Key Takeaways
- 251 malicious IPs, all hosted by Amazon and geolocated in Japan, launched a coordinated one-day scan on May 8.
- These IPs triggered 75 distinct behaviors, including CVE exploits, misconfiguration probes, and recon activity.
- All IPs were silent before and after the surge, indicating temporary infrastructure rental for a single operation.
- Overlap analysis confirms tight coordination, not random scanning.
- Targeted technologies included ColdFusion, Apache Struts, Elasticsearch, WebLogic, Tomcat, and more.
- All 251 IPs are classified as malicious by GreyNoise.
- This activity reflects patterns outlined in GreyNoise’s latest study, which tracks the reemergence of long-dormant threats.
- Defenders should take action now: check May 8 logs, block the 251 IPs, dynamically block IPs targeting these 75 tags, and monitor for follow-up exploitation.
- Similar scanning behavior preceded the discovery of two zero-days in Ivanti EPMM, reinforcing the need to treat coordinated scanning as an early warning signal.
A Brief, Coordinated Reconnaissance Operation
On May 8, GreyNoise observed a highly coordinated reconnaissance campaign launched by 251 malicious IP addresses, all geolocated to Japan and hosted by Amazon AWS. Over the span of a single day, these IPs triggered 75 distinct scanning behaviors, each tracked by a GreyNoise tag — ranging from exploitation attempts for known CVEs to probes for misconfigurations and weak points in web infrastructure.
This operation was opportunistic — as is all scanning observed by GreyNoise — but the infrastructure and execution suggest centralized planning. Every IP was active only on May 8, with no noticeable activity immediately before or after, indicating temporary use of cloud infrastructure rented specifically for this operation.
Targeted Technologies
Some of the behaviors observed included exploit attempts for:
- Adobe ColdFusion — CVE-2018-15961 (RCE)
- Apache Struts — CVE-2017-5638 (OGNL Injection)
- Elasticsearch — CVE-2015-1427 (Groovy Sandbox Bypass RCE)
- Atlassian Confluence — CVE-2022-26134 (OGNL Injection)
- Bash — CVE-2014-6271 (Shellshock)
These CVEs, while disclosed years ago, continue to attract interest from opportunistic attackers — a pattern explored in our latest research, which tracks the return of long-disclosed flaws to the threat landscape.
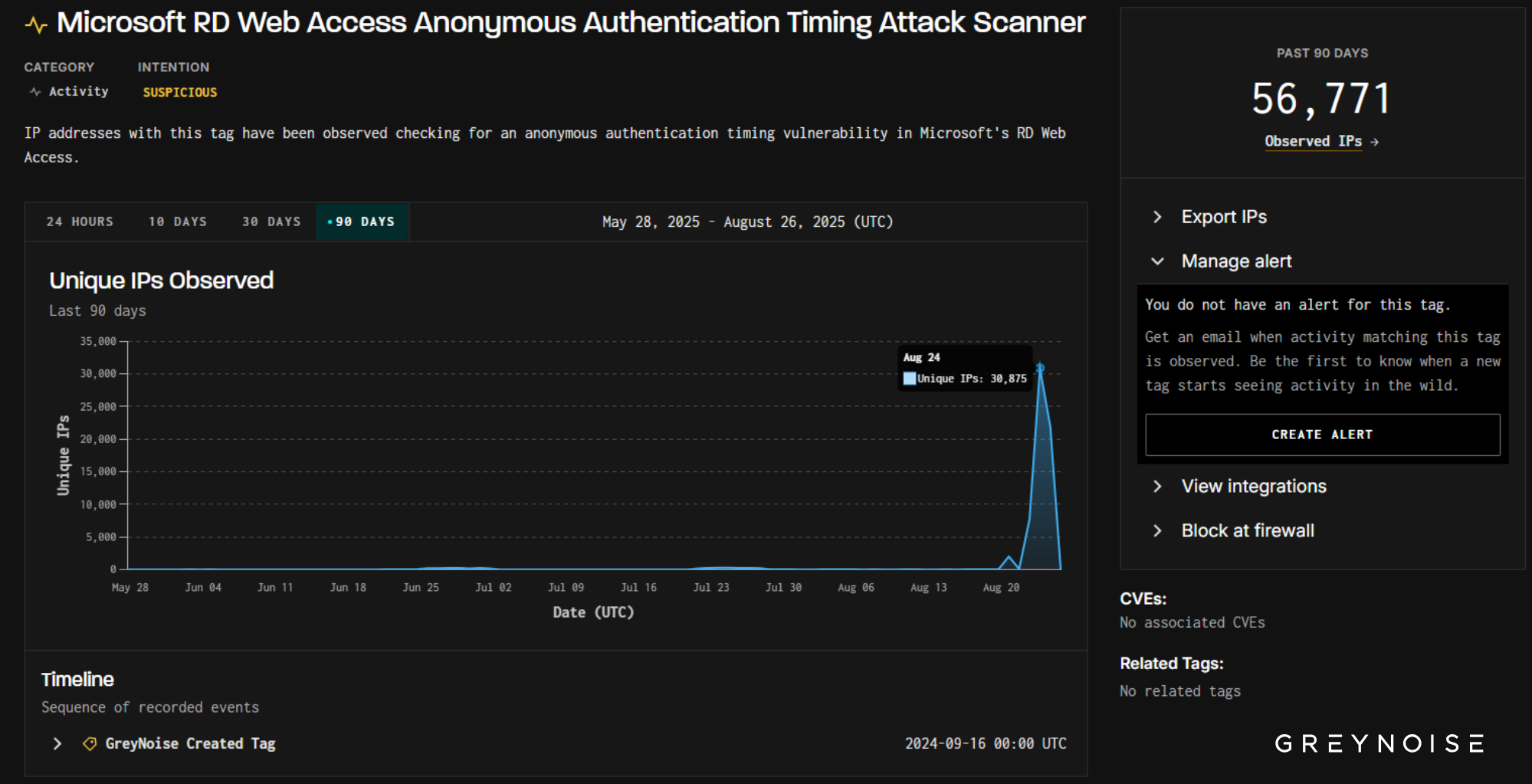
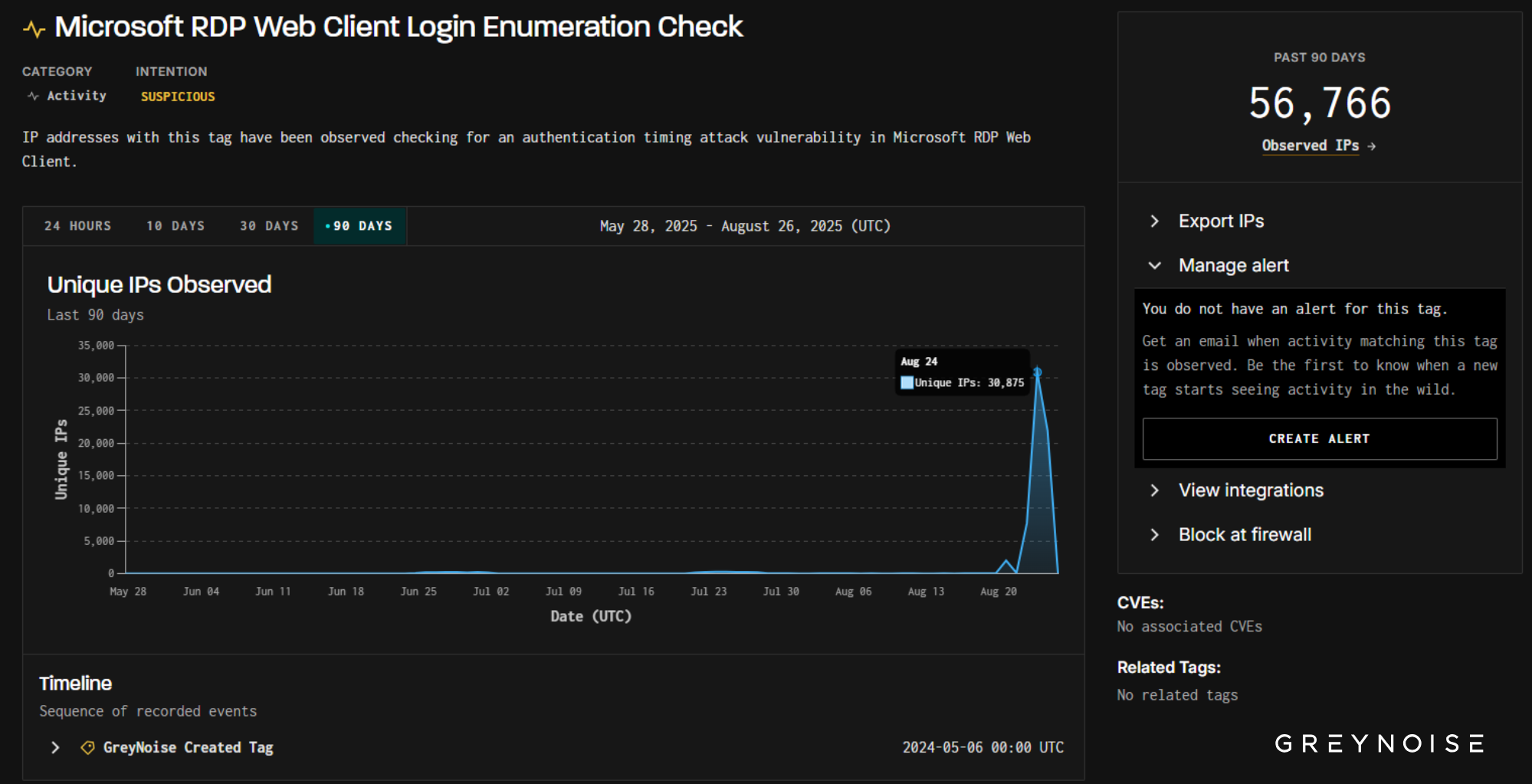
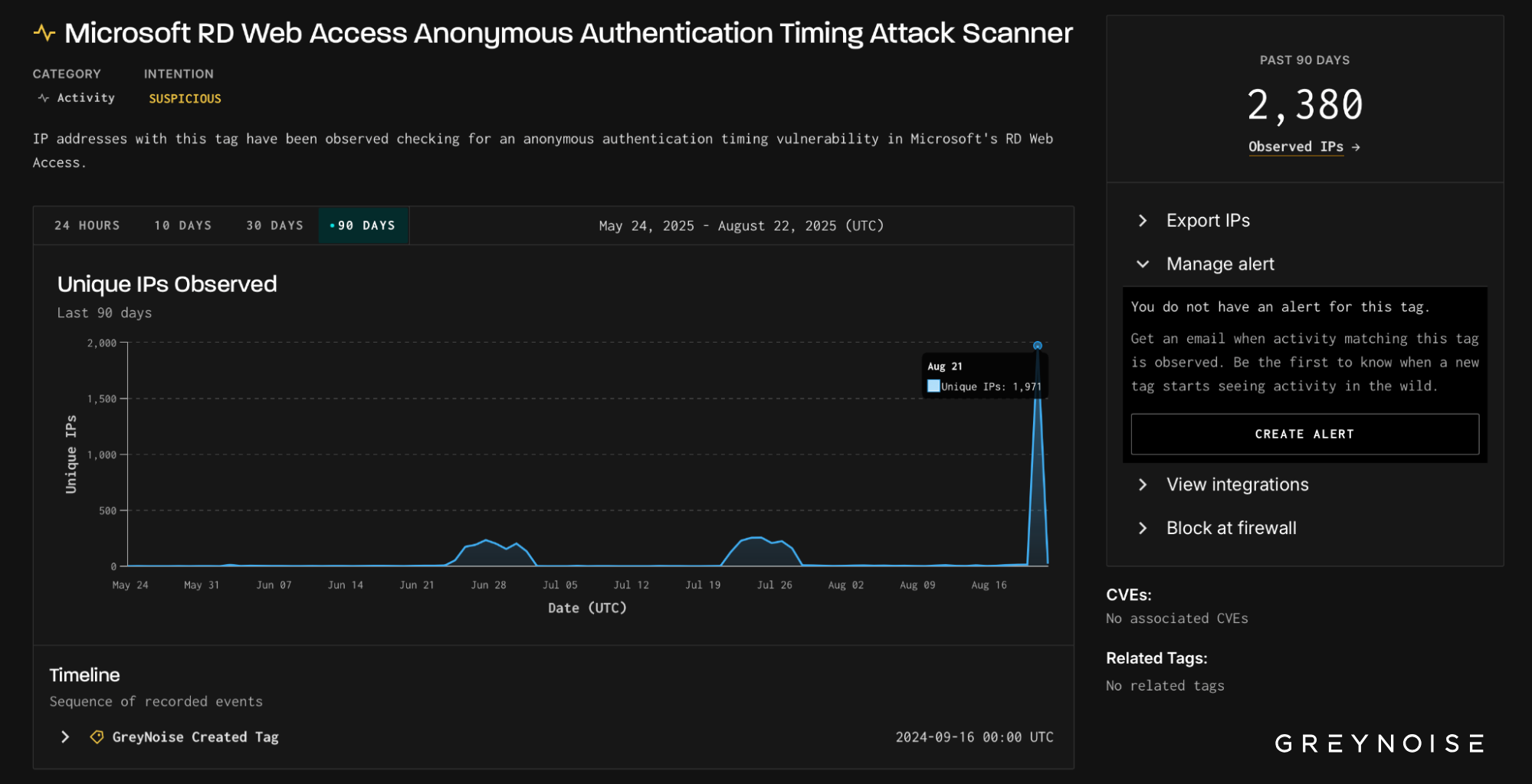
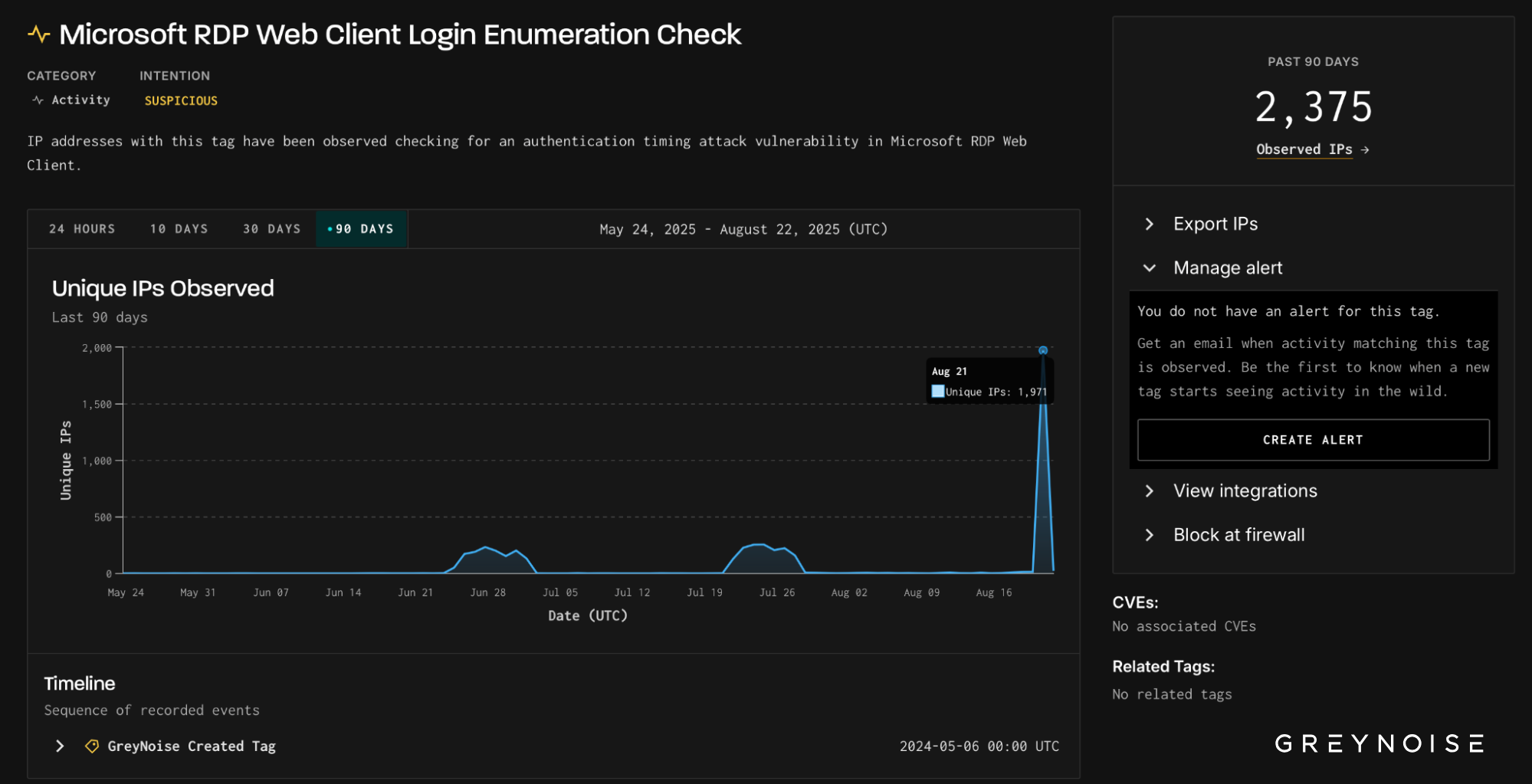
Scope of the Scan: 75 Exposure Behaviors
The 251 IPs collectively triggered 75 distinct scanning behaviors, including:
- Old vulnerability exploits — ColdFusion, Struts, WebLogic, Drupal, Tomcat, Elasticsearch.
