASN Context — High-severity rule monitoring firewall logs for permitted inbound connections from GreyNoise-flagged malicious IPs, enriched with ASN attribution.
Brute Force Attack Detection — High-severity rule flagging 5+ blocked login attempts from GreyNoise-flagged IPs within a 15-minute window.
New Saved Searches
Four pre-built UDM queries for investigation workflows:
IP Risk & Vulnerability Details — Classification, anonymization signals, CVEs, and activity timelines
Indicator Context Summary — Actor attribution, geographic details, organizations, and tags
High Risk Indicators — Filters for MALICIOUS or SUSPICIOUS classifications only
All Indicator Lookup — Browse all ingested GreyNoise indicators for ad-hoc investigation
IOC Geolocation Overview — mapping matched indicators globally
What's New: Response Workflows
Updated Response Actions (v7.0)
The GreyNoise response integration has been updated to version 7.0 with the full suite of actions:
Action
What It Does
IP Lookup
Full enrichment — classification, tags, metadata
Quick IP Lookup
Fast context check on any IP
IP Timeline Lookup
Historical view of scanning behavior over time
Execute GNQL Query
Run arbitrary GreyNoise queries within a playbook
Get CVE Details
Vulnerability context from exploitation activity
Ping
Validate API connectivity
New Webhook Support
A major addition: webhook support for ingesting GreyNoise alerts and event feeds directly into Google Security Operations. Three webhook types are now available:
IP Change Webhook — Tracks classification changes in real time
CVE/Tag Webhook — Monitors CVE spikes, status changes, vendor activity, and tag spikes
New Playbooks
Pre-built playbooks ship with the integration, providing ready-made automation workflows that teams can deploy or customize. Combined with the webhook connectors and the Generate Alert from GreyNoise GNQL connector, security teams can build end-to-end automated triage pipelines.
On-demand IP Lookup
How It Works Together
1. Ingest — The event management integration continuously pulls GreyNoise indicators into Google Security Operations with fresh scanner data.
2. Detect — YARA-L detection rules flag events that correlate with known scanners. Dashboards provide visual context.
3. Investigate — Saved searches surface IP risk details, actor attribution, and CVE context without writing queries.
4. Respond — Response playbooks enrich flagged IPs automatically. Mass scanners get deprioritized. Targeted activity escalates for review.
Webhooks close the loop by pushing GreyNoise alerts — including classification changes and CVE spikes — directly into Google Securioty Operations for quick action.
Who Has Access
This integration is available to any joint Google Security Operations customer with a GreyNoise API key. No additional licensing required — just configure and go.
Learn More and Get Started
Ready to bring GreyNoise intelligence into your Google Security Operations environment? Learn more here:
Every SOC analyst knows the feeling: another morning, another queue of hundreds of alerts, and the gnawing question of which ones actually matter. The volume of internet background noise — automated scanners, research probes, vulnerability crawlers — hasn’t slowed down. If anything, it’s accelerating. And as adversaries adopt AI to move faster, the cost of chasing the wrong signals isn’t just frustrating — it’s dangerous.
That’s the problem GreyNoise was built to address. We operate one of the largest passive sensor networks on the internet — more than 5,000 sensors across 80 countries, analyzing up to one billion sessions per day and tracking over 50 million IPs. That scale lets us classify internet-wide scanning and reconnaissance activity with confidence: which IPs are known benign scanners, which are actively malicious, and which are unknown — meaning we haven’t observed them scanning the internet indiscriminately.
That classification data is now available across the CrowdStrike Falcon platform — in Next-Gen SIEM, Falcon Fusion SOAR, and the agentic workflows that are defining the next era of security operations.
GreyNoise Intelligence Across CrowdStrike Falcon
For teams running Falcon, GreyNoise intelligence is operationalized across three integrated capabilities — inline investigation context in Next-Gen SIEM, automated enrichment and response in Falcon Fusion SOAR, and agentic collaboration through Charlotte AI.
Falcon Next-Gen SIEM: GreyNoise Classification Inside Your Existing Queries
The GreyNoise Foundry App — available directly on the CrowdStrike Marketplace — is the operational core of the integration. Once installed, it automatically imports a fresh GreyNoise indicator lookup file into Next-Gen SIEM every day. No manual feed management. No stale data.
That lookup file contains GreyNoise’s full dataset of classified IPs — benign scanners, malicious actors, CVE-targeting sources, and tagged threat infrastructure. Inside Next-Gen SIEM, analysts use the match() function to incorporate that data directly into their searches and analytics. GreyNoise classification columns — classification, observed activity, exploited CVEs — surface right alongside event data in the query view, with no pivot to an external tool required.
Detections tied to IPs that GreyNoise has identified as active exploit sources or malicious infrastructure stand out. Teams can build correlation rules and dashboards that weight GreyNoise-validated threats higher. And IPs that GreyNoise has classified as benign — known research scanners, internet measurement services, well-documented security vendors — carry that context right in the query results, giving analysts the information they need to make confident triage decisions.
The Foundry App ships with a pre-built app template containing GreyNoise threat intelligence actions, ready to deploy in Foundry and extend into Fusion SOAR workflows.
Falcon Fusion SOAR: Automated Enrichment and Response
Knowing an IP is malicious is useful. Acting on that intelligence automatically is where the efficiency gain lives.
The GreyNoise Foundry App includes a native Falcon Fusion SOAR integration that puts GreyNoise enrichment directly into workflow logic. Security teams can build — or extend — automated playbooks that take action based on GreyNoise IP context:
Alert on malicious IPs — trigger high-priority notifications when GreyNoise identifies adversary activity at the perimeter
Prioritize vulnerability response — surface CVE exploitation data to inform which vulnerabilities need immediate patching attention
Initiate threat hunts — automatically kick off hunt workflows when GreyNoise identifies coordinated scanning tied to known threat infrastructure
Automate blocking or containment — close the loop on confirmed malicious IPs
GreyNoise’s benign classification is particularly valuable here. Because GreyNoise classifies known-good IPs — security researchers, CDN health checks, legitimate vulnerability scanners — SOAR workflows have a higher-confidence basis for automated routing decisions. That confidence is grounded in what our sensor network directly observes, not aggregated from third-party sources.
Charlotte AI: GreyNoise as a Trusted Ecosystem Participant
CrowdStrike’s blog on building an agentic security workforce names GreyNoise among the trusted ecosystem participants supported in Charlotte AI’s Agentic Response Collaboration capability — alongside Corelight, ExtraHop, Proofpoint, Google, Abnormal AI, and Zscaler. These integrations provide what CrowdStrike describes as “deep cross-domain context to drive faster, more accurate analysis.”
Charlotte AI’s use of ecosystem data is still maturing, and we’ll share more as it develops. But the direction is clear: as agentic workflows become a core part of how SOC investigations run, GreyNoise intelligence can be part of the reasoning loop.
Here’s what that looks like in practice. An alert fires on a suspicious external IP. Charlotte AI’s Detection Triage Agent is working the case. As part of its investigation, GreyNoise context is available: Is this IP part of a known mass scanner campaign? Has it been observed exploiting the specific vulnerability that generated the alert? Is it tied to active threat infrastructure? That intelligence informs the agent’s triage decision — contributing internet-wide scanning context to a process that already draws from endpoint, identity, and cloud telemetry.
Charlotte AI’s agentic response can trigger workflows in Falcon Fusion SOAR, which means GreyNoise intelligence already available in your SOAR playbooks carries naturally into AI-driven triage. CrowdStrike’s mission-ready agents — covering detection triage, malware analysis, exposure prioritization, and threat hunting — are trained on years of expert decisions from Falcon Complete analysts. GreyNoise’s classification data adds internet-wide reconnaissance context to those workflows.
What Falcon Users Get
GreyNoise intelligence across the Falcon platform produces three specific outcomes:
Higher-confidence triage — GreyNoise classification gives analysts a clear signal on which external IPs are known internet scanners and which warrant deeper investigation
Contextualized alerts — every IP-based detection carries GreyNoise behavior, classification, and CVE context from the moment it fires
Faster investigation and response — inline enrichment and automated SOAR workflows compress the time from alert to action
Prioritized vulnerability response — CVE exploitation intelligence from GreyNoise’s sensor network informs which vulnerabilities are being actively targeted right now
Getting Started
The GreyNoise Foundry App is available on the CrowdStrike Marketplace for Falcon Next-Gen SIEM and Falcon Insight XDR customers. Installation takes minutes, and the daily automated indicator import requires no ongoing maintenance.
GreyNoise observed 84,142 scanning sessions targeting SonicWall SonicOS infrastructure between February 22 and February 25, 2026. The activity originated from 4,305 unique IP addresses across 20 autonomous systems, with three operationally distinct infrastructure clusters executing coordinated VPN enumeration. Ninety-two percent of sessions probed a single API endpoint to determine whether SSL VPN is enabled — the prerequisite check before credential attacks. A commercial proxy service delivered 32% of campaign volume through 4,102 rotating exit IPs in two surgical bursts totaling 16 hours. CVE exploitation was negligible, confirming this as systematic attack surface mapping.
Why This Matters
SonicWall SSL VPN is one of the most documented initial access vectors for ransomware. Akira and Fog ransomware groups have repeatedly demonstrated that compromised SonicWall VPN credentials lead to full encryption in under four hours — with dwell times as short as 55 minutes. Five of seven SonicWall CVEs relevant to this attack surface appear in CISA's Known Exploited Vulnerabilities catalog, with four having documented ransomware use. The reconnaissance GreyNoise observed is the precursor phase — systematic target mapping that precedes exploitation.
Since March 2023, Akira alone has compromised at least 250 organizations and generated an estimated $244 million in ransomware proceeds, with 75% of SonicWall VPN intrusions attributed to Akira and 25% to Fog. More than 430,000 SonicWall firewalls are publicly exposed on the internet, with over 25,000 SSL VPN devices vulnerable to critical flaws and 20,000 running firmware that is no longer supported.
This is not the first time GreyNoise has observed this pattern. In December 2025, GreyNoise documented a coordinated credential campaign targeting both Palo Alto and SonicWall VPN infrastructure across 9 million sessions from more than 7,000 IPs, sharing identical client fingerprints across both vendors. The February 2026 campaign represents a continuation and intensification of VPN-focused reconnaissance.
Key Takeaways
84,142 sessions from 4,305 IPs in four days — Coordinated reconnaissance targeting SonicWall VPN enumeration and credential testing endpoints indicates systematic attack surface mapping
92% of sessions probed a single API endpoint — The VPN status check determines which devices have SSL VPN active, creating a target list for future credential attacks
32% of volume routed through a commercial proxy service — 4,102 exit IPs delivered 27,119 sessions in two surgical bursts, averaging 6.6 sessions per IP to evade rate-limiting
Multi-vendor VPN reconnaissance — The Netherlands scanning cluster simultaneously targets SonicWall and Cisco ASA devices, indicating a broader VPN mapping operation
Reconnaissance dominates — 92% of sessions targeted a single VPN status-check endpoint, confirming systematic target mapping rather than active exploitation
Defenders should act now — Restrict management interface access, enforce MFA on SSL VPN, and patch CVE-2024-53704 (CVSS 9.8, CISA KEV) before reconnaissance converts to exploitation
What GreyNoise Observed
Campaign Timeline
The campaign exhibited four distinct bursts separated by a ∼31-hour low-activity period, with a persistent credential-testing baseline running continuously underneath.
Burst 1 — Initial Scan Wave (Feb 22, 00:00–19:00 UTC): The campaign opened with a 19-hour scanning wave peaking at 3,272 sessions per hour. This burst combined proxy infrastructure with the Netherlands scanning cluster, totaling 30,952 sessions on the first day.
Low-Activity Period (Feb 22 21:00 – Feb 24 04:00 UTC, ∼31 hours): Session volume dropped to a 54–90 session/hour baseline — exclusively the persistent NetExtender credential testing cluster operating on autopilot.
Burst 2 — Proxy Resurgence (Feb 24, 04:00–12:00 UTC): The proxy infrastructure reactivated for a focused 8-hour window, delivering 17,991 sessions through rotating exit IPs. Per-IP volume remained extremely low (average 6.6 sessions, maximum 13), consistent with a proxy service rotating exit nodes.
Burst 3 — Peak Hour (Feb 24, 15:00–17:00 UTC): 7,374 sessions in the 15:00 UTC hour — the single highest hourly count of the entire campaign — followed by 5,484 in the 16:00 hour. This burst originated from the Netherlands scanning cluster, not the proxy pool.
Burst 4 — Final Surge (Feb 25, 08:00–13:00 UTC): A final burst peaked at 5,899 sessions in the 11:00 UTC hour, indicating ongoing orchestration.
Date
Sessions
February 22
30,952
February 23
1,639 (baseline only)
February 24
32,616 (peak — three bursts)
February 25
18,935 (partial day)
The dramatic February 23 lull — a 95% drop from the preceding day — is operationally significant. The scanning infrastructure did not fail; the persistent NetExtender cluster continued uninterrupted at its normal rate. The pause suggests deliberate operational scheduling.
What Is Being Targeted
Two SonicWall-specific paths dominate the campaign, accounting for over 99.5% of all sessions:
Target
Sessions
%
Purpose
SonicOS REST API — VPN status check
77,253
91.8%
Determines whether SSL VPN is enabled
NetExtender VPN client login endpoint
6,629
7.9%
Credential testing via legitimate VPN client
Other management paths
260
0.3%
Various admin endpoints
The overwhelming concentration on the VPN status API endpoint reveals the campaign’s objective: building a comprehensive list of SonicWall devices with active SSL VPN. This is a prerequisite for credential attacks — identifying which devices are worth targeting before deploying more expensive proxy resources for login testing.
Four Infrastructure Clusters
Cluster 1: Netherlands VPN Hunters (28% of Campaign)
Six IPs within a single Ukrainian-registered autonomous system (AS211736) operating from Amsterdam-based infrastructure delivered 23,794 sessions. These IPs run dual-vector scanning: VPN status enumeration paired with Cisco ASA reconnaissance, indicating a multi-vendor VPN mapping operation.