- Recon and enumeration techniques — WordPress author checks, CGI script scanning, web.xml access attempts.
- Misconfiguration probes — Git config crawlers, ENV variable exposures, shell upload checks.
This wasn’t an operation focused on one exploit or tech stack. It reflected a broad-spectrum search for any exposed system — particularly older edge infrastructure that may be overlooked in patch cycles.
The 2025 Verizon DBIR revealed the edge as a critical risk, reporting concerning trends across time-to-mass-exploit and remediation lags in edge technologies.
Infrastructure Overlap Suggests Central Control
GreyNoise analysis revealed the following:
- 295 IPs scanned for ColdFusion (CVE-2018-15961).
- 265 IPs scanned for Apache Struts (CVE-2017-5638).
- 260 IPs scanned for Elasticsearch Groovy (CVE-2015-1427).
- 262 IPs overlapped between ColdFusion and Struts.
- 251 IPs overlapped across all three — and triggered 75 GreyNoise tags.
This level of overlap points to a single operator or toolset deployed across many temporary IPs — an increasingly common pattern in opportunistic but orchestral scanning.
Block These Malicious IPs
GreyNoise has compiled the full list of all 251 malicious IPs observed in this operation.
13.112.127.102,13.112.137.152,13.112.240.11,13.112.5.89,13.112.69.56,13.113.0.143,13.113.184.40,13.113.217.149,13.114.127.223,13.114.149.129,13.114.218.63,13.114.31.226,13.114.60.193,13.114.98.0,13.115.180.180,13.115.202.46,13.115.229.240,13.115.2.3,13.115.69.54,13.115.71.29,13.230.129.147,13.230.147.105,13.230.225.215,13.230.233.152,13.230.5.184,13.230.8.99,13.230.96.118,13.231.106.81,13.231.146.138,13.231.146.225,13.231.146.246,13.231.153.70,13.231.174.40,13.231.179.96,13.231.184.66,13.231.185.166,13.231.189.33,13.231.191.131,13.231.212.197,13.231.213.253,13.231.214.67,13.231.224.0,13.231.232.177,13.231.232.45,13.231.41.82,13.231.5.78,175.41.228.130,18.176.55.146,18.176.59.175,18.177.143.78,18.177.146.44,18.179.142.39,18.179.197.80,18.179.198.67,18.179.206.138,18.179.30.23,18.179.45.108,18.179.45.73,18.179.46.150,18.179.46.189,18.179.61.223,18.181.212.31,18.182.15.49,18.182.26.23,18.182.9.108,18.182.9.65,18.183.102.143,18.183.102.157,18.183.105.164,18.183.131.125,18.183.165.137,18.183.168.179,18.183.168.64,18.183.176.53,18.183.186.98,18.183.208.224,18.183.213.115,18.183.221.123,18.183.225.18,18.183.229.102,18.183.233.113,18.183.245.235,18.183.248.39,18.183.75.21,18.183.80.208,3.112.124.171,3.112.131.166,3.112.14.18,3.112.150.85,3.112.18.153,3.112.18.248,3.112.203.162,3.112.208.32,3.112.211.126,3.112.218.237,3.112.227.46,3.112.231.205,3.112.233.225,3.112.235.102,3.112.238.114,3.112.253.75,3.112.26.102,3.112.28.119,3.112.32.198,3.112.32.225,3.112.5.87,3.113.0.228,3.113.0.28,3.113.15.97,3.113.25.14,3.113.32.74,35.72.14.113,35.72.14.164,35.72.4.135,35.72.9.173,35.77.105.104,35.77.90.69,35.77.93.26,43.206.215.21,43.206.231.122,43.206.234.13,43.206.235.211,43.206.253.231,43.207.0.130,43.207.103.240,43.207.105.145,43.207.115.43,43.207.118.103,43.207.1.24,43.207.139.186,43.207.150.212,43.207.155.29,43.207.155.87,43.207.166.102,43.207.170.51,43.207.191.167,43.207.198.203,43.207