Censys infrastructure profiling revealed these nodes run identical software stacks. All share a single HASSH fingerprint, confirming deployment from a common provisioning template. Four of the six expose HTTP services on ports 7001–7003 with identical bare-minimum 404 responses — consistent with a custom scanning framework spawning worker threads.
IP
ASN
Sessions
Also Scans
88[.]210[.]63[.]78
AS211736
4,669
Cisco ASA
185[.]156[.]73[.]19
AS211736
4,620
Cisco ASA
185[.]156[.]73[.]73
AS211736
4,491
Cisco ASA
88[.]210[.]63[.]77
AS211736
4,340
Cisco ASA
185[.]156[.]73[.]31
AS211736
4,333
Cisco ASA
88[.]210[.]63[.]79
AS211736
1,341
Cisco ASA
Cluster 2: Commercial Proxy Spray (32% of Campaign)
27,119 sessions originated from 4,102 IP addresses in the 154[.]208[.]64[.]0/21 range, transiting through AS3257 (GTT Communications) from Canadian hosting infrastructure.
The proxy service — ByteZero (bytezero[.]io) — markets itself as offering 100+ million IPs across 150+ countries for web scraping and data collection. The scanning traffic originates from ByteZero’s paying customers, not the proxy infrastructure itself. ByteZero is the anonymization layer enabling the activity.
The proxy usage was surgical — concentrated in two primary windows:
Window
Duration
Sessions
Feb 22, 00:00–06:00 UTC
7 hours
8,019
Feb 24, 04:00–12:00 UTC
9 hours
17,991
A critical detail: ByteZero’s customer management platform went offline in early December 2025. The proxy nodes have continued operating for approximately three months without active abuse mitigation. This directly explains the unchecked scanning volume.
Cluster 3: The Mega-Scanner (22% of Campaign)
A single IP — 130[.]12[.]180[.]29 on AS202412 (Omegatech, registered in the Seychelles), geolocating to Germany — generated 18,763 sessions. This IP scanned across 20+ destination ports including non-standard ports (6666, 7777, 7443, 9443), cycling through 26 different browser user agents to evade basic fingerprinting.
Cluster 4: NetExtender Persistent (8% of Campaign)
156 IPs across four dedicated ranges maintain continuous credential testing at 54–72 sessions per hour against the NetExtender VPN login endpoint. This cluster uses a legitimate SonicWall VPN client identifier and never stops — it ran uninterrupted through the February 23 low-activity period. Total: 6,629 sessions over four days.
Fingerprint Analysis
A single HTTP fingerprint was present in 58,510 sessions — nearly 70% of the entire campaign. The associated user agent presents as a modern browser (Chrome 119 on Linux) but is paired with HTTP/1.0, a protocol version that legitimate Chrome browsers never use. This mismatch is a reliable, high-confidence indicator of automated scanning tooling.
Fingerprint
Sessions
%
Behavior
4-header GET, HTTP/1.0, Chrome UA
58,510
69.5%
NL cluster + proxy (VPN enum)
17-header GET, HTTP/1.1, rotating UAs
18,763
22.3%
Mega-scanner
6-header POST, HTTP/1.1, NetExtender
6,629
7.9%
Credential testing
Exploitation Assessment
Despite the reconnaissance volume, the campaign's behavioral profile is overwhelmingly pre-exploitation. 92% of sessions queried a single API endpoint to determine VPN status — a prerequisite check, not an exploit. GreyNoise maintains CVE-specific detection tags for six of the seven CVEs below; CVE-2024-40766 does not currently have a detection tag.
CVE
CVSS
CISA KEV
Ransomware Use
Campaign Sessions
CVE-2024-53704
9.8
Yes
Yes
5
CVE-2024-40766
9.8
Yes
Yes (Akira, Fog)
No tag
CVE-2022-22274
9.8
No
No
9*
CVE-2023-0656
7.5
No
No
9*
CVE-2021-20028
9.8
Yes
Yes
8
CVE-2024-38475
9.1
Yes
Unknown
6
CVE-2019-7481
7.5
Yes
Yes
6
*CVE-2022-22274 and CVE-2023-0656 are detected by the same GreyNoise tag ("SonicOS RCE Attempt"). The 9 campaign sessions apply to both CVEs collectively.
Four of the five CISA KEV entries have documented ransomware use. The behavioral profile of this campaign — 92% concentrated on a single VPN status-check endpoint — is consistent with pre-exploitation reconnaissance rather than active exploitation. The targets identified during this mapping phase are likely to face exploitation attempts in the days and weeks ahead.
Strategic Implications
The use of commercial proxy services for VPN reconnaissance represents a maturation of the threat. Unlike botnets with fixed infrastructure, proxy services provide rotating datacenter IP addresses that are difficult to distinguish from legitimate traffic. The low per-IP session volume — averaging 6.6 sessions per exit node — is calibrated to evade rate-limiting and reputation-based blocking. Static blocklists cannot keep pace with infrastructure that rotates thousands of IPs within a single scan window.
The headless state of the proxy service — operating for three months without active abuse oversight after its management platform went offline — highlights a structural gap in the proxy ecosystem. When proxy providers lose the ability or incentive to police their customers’ traffic, their infrastructure becomes functionally equivalent to bullet-proof hosting.
This pattern is accelerating. In January 2026, Google disrupted IPIDEA — a residential proxy network used by over 550 threat groups including nation-state APTs — for credential stuffing and C2 obfuscation. The Shadowserver Foundation has tracked a separate campaign using 2.8 million IPs daily to brute-force VPN login portals. The proxy ecosystem has become the primary enabler of credential-based initial access.
Organizations running SonicWall firewalls should treat this reconnaissance as an early warning. The documented Akira ransomware kill chain begins with compromised SonicWall VPN credentials and achieves encryption in under four hours. SonicWall itself has confirmed that recent intrusions resulted from password reuse combined with CVE exploitation. The gap between the reconnaissance GreyNoise is observing and the exploitation that follows may be shorter than many organizations’ patching cycles.
Check If Your SonicWall Was Targeted (5 Minutes)
Step 1 — Check your logs (2 minutes). Search firewall logs for external requests to these paths between February 22–25:
/api/sonicos/is-sslvpn-enabled (VPN status check)
/sonicui/7/login/ (management interface)
/cgi-bin/userLogin (VPN credential testing)
Step 2 — Check active VPN sessions (1 minute). Navigate to NETWORK | SSL VPN > Status in SonicOS 7.x. Look for sessions from IP addresses outside your user base, particularly from hosting or VPS providers.
Step 3 — Verify firmware and MFA (2 minutes). Confirm your SonicOS firmware is patched against CVE-2024-53704 (versions at or below 7.1.1-7058, 7.1.2-7019, or 8.0.0-8035 are vulnerable). Confirm MFA is enabled for all SSL VPN users.
If your SonicWall was probed and you are running end-of-life SRA appliances, disconnect them immediately — CVE-2021-20028 and CVE-2019-7481 have no patches available.
Recommendations
For Security Leadership:
Audit SonicWall management interface exposure — administrative endpoints should never be internet-accessible
Verify MFA is enforced on all SSL VPN users — credential stuffing is rendered ineffective by MFA
Evaluate dynamic blocklists to address the IP rotation that makes static lists ineffective against proxy-based campaigns
Treat VPN infrastructure as a priority patching tier — the reconnaissance-to-exploitation gap is narrowing
For Security Operations:
Restrict access to /sonicui/7/login/ and /api/sonicos/ paths to trusted management IPs only
Monitor for HTTP/1.0 requests paired with modern browser user agents — this combination is a high-confidence indicator of automated scanning
Block identified scanning infrastructure at the perimeter:
154[.]208[.]64[.]0/21 (proxy exit nodes)
185[.]177[.]72[.]0/24 (bullet-proof hosting)
185[.]156[.]73[.]0/24 and 88[.]210[.]63[.]0/24 (scanner fleet)
204[.]76[.]203[.]0/24 (scanning with credential collection indicators)
Reset all local user account passwords, especially those carried over during Gen 6 to Gen 7 migrations
Decommission end-of-life SRA appliances — no patches are available for CVE-2021-20028 or CVE-2019-7481
Enable login attempt lockout and password complexity enforcement (SonicOS 7.3+)
SonicWall administrators running SonicOS 7.3.2 or NSM SaaS also have access to the Credential Auditor feature, which provides visibility into credential sprawl and reuse across the firewall environment
Enable Geo-IP filtering and Botnet Protection on the firewall
View real-time GreyNoise data on SonicWall activity:
GreyNoise analyzed 2.97 billion sessions over 162 days in H2 2025, and the patterns reveal where edge defenses hold up — and where they fall short. The data exposes specific concentration points in VPN targeting, infrastructure sourcing, and exploitation behavior that challenge conventional defensive assumptions.
What the Data Shows
Across the GreyNoise Global Observation Grid, several findings challenge conventional assumptions about where attacks concentrate:
Palo Alto GlobalProtect received 16.7 million sessions — more than 3.5x Cisco and Fortinet combined. This disproportionate concentration warrants investigation, though direct market share comparison was not part of this analysis. GlobalProtect deployments provide direct network access if compromised, making them high-value targets.
52% of remote code execution attempts came from IPs with no prior history in GreyNoise data. For remote code execution — widely considered the highest-severity exploitation category — GreyNoise had no prior record of more than half the attacking IPs. That means attackers are spinning up and burning through fresh infrastructure faster than any static threat feed can catalog it — and GreyNoise detected these IPs the moment they first appeared, before any other source had them.
Pre-2015 CVEs generated 7.3 million sessions — 4x more than 2023-2024 CVEs combined. One vulnerability — CVE-1999-0526, a 26-year-old X Server information disclosure — accounts for the majority. Even excluding it, Shellshock and PHP-CGI continue generating measurable traffic a decade later. Patching programs optimized for recency leave decade-old exposure unaddressed.
300,000 residential IPs participated in a single credential-spraying campaign — 73% classified as residential by ISP categorization, with no prior GreyNoise history. Geographic blocking, reputation scoring, rate limiting: would have limited effectiveness against this traffic pattern.
91,403 sessions targeted AI/LLM infrastructure. The same types of automated scanning patterns hitting VPNs and routers are now cataloging exposed LLM endpoints.
Why This Matters
The Verizon 2025 DBIR documented an 8x increase in edge device exploitation in a single year — edge vulnerabilities jumped from 3% to 22% of all vulnerability exploitation breaches. Mandiant M-Trends 2025 found the top four most frequently exploited vulnerabilities were all in edge devices — Palo Alto PAN-OS, Ivanti Connect Secure, Ivanti Policy Secure, and Fortinet FortiClient EMS. CISA issued Binding Operational Directive 26-02, requiring federal agencies to address end-of-support edge devices. The GreyNoise data is consistent with all of it — and quantifies the scale.
This isn't a theoretical shift. If your organization runs internet-facing VPN appliances, routers, or AI infrastructure, this traffic is reaching you.
What's Inside the Report
The full report includes:
Vendor-by-vendor breakdown of VPN, router, and firewall targeting
Infrastructure concentration analysis — how a single provider accounted for 14% of all observed sessions
The residential botnet that grew from 2,000 to 300,000 IPs in 72 days
CVE age distribution showing where exploitation actually concentrates versus where patching effort concentrates
Infrastructure freshness analysis across attack severity categories
An emerging campaign targeting AI/LLM inference servers
Actionable recommendations for security leadership, operations, and vulnerability management
On February 10, a proof-of-concept exploit for CVE-2026-1731, a critical pre-authentication remote code execution vulnerability in BeyondTrust Remote Support and Privileged Remote Access, was posted to GitHub. By February 11, GreyNoise’s Global Observation Grid was recording reconnaissance probing for vulnerable BeyondTrust instances.
What Is CVE-2026-1731?
CVE-2026-1731 is an OS command injection flaw (CVSS v4: 9.9) that lets an unauthenticated attacker execute arbitrary commands on a BeyondTrust Remote Support or Privileged Remote Access server. No credentials required. No user interaction needed. Low complexity to exploit.
It's a variant of CVE-2024-12356, the same vulnerability class that Chinese state-sponsored group Silk Typhoon used to breach the U.S. Treasury Department in late 2024. Same WebSocket endpoint, different code path.
BeyondTrust patched cloud customers automatically on February 2. Self-hosted customers need to update manually to RS v25.3.2+ or PRA v25.1.1+.
What GreyNoise Observed
Our global sensor network, a passive collection of sensors that observe and classify internet-wide scanning and reconnaissance activity, detected a clear surge beginning February 11, 2026. This is the reconnaissance phase; what comes next is predictable.
Four Things That Stand Out
1. One scanner dominates
A single IP accounts for 86% of all observed reconnaissance sessions so far. It's associated with a commercial VPN service hosted by a provider in Frankfurt and has been an active scanner in our data since 2023. This isn't a new actor; it's an established scanning operation that rapidly added CVE-2026-1731 checks to its toolkit.
2. They're not hitting port 443
Standard BeyondTrust deployments run on HTTPS (port 443), but few sessions target that port. The rest systematically probed clusters of non-standard ports, suggesting the attackers know that enterprises often move BeyondTrust to non-default ports for security-through-obscurity.
3. JA4+ fingerprints reveal shared tooling and VPN tunneling
GreyNoise captures JA4+ fingerprints on every session. At the TCP layer, 100% of sessions show Linux stack characteristics. The dominant scanner's TCP fingerprint has an MSS of 1358 (vs. the standard 1460), confirming VPN tunnel encapsulation at the network layer and independently validating the VPN association. At the HTTP layer, two distinct exploit tools are in use: one lightweight 5-header tool shared by the top 5 IPs (including all 4 classified as malicious), and a 7-header variant used by 10 different single-session scanners. Neither tool matches any known application in the JA4 fingerprint database. One session even shows a loopback MSS (65495), a distinctive operational artifact.
4. These are multi-exploit actors
The IPs performing reconnaissance for CVE-2026-1731 aren't single-purpose. While their BeyondTrust activity is a check (enumeration), their GreyNoise profiles show they're simultaneously conducting active exploitation attempts against other products: SonicWall, MOVEit Transfer, Log4j, Sophos firewalls, SSH brute-forcing, and IoT default-credential testing. Some IPs are even using out-of-band callback domains (OAST), a more sophisticated technique to confirm vulnerability before delivering payloads.
The BeyondTrust Pattern
BeyondTrust's remote access tools occupy a uniquely sensitive position. They're designed to manage privileged access to enterprise networks. When they're compromised, attackers don't just get a foothold; they get the keys to the castle.
Dec 2024 │ CVE-2024-12356 — Silk Typhoon breaches U.S. Treasury
│ via BeyondTrust zero-day (same WebSocket endpoint)
│
Jan 2026 │ GreyNoise sensors catch a malicious IP replaying the
│ exact Treasury breach exploit chain (CVE-2024-12356 +
│ CVE-2025-1094 SQLi)
│
Feb 2026 │ CVE-2026-1731 — Variant discovered by AI-assisted
│ analysis. PoC drops. Recon begins within 24 hours.
│
??? │ What comes next?
Before CVE-2026-1731 even existed, the old exploit chain was still in active use.
On January 5, we observed a Polish hosting provider running the same BeyondTrust RCE + PostgreSQL SQLi chain that Silk Typhoon used against the Treasury, all targeting the /nw WebSocket path on port 443. That IP shares a TLS fingerprint with the new CVE-2026-1731 scanners and also targets SimpleHelp, another remote support product. 26 days later, the new variant was discovered, and by February 11, a fresh set of actors had already begun mapping targets.
See It for Yourself in GreyNoise
GreyNoise customers can track this activity in real time:
The tag was deployed on February 10 and is actively classifying new reconnaissance IPs as they appear. Customers get full IP context, JA4+ fingerprint analysis, behavioral profiling, timeline data, and the complete IOC list for blocking.
Not a GreyNoise customer? You can look up individual IPs against our dataset at viz.greynoise.io and see classification data for free.
The Bottom Line
CVE-2026-1731 follows a predictable but dangerous pattern: critical disclosure, rapid PoC, and immediate reconnaissance. The last time a BeyondTrust pre-auth RCE went unpatched, a nation-state actor exploited it to breach a U.S. government agency.
The GreyNoise Global Observation Grid observed active exploitation of two critical Ivanti Endpoint Manager Mobile vulnerabilities, and 83% of that exploitation traces to a single IP address on bulletproof hosting infrastructure that does not appear on widely circulated IOC lists. Meanwhile, several of the most-shared IOCs for this campaign show zero Ivanti exploitation in GreyNoise data. They are scanning for Oracle WebLogic instead. Defenders blocking only the published indicators may be watching the wrong door.
Why This Matters
The infrastructure actually conducting Ivanti EPMM exploitation at volume is an IP on a Censys-labeled "BULLETPROOF" autonomous system running simultaneous campaigns against four different software products. It is absent from the IOC lists many defenders adopted in the days after disclosure. The IOCs that are circulating point to shared VPN exit nodes conducting unrelated scanning and a compromised residential router with zero internet-wide activity. Organizations that relied solely on those indicators may have detection gaps against the exploitation GreyNoise is observing right now.
Key Takeaways
Single dominant source. 83% of observed exploitation comes from one IP on bulletproof hosting (PROSPERO OOO, AS200593). This IP is not on widely published IOC lists, meaning defenders blocking only published indicators are likely missing the dominant exploitation source.
Published IOCs show zero Ivanti activity. The /24 subnet containing four published Windscribe VPN IOC IPs generated 29,588 sessions in 30 days, with 99% targeting Oracle WebLogic on port 7001, not Ivanti. Zero Ivanti EPMM exploitation sessions from this range in GreyNoise data.
Blind RCE verification, not immediate deployment. 85% of exploitation payloads use OAST DNS callbacks to verify command execution. This indicates a campaign cataloging vulnerable targets for later exploitation, consistent with initial access broker tradecraft.
Exploitation is accelerating. 269 sessions on February 8 alone, up from a daily average of 21. Defenders with unpatched, internet-facing EPMM instances should assume they have been scanned and investigate for signs of compromise.
For GreyNoise customers: An IOC package and executive situation report (SITREP) for CVE-2026-1281 have been delivered to your inbox. Check your email for the full package, including indicators, detection guidance, and a board-ready summary.
The Vulnerability and Timeline
CVE-2026-1281 is a CVSS 9.8 (v3.1) unauthenticated remote code execution vulnerability in Ivanti Endpoint Manager Mobile. It exploits Bash arithmetic expansion in EPMM’s file delivery mechanism, allowing an unauthenticated attacker to execute arbitrary commands on the underlying server. Ivanti also disclosed CVE-2026-1340 (CVSS 9.8), a related code injection flaw in a different EPMM component.
On January 29, three things happened on the same day: Ivanti published its advisory, CISA added CVE-2026-1281 to the Known Exploited Vulnerabilities catalog with a three-day remediation deadline, and Dutch authorities later confirmed that the Dutch Data Protection Authority (AP) and the Council for the Judiciary (RVDR) had been compromised via Ivanti EPMM. By January 30, watchTowr Labs had published a full technical analysis, and proof-of-concept code appeared on GitHub shortly after. NHS England, CERT-EU, and NCSC-NL also issued advisories confirming active exploitation.
Vendor disclosure, CISA KEV listing, and confirmed government compromise occurred on a single day. By the time most organizations saw the advisory, exploitation was already underway against real targets.
What GreyNoise Sensors Observed
GreyNoise first detected CVE-2026-1281 exploitation attempts on February 1, three days after disclosure. Between February 1 and February 9, GreyNoise sensors recorded 417 exploitation sessions from 8 unique source IPs.
Date
Sessions
Note
Feb 1
2
First exploitation observed
Feb 2
26
Primary source escalates
Feb 3
9
Continued probing
Feb 4
26
Second source appears
Feb 5
8
Third source appears
Feb 6
35
Multiple IPs active
Feb 7
41
Continued escalation
Feb 8
269
Sharp spike
Feb 9
1
As of publication
The February 8 spike is notable: 269 sessions in a single day, roughly 13 times the daily average of the preceding week. This pattern of sustained low-level activity followed by a sharp escalation suggests either expanded targeting scope or retooling by the primary source.
The 8 Source IPs
Source IP
Ivanti Sessions
Organization
ASN
Infrastructure Location
193[.]24[.]123[.]42
346 (83%)
PROSPERO OOO
AS200593
Russia
45[.]129[.]230[.]38
26
ColocaTel Inc.
AS213438
Netherlands
198[.]98[.]54[.]209
26
FranTech Solutions
AS53667
United States
156[.]146[.]45[.]26
8
Datacamp Limited
AS212238
Hong Kong
198[.]98[.]56[.]220
8
FranTech Solutions
AS53667
United States
3 additional IPs
1 each
Various
—
—
IP geolocation reflects infrastructure registration, not operator location. GreyNoise is not attributing this activity to a specific threat actor.
The Dominant Source: PROSPERO OOO
One IP generated 346 of 417 observed exploitation sessions. 193[.]24[.]123[.]42, registered to PROSPERO OOO (AS200593) and geolocating to Saint Petersburg, Russia, accounts for 83% of all Ivanti EPMM exploitation in GreyNoise telemetry. Censys identifies this autonomous system with a confidence-scored "BULLETPROOF" label.
This IP does not appear on the widely circulated IOC lists for this campaign.
A Multi-CVE Exploitation Platform
This is not a single-purpose host. GreyNoise telemetry shows 193[.]24[.]123[.]42 simultaneously exploiting four different CVEs across unrelated software:
CVE
Target Software
Sessions
CVE-2026-21962
Oracle WebLogic
2,902
CVE-2026-24061
GNU Inetutils Telnetd
497
CVE-2026-1281
Ivanti EPMM
346
CVE-2025-24799
GLPI (IT Asset Management)
200
The IP rotates through 300+ unique user agent strings spanning Chrome, Firefox, Safari, and multiple operating system variants. This fingerprint diversity, combined with concurrent exploitation of four unrelated software products, is consistent with automated tooling.
For additional context: Trustwave SpiderLabs has previously documented connections between PROSPERO and the Proton66 network (AS198953), linking both to bulletproof hosting services marketed on Russian-language cybercrime forums under the BEARHOST brand. That network has been associated with distribution infrastructure for GootLoader, SpyNote, and other malware families. This does not confirm attribution of the Ivanti campaign to any specific threat actor, but it places the dominant exploitation source on infrastructure with a documented history of hosting malicious operations.
85% of Exploitation Uses Blind RCE Verification
Of 417 exploitation sessions, 354 (85%) triggered GreyNoise’s out-of-band application security testing (OAST) interaction domain detection. The payloads instruct the target to generate a DNS callback to a unique subdomain, a technique that confirms command execution without requiring a direct response back to the attacker.
Because GreyNoise can observe not just that exploitation was attempted, but what the payload does when it runs, we see a clear pattern. In this case, 85% of payloads do one thing: phone home via DNS to confirm "this target is exploitable." They do not deploy malware. They do not exfiltrate data. They verify access.
That pattern is significant. OAST callbacks indicate the campaign is cataloging which targets are vulnerable rather than deploying payloads immediately. This is consistent with initial access operations that verify exploitability first and deploy follow-on tooling later.
What Happens After: The 403.jsp Sleeper Shells
External research corroborates this interpretation. On February 9, Defused Cyber reported a campaign deploying dormant in-memory Java class loaders to compromised EPMM instances at the path /mifs/403.jsp. The implants require a specific trigger parameter to activate, and no follow-on exploitation was observed at the time of their report. Defused Cyber assessed this as consistent with initial access broker tradecraft: establish a foothold, then sell or hand off access later.
The GreyNoise OAST data and the Defused Cyber findings point in the same direction. The exploitation GreyNoise observes is focused on cataloging and staging access, not on immediate deployment. For defenders, this means compromised systems may appear unaffected right now. The sleeper shells are designed to wait.
Note: The OAST patterns described above reflect what GreyNoise sensors observed. The Defused Cyber findings describe activity on production systems. Both datasets point in the same direction but represent different vantage points on the campaign.
Published IOCs in GreyNoise Data
Several widely published IOCs for this campaign do not appear in Ivanti EPMM exploitation attempts observed by GreyNoise sensors. GreyNoise does observe activity from these IPs, but targeting different vulnerabilities entirely.
Four published IOC IPs (.151, .156, .137, .134) sit in a /24 block on M247 infrastructure (AS9009) in Amsterdam. Censys shows this block contains 95 hosts: a dense cluster of commercial VPN exit nodes, including Windscribe IKE endpoints with certificates carrying anti-censorship domain names.
In GreyNoise data, 99% of this subnet’s traffic targets Oracle WebLogic on TCP port 7001. It does not target Ivanti EPMM.
Metric
Value
Subnet sessions (30 days)
29,588
Dominant target
TCP/7001 (Oracle WebLogic)
Ivanti EPMM CVE-2026-1281 sessions
0
GreyNoise tags fired across /24
1 (Generic Path Traversal Attempt)
All four IOC IPs appear to be “dark” exit nodes: Censys detects zero inbound services on any of them. They exist to funnel outbound VPN traffic. Two of the four (.137, .134) have zero sessions in GreyNoise over the past 30 days.
This matters because these are shared VPN exits used by many subscribers for many purposes. The WebLogic scanning GreyNoise observes from this range may originate from a different VPN user than the Ivanti-related activity that prompted the original IOC listing. Blocking these IPs is a defensible decision, but defenders should understand that these indicators carry higher false-positive risk than dedicated exploitation infrastructure.
Separately, on February 5, Dutch authorities seized a Windscribe VPN server in the Netherlands as part of an undisclosed investigation. Windscribe disclosed the seizure, noting that its RAM-only (diskless) server architecture means no user data would be recoverable. No public reporting has linked the seizure to the Ivanti EPMM campaign.
A Compromised Residential Router (151[.]177[.]78[.]0)
One published IOC IP has never appeared in GreyNoise telemetry. Censys identifies 151[.]177[.]78[.]0 as an ASUS router on Tele2 residential broadband in Gothenburg, Sweden, running outdated firmware with an exposed cloud management interface and a factory-default certificate.
Its absence from GreyNoise data is itself informative. GreyNoise operates 5,000+ sensors across 80+ countries that observe internet-wide scanning and exploitation. An IP conducting broad exploitation would almost certainly appear. Zero sessions suggest this IP was used exclusively for targeted activity directed at specific systems, consistent with compromised residential infrastructure being used as an exit proxy.
For defenders who implemented the published IOCs: if you blocked the Windscribe VPN range (185[.]212[.]171[.]0/24) but not AS200593 (PROSPERO), your defenses may have addressed secondary infrastructure while missing the primary exploitation source in GreyNoise telemetry.
Strategic Implications
IOC-based defenses face a fundamental confidence problem in this campaign. Published indicators ranged from shared VPN infrastructure (low confidence, high false-positive risk) to bulletproof hosting with concentrated exploitation activity (high confidence, low collateral). Organizations applying uniform blocklist policies to all published IOCs are either over-blocking legitimate traffic or under-blocking actual threats. The 83% concentration on a single PROSPERO-hosted IP, while published IOCs showed zero overlap with GreyNoise exploitation data, demonstrates that post-incident IOC sharing can miss the infrastructure actually used at volume. Defenders benefit from a confidence-scoring framework for IOCs that accounts for infrastructure type, observed behavior concentration, and temporal proximity to the vulnerability window.
The OAST callback pattern and the Defused Cyber sleeper shell findings together suggest that initial exploitation is only the first phase. If this campaign follows the initial access broker model, compromised EPMM instances may not show obvious signs of abuse for weeks or months. Organizations that patched quickly but did not investigate for prior compromise during the exposure window may have dormant implants in their environment. The absence of visible post-exploitation activity is not evidence of safety.