.201.71,43.207.202.54,43.207.203.44,43.207.225.86,43.207.232.1,43.207.232.100,43.207.3.58,43.207.74.241,43.207.79.249,43.207.81.76,52.192.111.156,52.192.125.55,52.192.14.49,52.192.27.19,52.192.56.196,52.192.99.140,52.194.205.49,52.194.220.244,52.194.248.125,52.194.250.54,52.194.254.213,52.195.11.174,52.195.12.82,52.195.171.70,52.195.177.128,52.195.181.143,52.195.183.23,52.195.189.155,52.195.189.78,52.195.194.167,52.195.207.5,52.195.208.52,52.195.209.222,52.195.211.238,52.195.218.94,52.195.221.157,52.195.3.244,52.195.8.164,52.197.210.229,52.199.10.181,52.199.149.12,52.199.199.160,52.199.253.240,52.199.8.84,52.68.188.9,52.68.94.94,52.69.157.91,52.69.46.191,54.150.219.131,54.168.241.135,54.168.247.234,54.168.71.21,54.178.0.190,54.178.114.236,54.178.4.74,54.178.5.144,54.199.101.111,54.199.161.31,54.199.176.59,54.199.40.192,54.199.77.18,54.199.94.62,54.238.101.236,54.238.147.176,54.238.179.56,54.238.189.57,54.238.237.183,54.238.237.9,54.238.4.12,54.238.80.76,54.248.152.214,54.248.156.216,54.248.201.195,54.248.36.134,54.249.121.50,54.249.133.28,54.249.155.117,54.249.219.65,54.249.26.220,54.250.153.158,54.250.161.184,54.250.16.51,54.250.188.209,54.250.237.20,54.250.241.63,54.250.244.142,54.250.244.229,54.250.33.160,54.250.33.94,54.65.130.227,54.65.45.54,54.95.18.182,54.95.193.225,54.95.23.202,54.95.23.87,54.95.36.237,57.180.10.227,57.180.18.215,57.180.242.12,57.180.246.9,57.180.248.217,57.180.27.121,57.180.35.101,57.180.38.232,57.180.40.26,57.180.41.47,57.180.42.39,57.180.47.171,57.180.47.190,57.180.48.122,57.180.56.170,57.180.9.137,57.181.30.246,57.181.37.146
Defenders should block these IPs immediately. While follow-up exploitation may come from different infrastructure, GreyNoise classified all 251 IPs as malicious in real time. Dynamic IP blocking using GreyNoise allows defenses to respond instantly to new scanning infrastructure as it appears, removing guesswork and reducing exposure windows.
Dynamically Block IPs Targeting These 75 Tags
Identify which of the 75 GreyNoise tags apply to your environment and dynamically block IPs engaging in that activity.
Edge & Middleware RCEs
CMS & Web App Exploits
IoT & Hardware Targets
Reconnaissance & Crawlers
File Uploads & Web Shells
SQLi & Path Traversal
Legacy & Resurgent CVEs
Authentication & Config Scans
Miscellaneous or Unclassified
GreyNoise will continue to monitor this situation and provide updates as necessary.
GreyNoise has developed an enhanced dynamic IP blocklist to help defenders take faster action on emerging threats. Click here to learn more about GreyNoise Block.
— — —
Stone is Head of Content at GreyNoise Intelligence, where he leads strategic content initiatives that illuminate the complexities of internet noise and threat intelligence. In past roles, he led partnered research initiatives with Google and the U.S. Department of Homeland Security. With a background in finance, technology, and engagement with the United Nations on global topics, Stone brings a multidimensional perspective to cybersecurity. He is also affiliated with the Council on Foreign Relations.




.png)

.png)



.png)












.png)


.png)