Mobile device management platforms represent a target class with compounding risk. EPMM compromise provides access to device management infrastructure for entire organizations, creating a lateral movement platform that bypasses traditional network segmentation. Organizations running MDM platforms should treat these systems with the same criticality as domain controllers or identity providers, including network isolation, aggressive patch cycles, and monitoring for unauthorized configuration changes or device enrollments.
The exploitation timeline has compressed below the threshold of conventional patch management. Same-day government compromise and a 72-hour gap to widespread scanning leaves no buffer for "patch this weekend" strategies. Organizations with internet-facing MDM, VPN concentrators, or other remote access infrastructure should operate under the assumption that critical vulnerabilities face exploitation within hours of disclosure.
Recommendations
For Security Leadership:
Audit whether Ivanti EPMM and other MDM infrastructure is directly internet-facing. MDM platforms manage entire device fleets; their compromise exposure is disproportionate to a single server. Consider placing MDM behind VPN or zero-trust network access.
Evaluate your IOC ingestion workflow. Are indicators enriched with infrastructure context before being added to blocklists? The difference between a bulletproof hosting IP and a shared VPN exit node is the difference between a high-confidence block and a potential false positive.
If your EPMM instance was internet-facing and unpatched between January 29 and your patch date, commission an investigation. The sleeper shell tradecraft observed in this campaign means compromise may not be visible through normal monitoring.
For Security Operations:
Block AS200593 (PROSPERO OOO) at the network perimeter. This autonomous system accounts for 83% of observed Ivanti EPMM exploitation and carries a Censys BULLETPROOF designation. GreyNoise dynamic blocklists can help maintain coverage as exploitation infrastructure shifts.
Review DNS logs for OAST-pattern callbacks: unique, high-entropy subdomains resolving to known OAST interaction infrastructure. These indicate that exploitation payloads executed on your systems.
Monitor for the /mifs/403.jsp path on EPMM instances. This is the sleeper shell location identified by Defused Cyber. Its presence indicates compromise even if no further malicious activity is visible.
Consider restarting EPMM application servers to clear in-memory implants that may have been staged. In-memory class loaders do not survive a process restart.
For Ivanti EPMM Administrators:
Apply patches for CVE-2026-1281 and CVE-2026-1340 immediately. Exploitation is active and accelerating.
If your instance was unpatched and internet-facing at any point between January 29 and your patch date, investigate for indicators of compromise: unexpected files at /mifs/403.jsp, anomalous outbound DNS activity, unfamiliar Java processes, and any evidence of unauthorized administrative actions on managed devices.
Review whether EPMM needs to accept connections from the open internet. Where architecturally feasible, restrict access to known network ranges or require VPN authentication before reaching the EPMM interface.
There is a critical gap in defense: the window between when an attacker starts hammering a specific vendor’s infrastructure and when a specific CVE is assigned or a signature is written.
In that window, defenders are often flying blind, waiting for a vulnerability disclosure to tell them what to look for. But the network noise is often already there. The most dangerous threats don't always start with a named vulnerability—they start with a sudden, coordinated shift in attacker behavior toward a specific technology stack.
Today, we are closing that visibility gap by expanding GreyNoise Event Feeds with two new signals: Vendor CVE Spike and Tag Spike.
These new feed types allow you to monitor the behaviors and technologies that matter to your environment, without needing to manually track every individual vulnerability or signature.
1. Vendor CVE Spike
Individual CVEs and tags are continually added, updated, and deprecated as new research emerges. This creates significant overhead and potential blind spots if your team attempts to track these changes manually.
The Vendor CVE Spike feed reduces this complexity by alerting only when exploitation activity across a vendor meaningfully increases.
How it helps: This feed is designed to help you focus on when attacker interest spikes, rather than managing lists of specific CVEs. As vulnerabilities and tags associated with a vendor evolve, the feed updates its coverage to include them, ensuring you are monitoring the broader technology stack rather than just static indicators.
Use Cases:
Vendor-wide vulnerability monitoring: Monitor all CVE exploitation activity across a vendor's products without manually tracking individual CVEs as they are published.
Patch prioritization: Prioritize patching cycles based on vendor-level exploitation trends. A spike in activity for your firewall vendor signals it is time to accelerate remediation.
Proactive threat hunting: Use vendor spikes as an early warning signal to investigate whether associated CVEs have been attempted against your environment.
Real-World Context: The Fortinet & Palo Alto Surge
Attackers often target the technology stack, not just a single bug. In our analysis from the week of January 19, 2026, GreyNoise sensors observed a coordinated campaign targeting enterprise VPN infrastructure. Specifically, we saw a significant elevation in targeting of both Fortinet SSL VPNs and Palo Alto GlobalProtect portals.
This activity validates findings from our Early Warning Signals research: vendor-level spikes—whether from credential stuffing, scanning, or exploitation of older vulnerabilities—often precede the disclosure of new CVEs for that same vendor. A Vendor CVE Spike would have flagged this anomaly, providing the early warning needed to enforce tighter MFA controls or geo-blocking before the specific threat was fully characterized.
How It Works:
Setting up a Vendor CVE Spike is designed to be a "set and forget" workflow that integrates directly into your existing Event Feeds. When you search for a vendor name (e.g., "Palo Alto"), the feed uses wildcard matching to find all tags containing that term. It then resolves those tags to their associated CVEs and monitors activity for those CVEs.
Create a Feed: In the GreyNoise Visualizer, navigate to the Event Feeds section.
Name Your Feed: Assign your feed a recognizable name (e.g., "Critical [Vendor] Monitor").
Select Spike Type: Choose Vendor CVE Spike from the available signals.
Define Threshold: Select the vendor you want to monitor and set the activity threshold that matters to you.
Connect: Add your webhook link (SIEM, SOAR, etc.).
Test & Save: Verify the connection and save the feed.
Watch the video below to see Vendor CVE Spike in action:
2. Tag Spike
Sometimes, the threat isn't a specific vulnerability—it is a behavior, a tool, or a botnet. Tag Spike feeds allow you to monitor for sudden increases in activity associated with specific GreyNoise tags directly.
How it helps: Tag Spike lets you monitor activity for specific threats, botnets, or scanning behaviors directly by tag name. Unlike Vendor CVE Spike, which resolves matching tags to their associated CVEs, Tag Spike tracks the tags themselves. This is essential for tracking threats where a CVE may not yet be assigned.
Use Cases:
Monitoring emerging exploit activity: Track activity for specific products or vendors before CVEs are assigned.
Tracking specific threats: Monitor botnets (e.g., "Mirai"), scanners, or malware families by tag name.
Early warning detection: Get notified when threat actors ramp up scanning for specific technologies.
How It Works:
You define a tag or keyword (e.g., "Mirai," "Worm," or "Cisco"), and the feed uses wildcard matching to find all tags containing that term. GreyNoise then watches for significant changes in IP counts for tags matching your filter criteria over a rolling 2-hour window.
Create a Feed: In the GreyNoise Visualizer, click Create Feed.
Name Your Feed: Give it a clear name (e.g., "Mirai Botnet Tracker").
Select Event Type: Choose Tag Spike.
Define Threshold: Enter the tag or keyword you want to monitor (e.g., mirai) and set the percentage increase threshold.
Connect: Paste your webhook URL.
Watch the video below to see Tag Spike feed in action:
💡 Quick Tip: Which feed should I use?
Use Vendor CVE Spike if you want to track exploits. (e.g., "Tell me if Palo Alto products are being exploited via any CVE.")
Use Tag Spike if you want to track behaviors or botnets. (e.g., "Tell me if the Mirai botnet is active" or "Tell me if worm behavior is spiking.")
Access and Availability
Vendor CVE Spike and Tag Spike are available now in the GreyNoise Visualizer.
Who has access: These feeds are available to Advanced and Elite platform customers with the appropriate data modules.
Where to find it: Navigate to the Feeds tab in the Visualizer to configure your first alert.
For GreyNoise Customers: A comprehensive IOC package with extended infrastructure, network fingerprints, and connected domains was sent directly to customers via email.
Two months after CVE-2025-55182 was disclosed on December 3, 2025, exploitation activity targeting React Server Components has consolidated significantly. GreyNoise telemetry from the past seven days shows that two IP addresses now account for 56% of all observed exploitation attempts, down from 1,083 unique sources.
The dominant sources deploy distinct post-exploitation payloads: one retrieves cryptomining binaries from staging servers, while the other opens reverse shells directly to the scanner IP. Whether this represents two separate actors or compartmentalized infrastructure from a single actor remains unclear, but the behavioral distinction is notable.
Why This Matters
CVE-2025-55182 is a CVSS 10.0 pre-authentication remote code execution vulnerability with a public Metasploit module. Exploitation requires only a single HTTP POST request. The payloads GreyNoise observed on its sensors are not reconnaissance scans but active exploitation attempts deploying cryptominers and reverse shells. Organizations running unpatched React Server Components should assume they have been targeted.
Key Findings
Two IPs generated 56% of exploitation traffic over the past seven days (January 26 to February 2, 2026)
193.142.147[.]209 accounted for 488,342 sessions (34%)
87.121.84[.]24 accounted for 311,484 sessions (22%)
1,083 unique source IPs observed during this period
Post-exploitation payloads include XMRig cryptominers and reverse shells on port 12323
Exploitation Activity
GreyNoise sensors recorded 1,419,718 exploitation attempts targeting CVE-2025-55182 over the seven-day observation period. The following table summarizes the dominant sources:
Source IP
Sessions
Share
Post-Exploitation
193.142.147[.]209
488,342
34%
Reverse shell (port 12323)
87.121.84[.]24
311,484
22%
XMRig cryptominer
The remaining 44% of traffic was distributed across 1,081 other source IPs.
Post-Exploitation Behavior
The two dominant sources exhibit different post-exploitation patterns, suggesting different operational objectives.
Cryptomining operation (87.121.84[.]24): Successful exploitation triggers retrieval of an XMRig binary from staging servers at 205.185.127[.]97 and 176.65.132[.]224. GreyNoise captured both the dropper script and ELF binary on vulnerable honeypots. Both staging servers serve identical payloads.
Reverse shell operation (193.142.147[.]209): Successful exploitation opens a reverse shell directly to the scanner IP on port 12323 without using a staging server. This approach suggests interest in interactive access rather than automated resource extraction.
JA4H fingerprint analysis confirms different HTTP client implementations between the two sources. Full fingerprint data is available to GreyNoise customers.
Infrastructure Analysis
Pivoting on the cryptomining staging server revealed infrastructure with extended history. The primary staging server (205.185.127[.]97) has hosted attacker-controlled domains since at least 2020 according to SSL certificate records:
September 2020: mased[.]top subdomains
November 2021: mercarios[.]buzz
January 2022: bt2.radiology[.]link
WHOIS records show shared registrant information across these domains, with registration dates extending back to 2018.
Adjacent IP addresses in the same /24 as the scanner (87.121.84[.]25 and 87.121.84[.]45) are currently serving Mirai and Gafgyt variants targeting MIPS and ARM architectures, along with exploit scripts for consumer routers and DVRs.
Vulnerability Background
CVE-2025-55182 was disclosed on December 3, 2025 and affects React Server Components. The vulnerability carries a CVSS score of 10.0. The flaw exists in how serialized data is processed, allowing an attacker to send a malicious POST request that the server deserializes and executes without authentication or user interaction.
A Metasploit module was published shortly after disclosure, contributing to rapid exploitation uptake. GreyNoise first observed exploitation attempts on December 5, 2025.
Affected versions: React 19.0.0, 19.1.0 through 19.1.1, 19.2.0
Patched versions: React 19.0.1, 19.1.2, 19.2.1
Targeting Patterns
Port distribution indicates focus on development infrastructure:
Port
Sessions
Common Use
443
417,546
HTTPS
80
357,018
HTTP
3000
282,803
Default React development server
3001
99,248
Alternative development port
3002
66,771
Alternative development port
8080
47,018
Development and proxy servers
React development servers configured with --host 0.0.0.0 for network accessibility are particularly exposed when internet-facing.
Recommendations
Patch immediately. Upgrade to React 19.0.1, 19.1.2, or 19.2.1. If immediate patching is not possible, disable React Server Components.
Block known infrastructure. Add the following IPs to blocklists:
193.142.147[.]209
87.121.84[.]24
205.185.127[.]97
176.65.132[.]224
Hunt for historical connections. Review network logs for connections to these IPs since early December 2025.
Audit development infrastructure. Verify that React development servers are not exposed to the internet. The --host 0.0.0.0 flag should only be used on isolated networks.
Monitor for indicators. Watch for POST requests containing unusual Next-Action headers in web server logs.


.png)


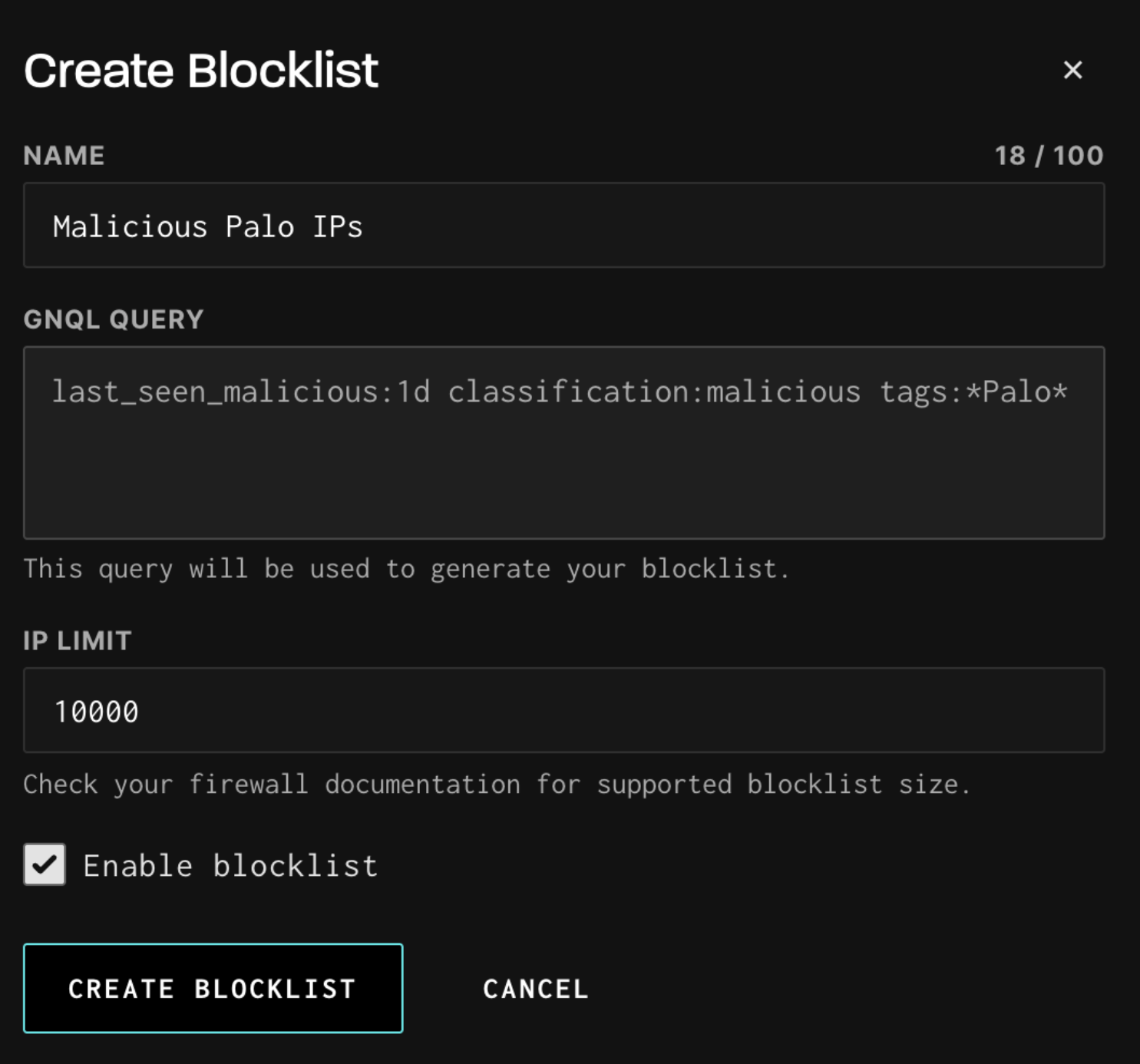

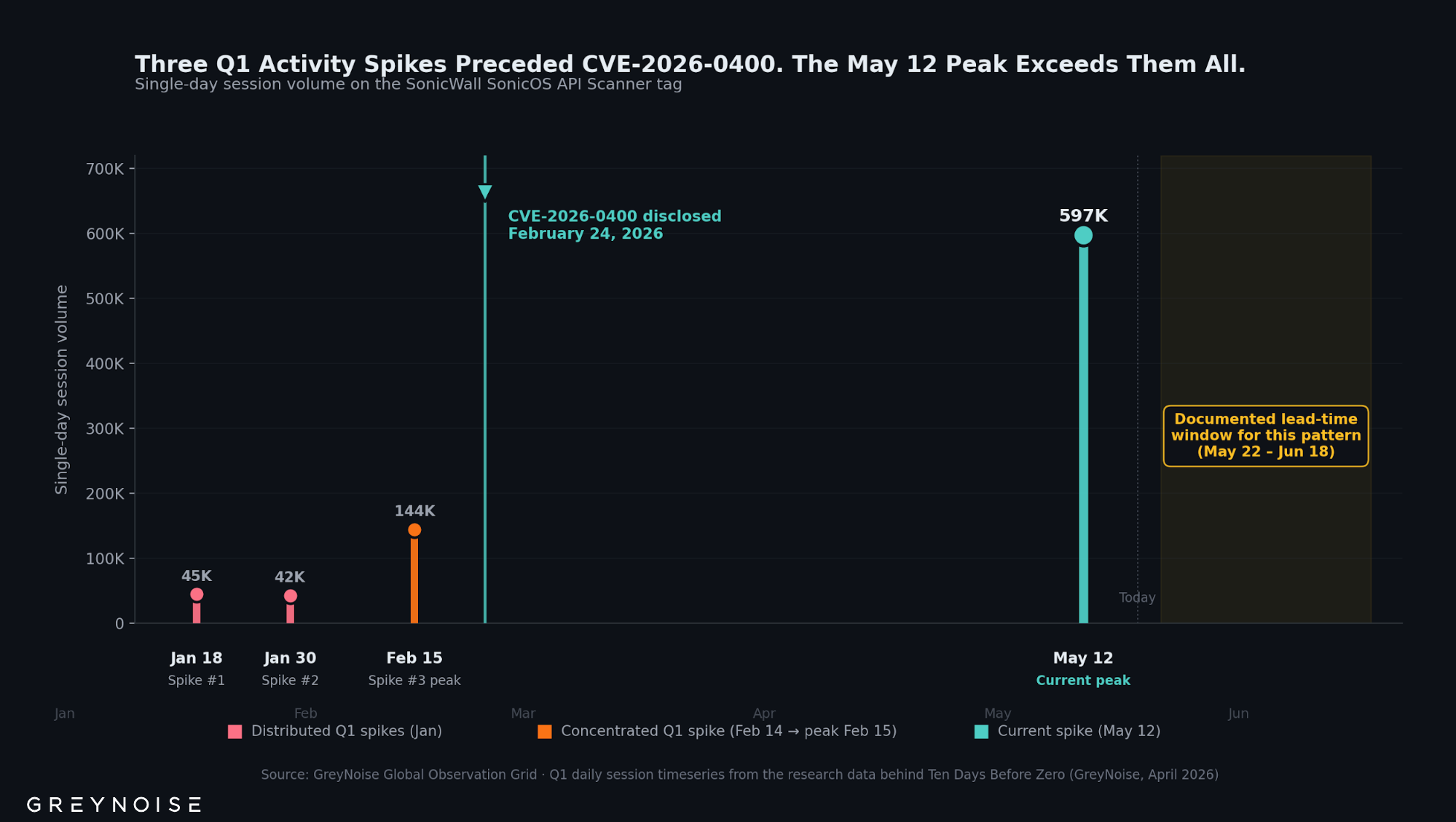
.png)

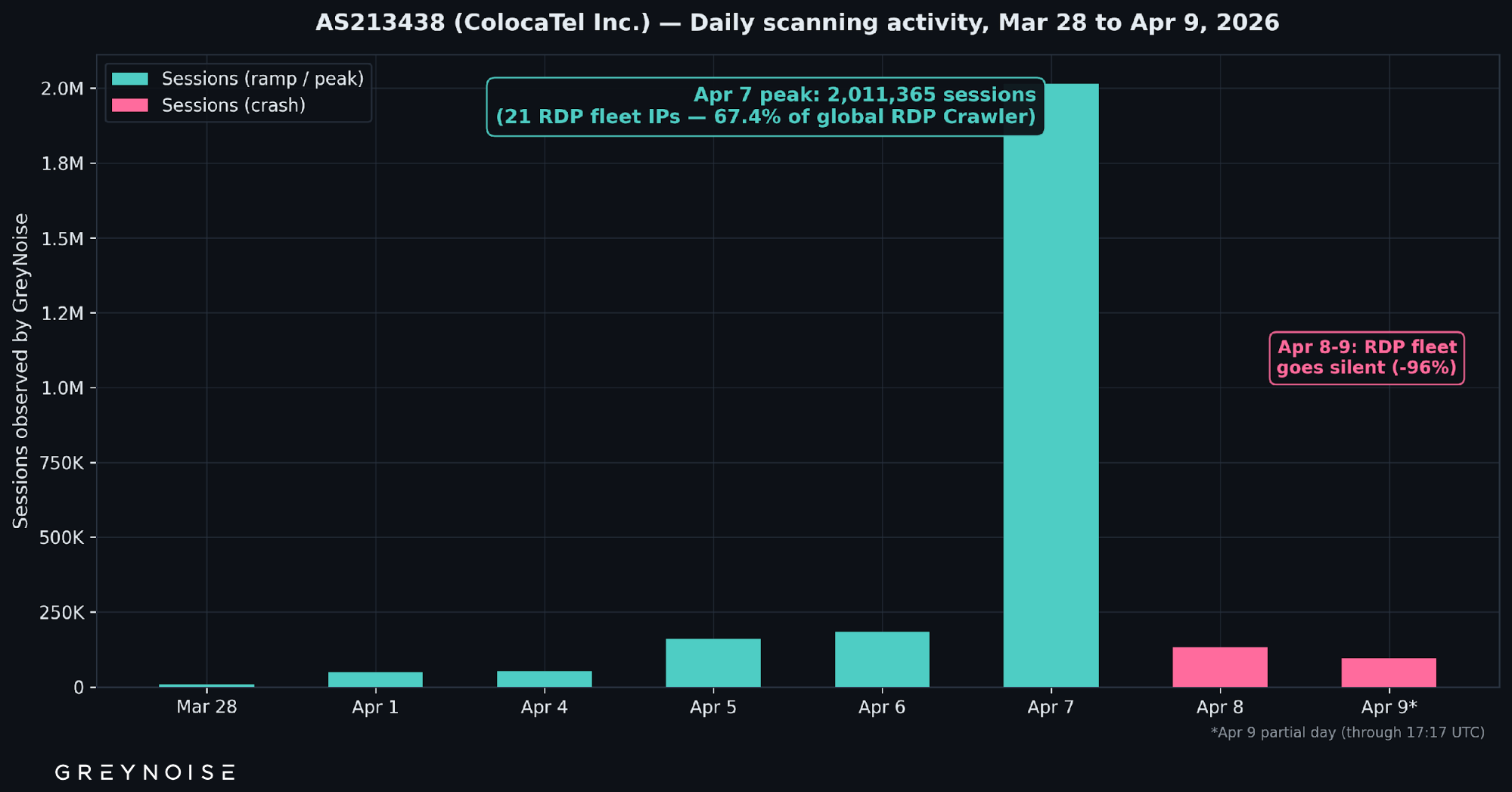
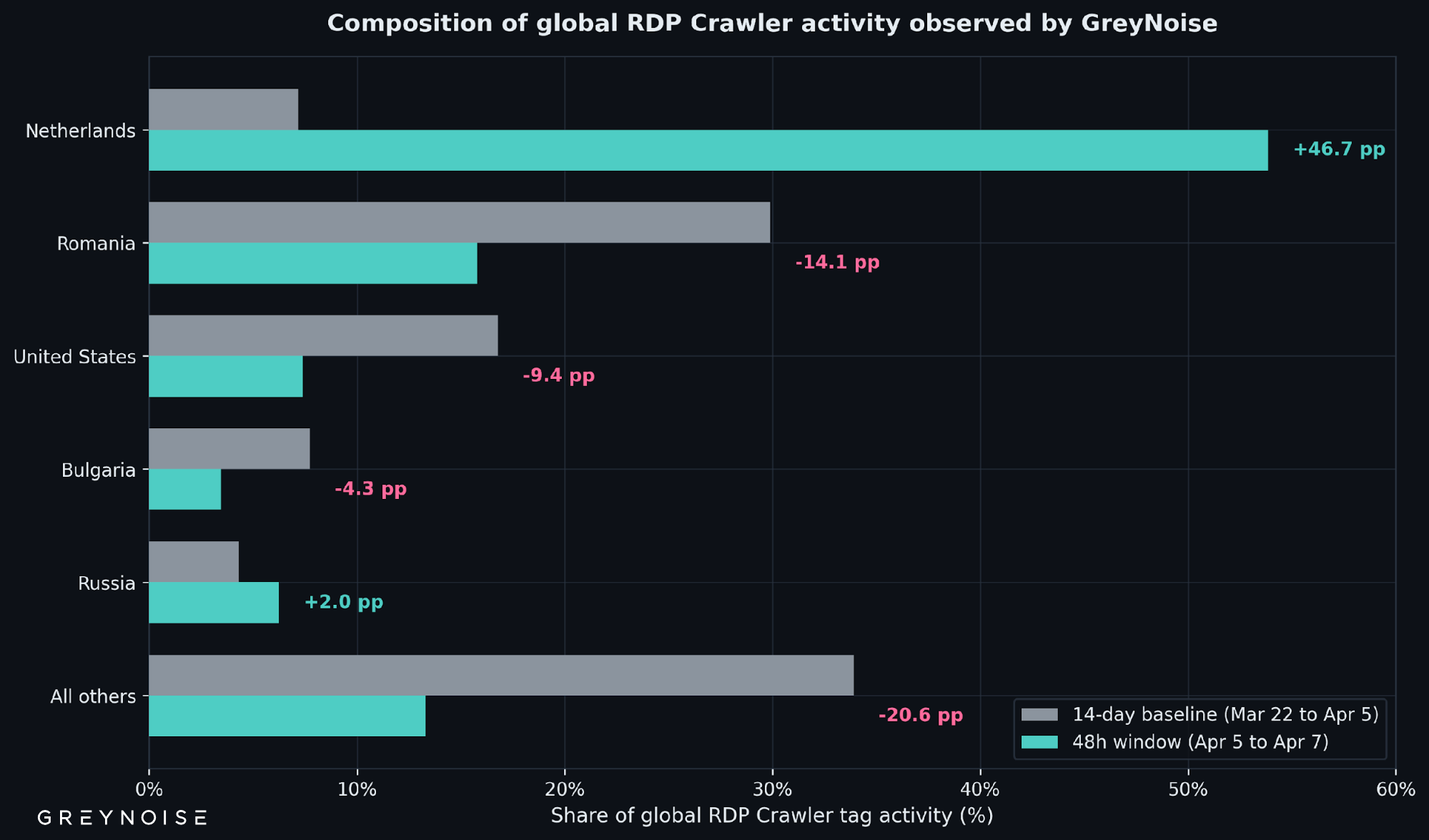
.png)
.png)

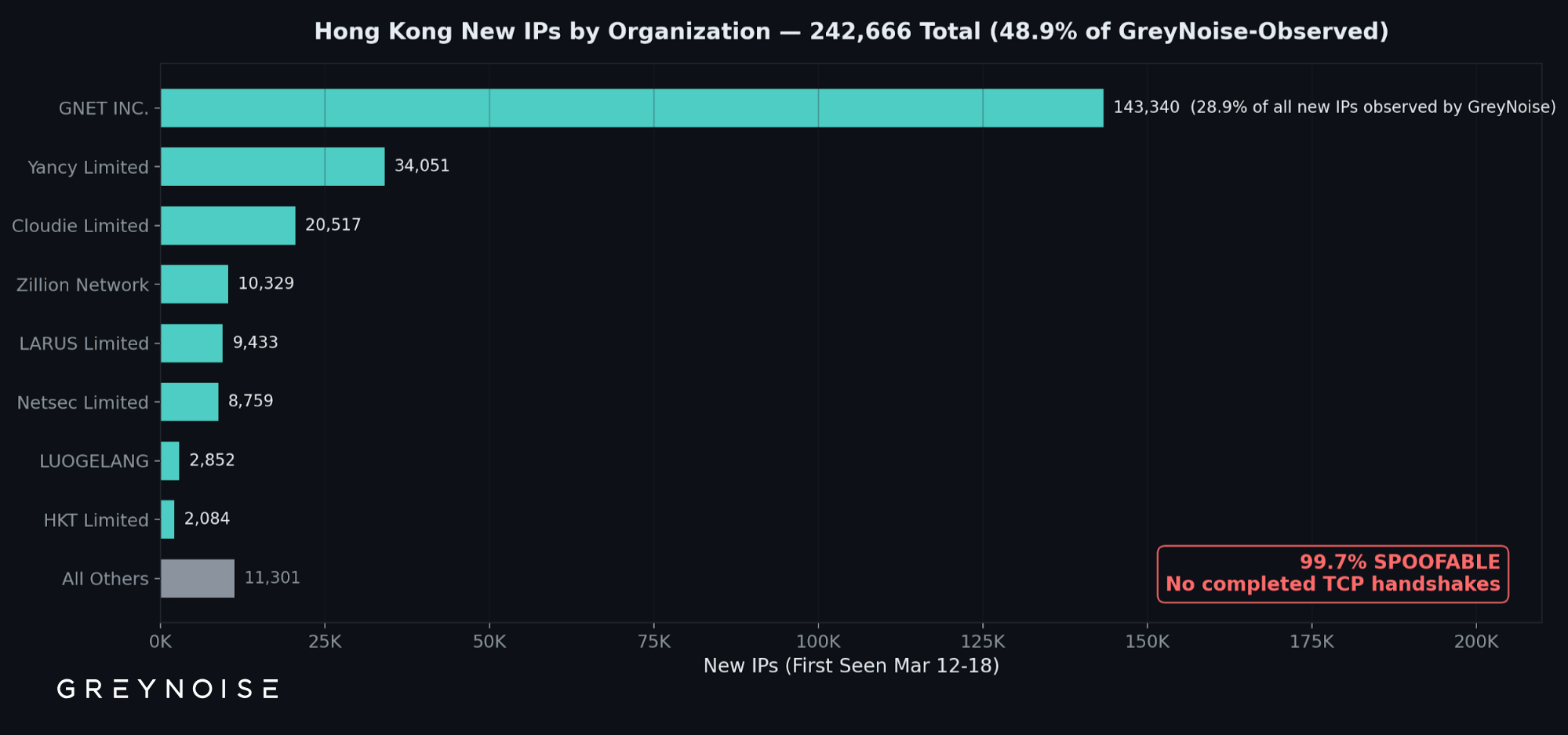
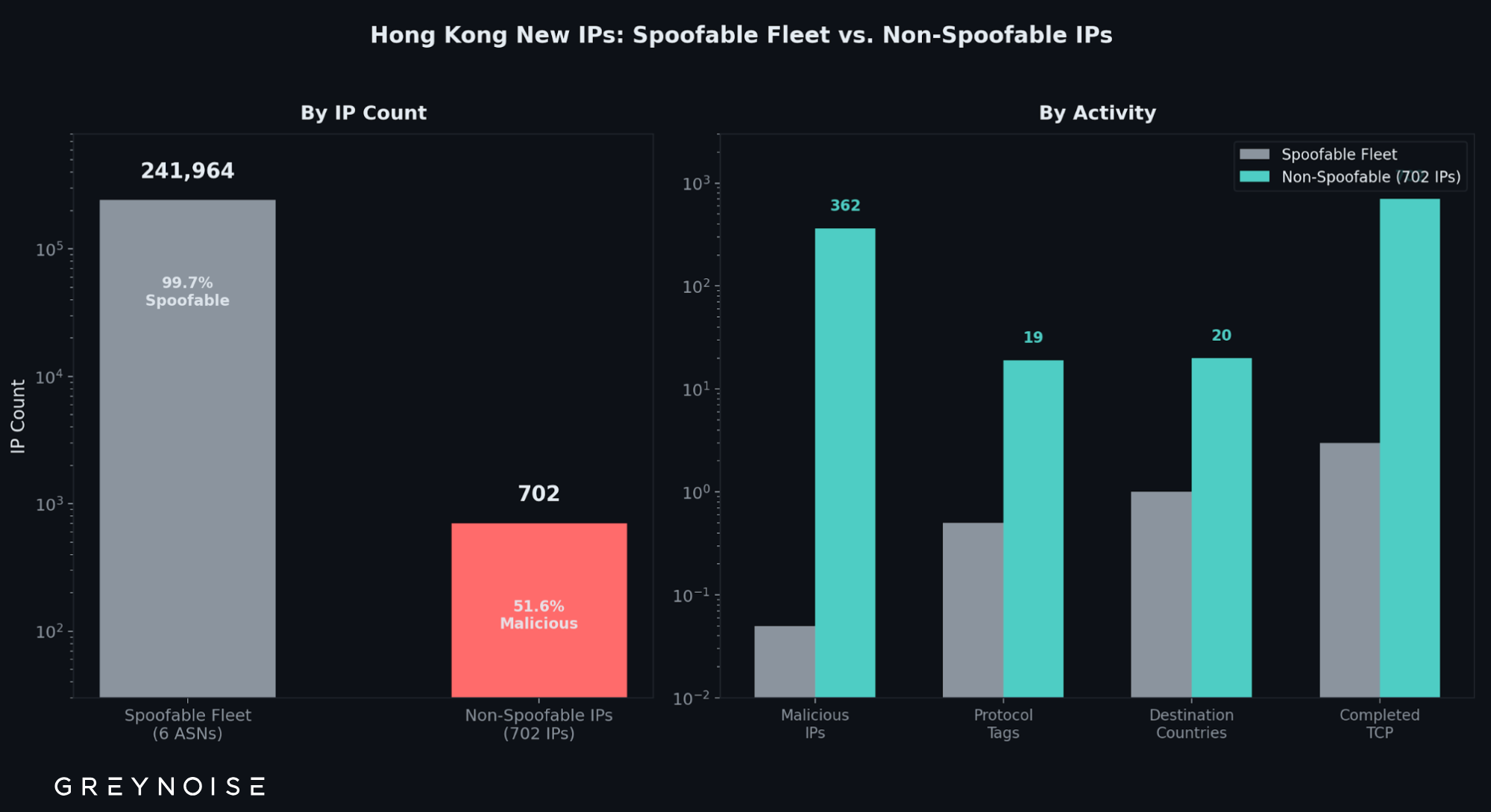
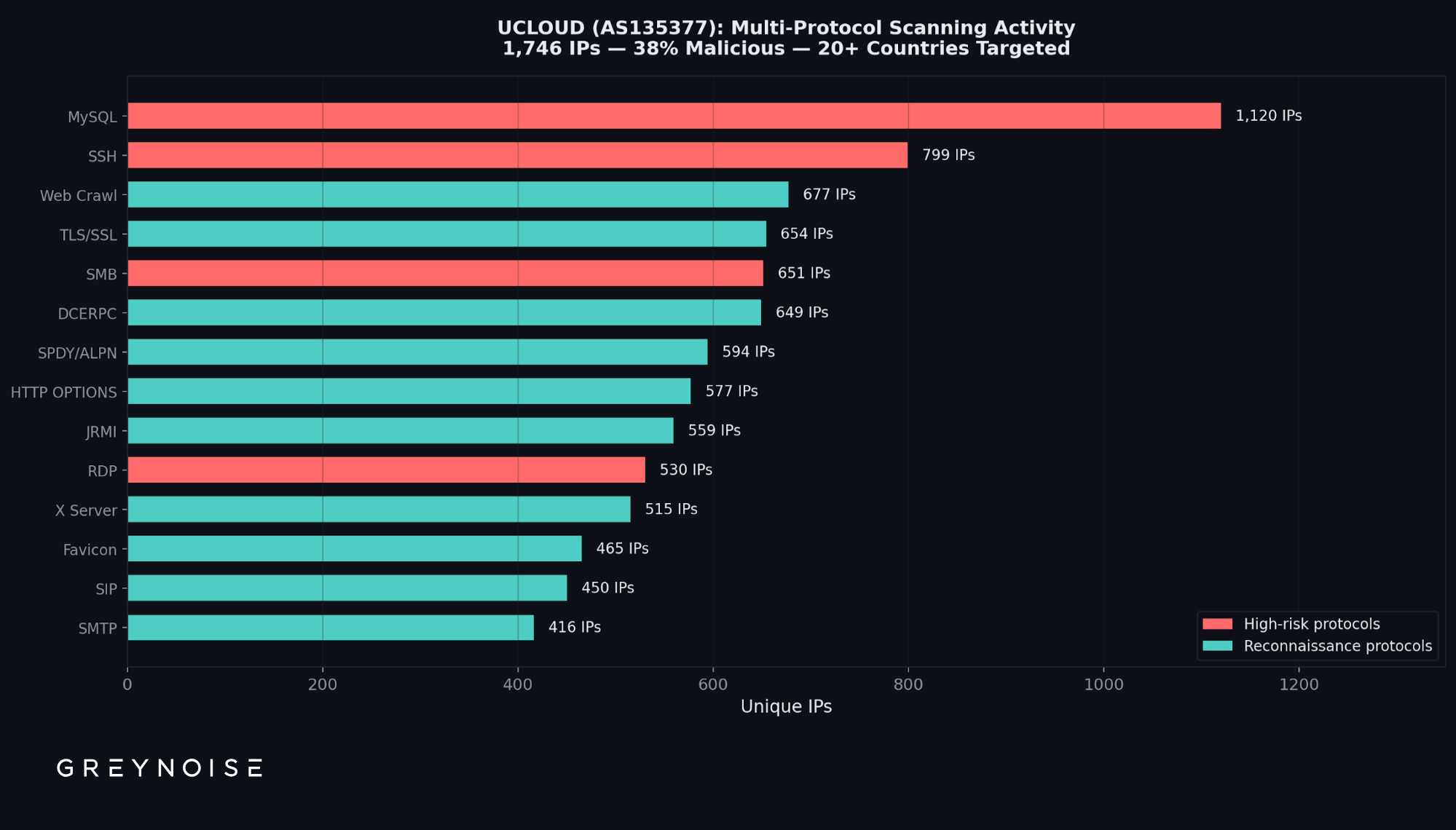
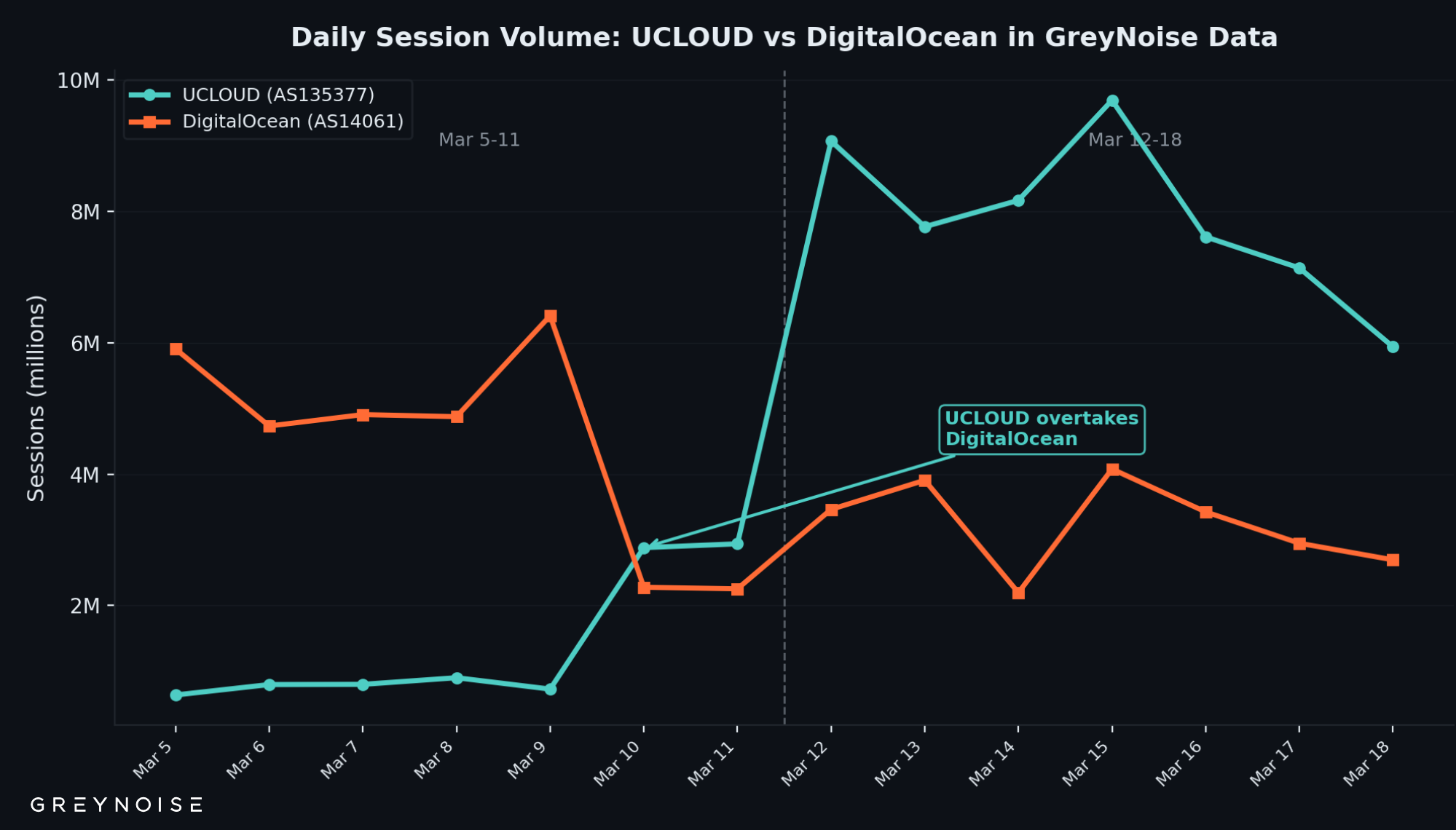
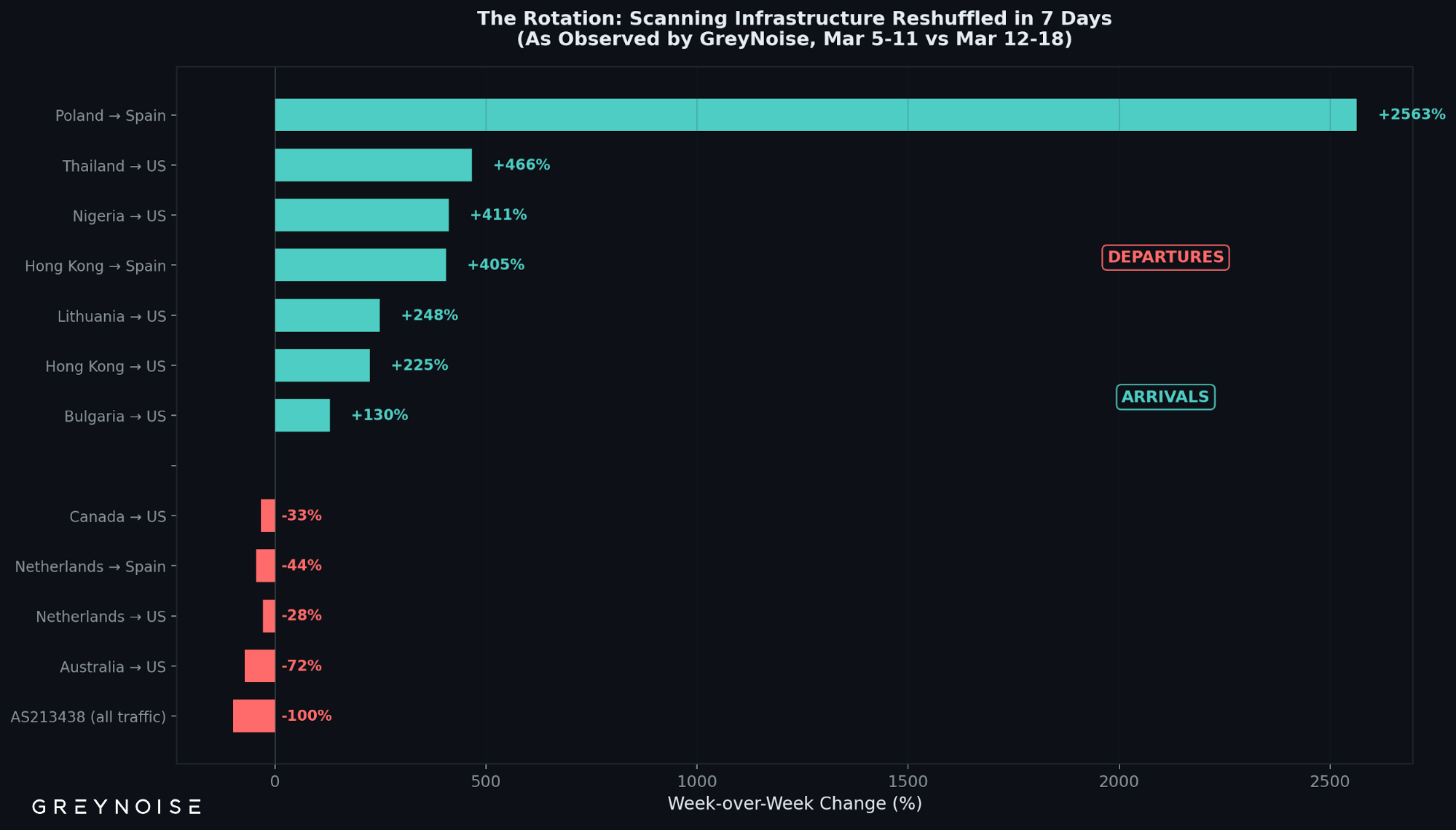

.png)
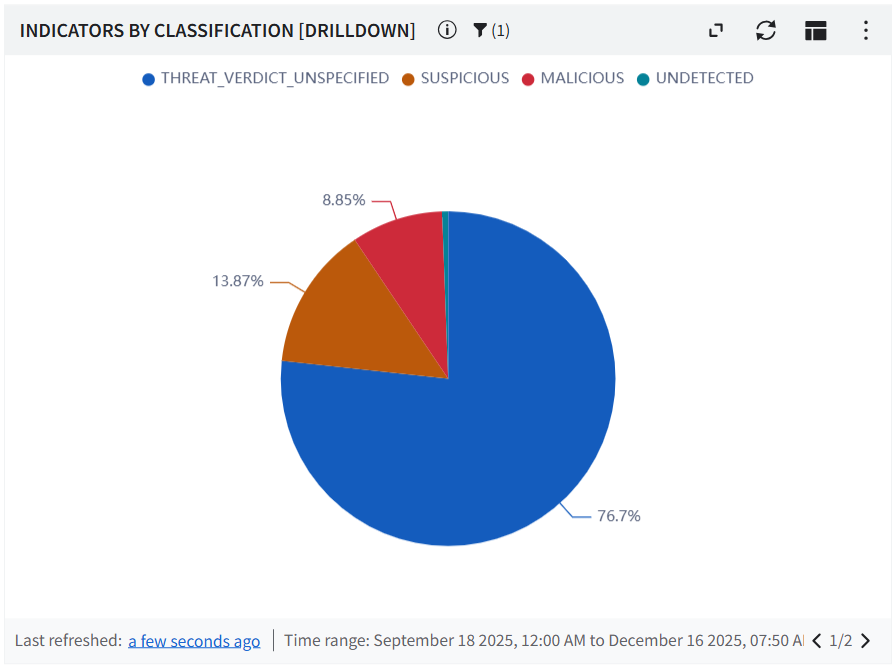
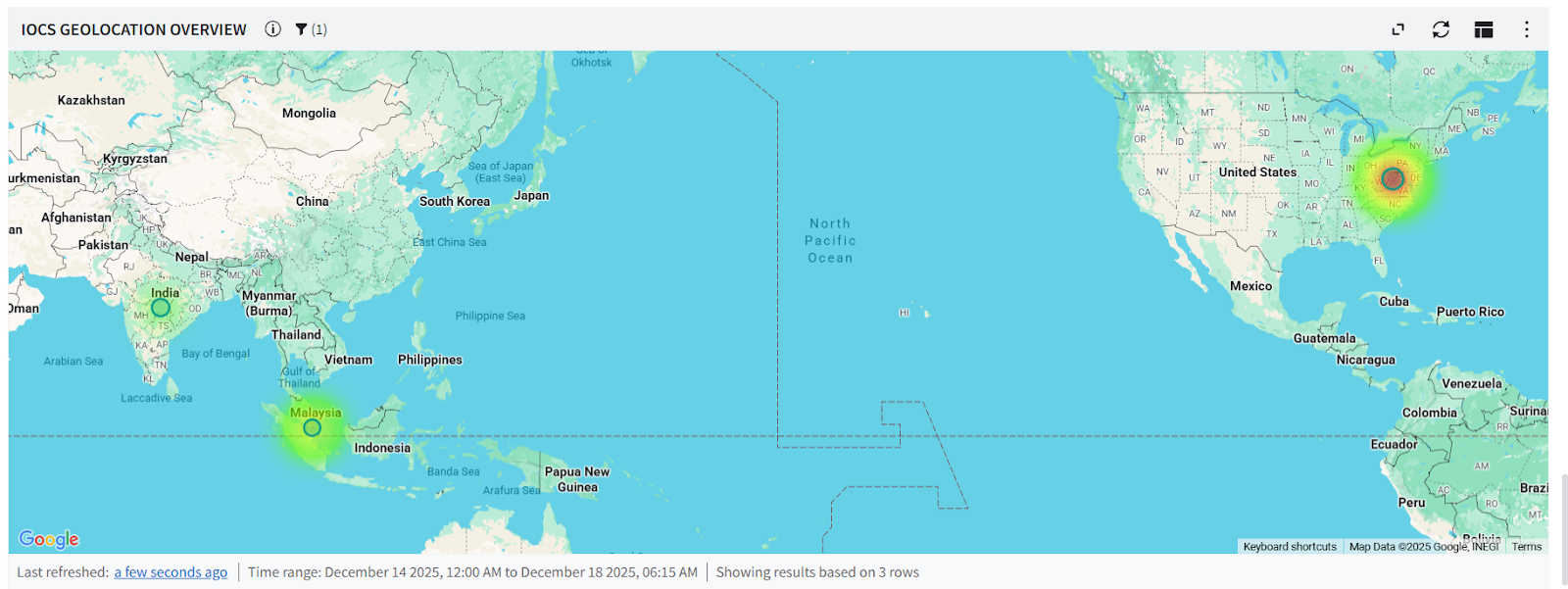




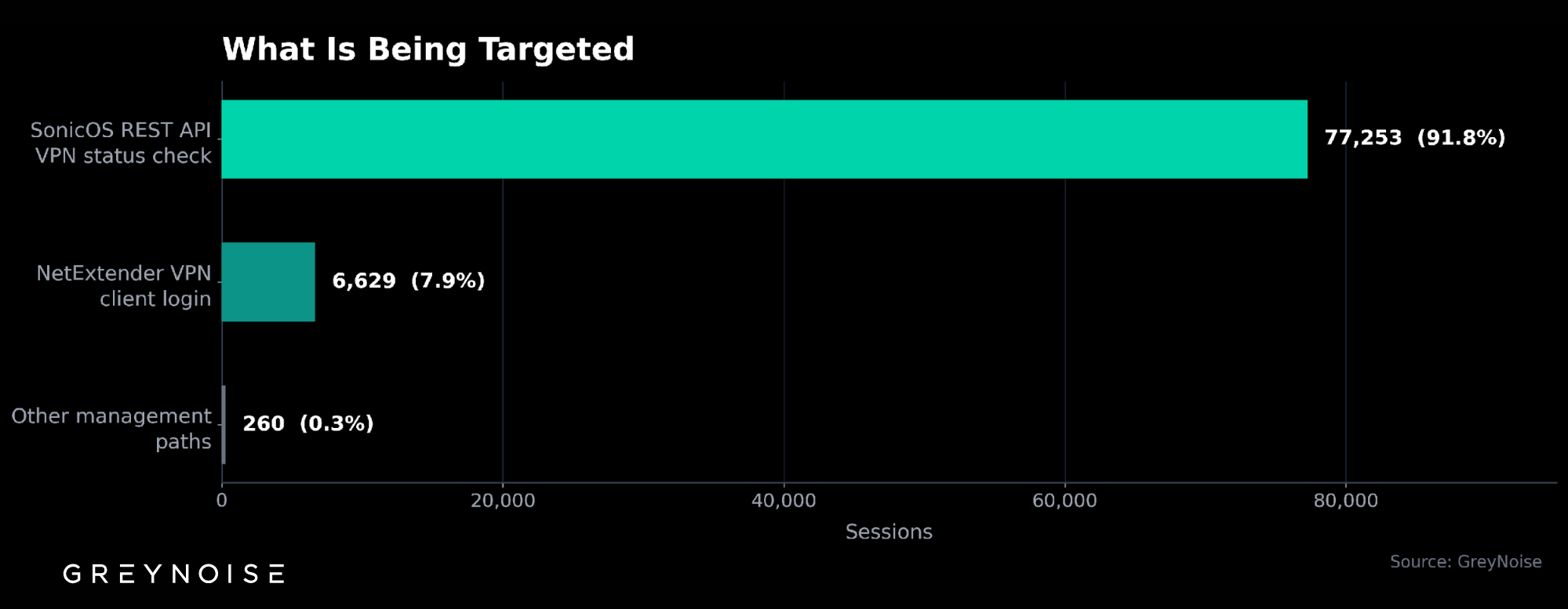
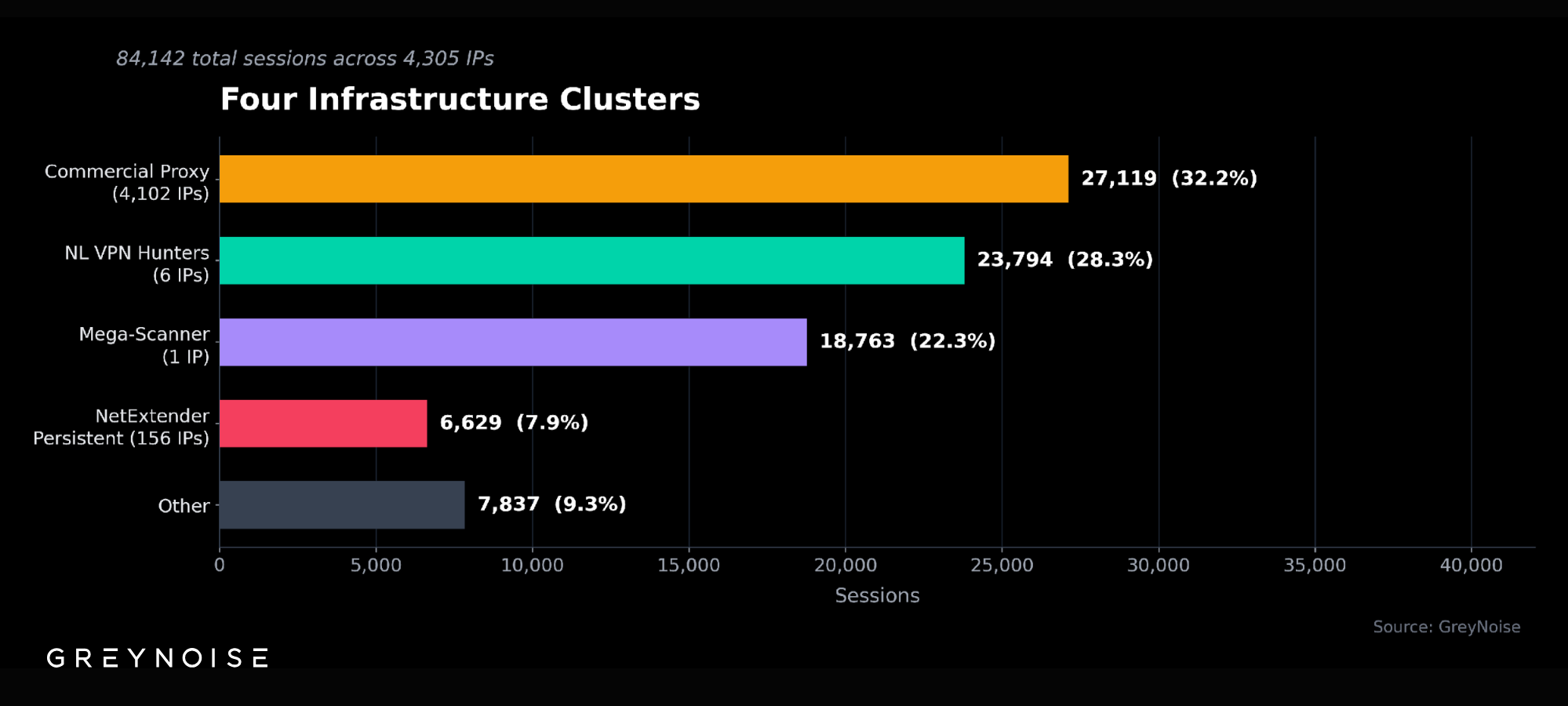
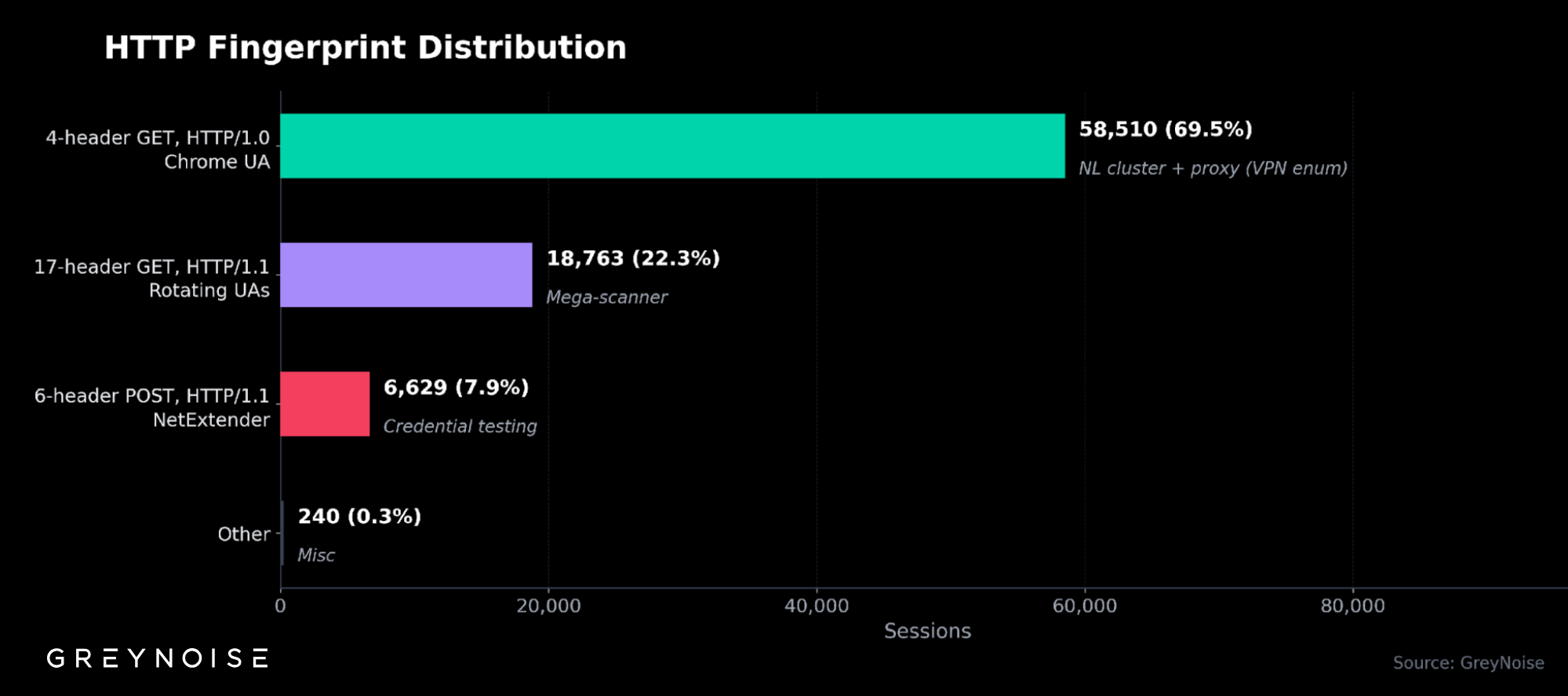
.png)

.png)

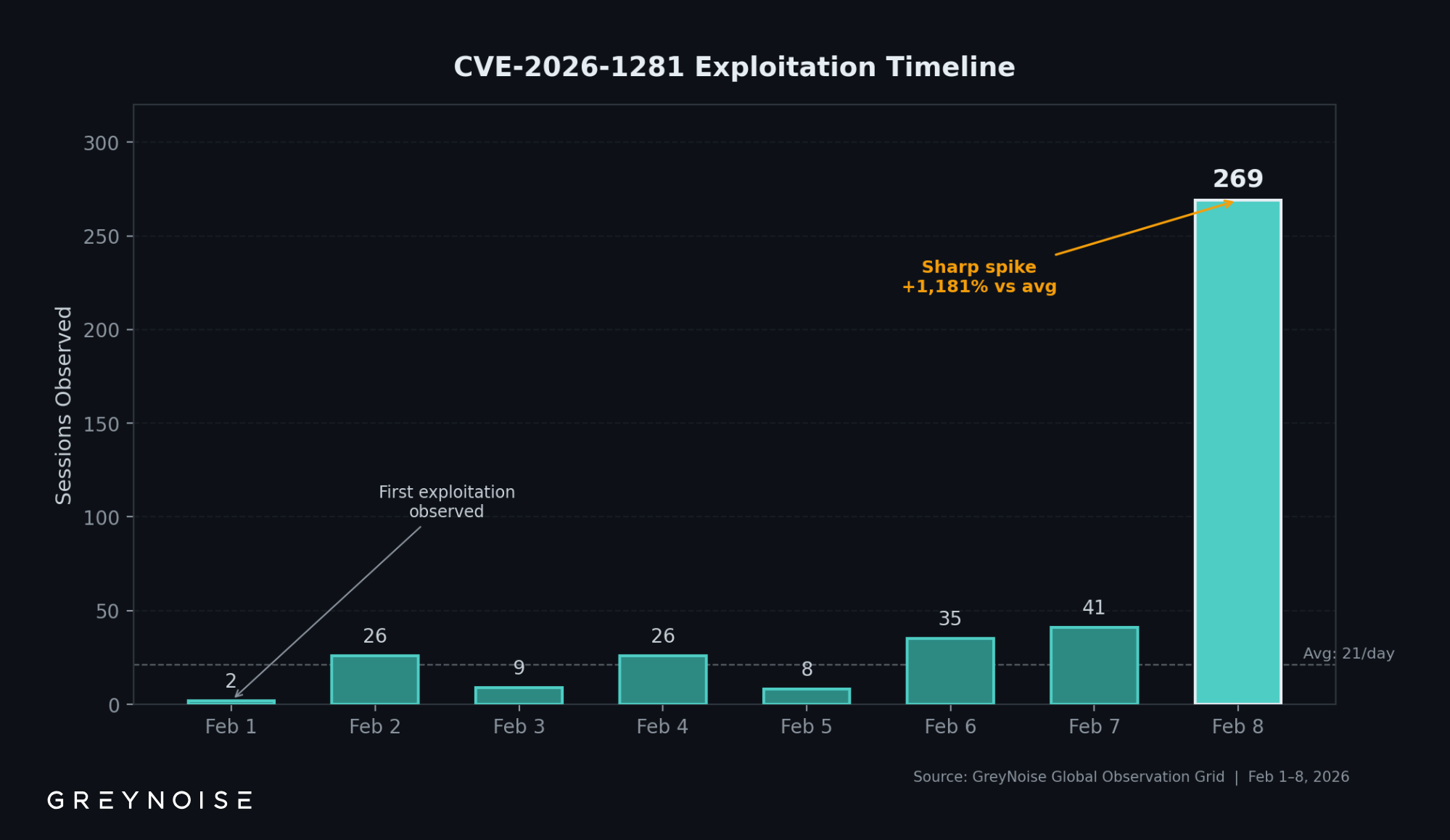

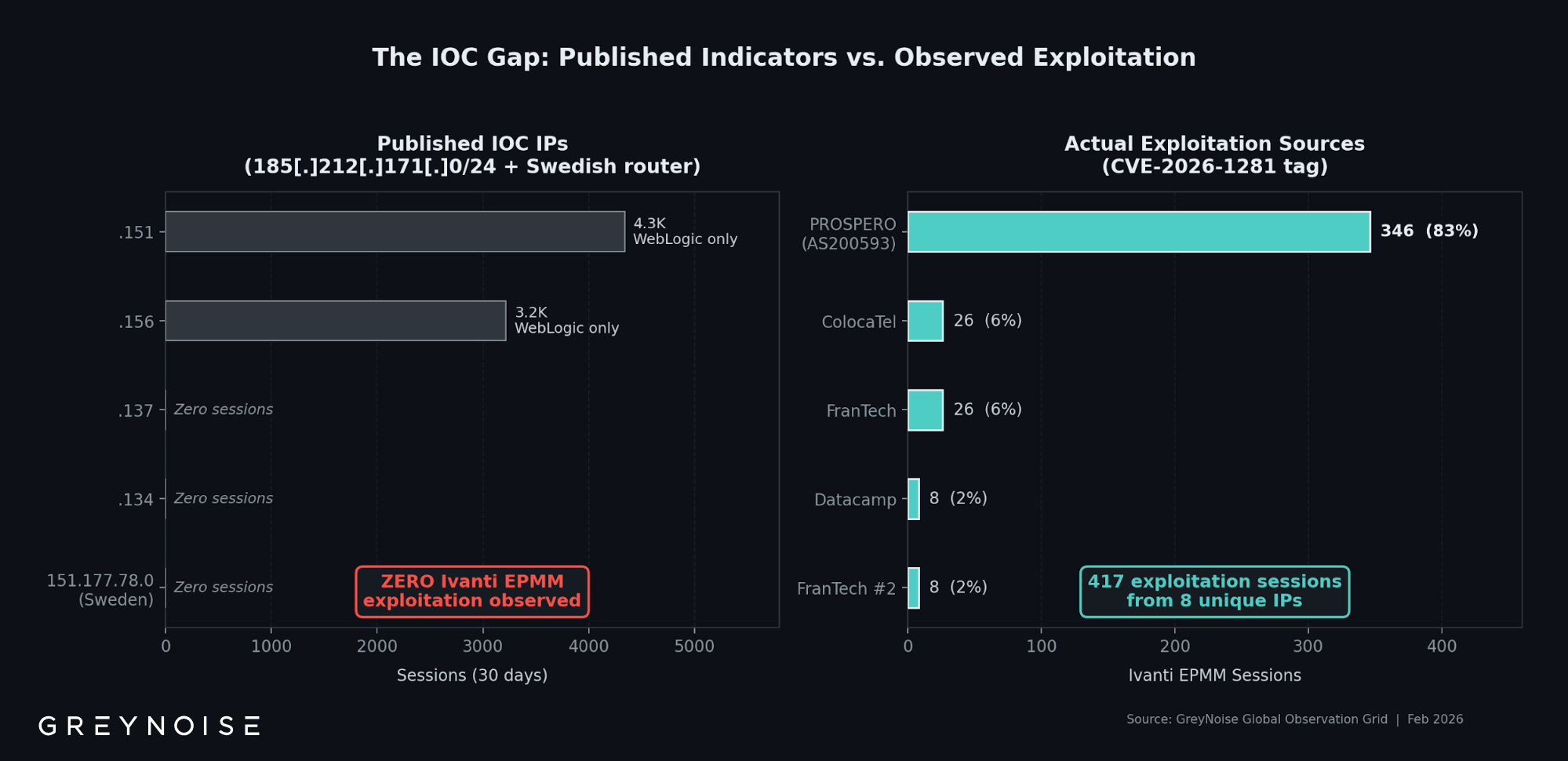

.png)
.png)