If you’ve ever heard our founder and CEO, Andrew Morris, speak, you’ll know that one of the core reasons GreyNoise exists is to answer the question “Is everyone seeing this, or is it just me?”
GreyNoise provides details about opportunistic scan activity by source IP as observed across our sensor network. When large geopolitical events happen, like the ongoing Russia-Ukraine war, our research team historically has been able to provide details on the destination of the traffic we’re seeing as well (e.g. Russian scans and exploitation attempts only focusing on our Ukrainian sensors). We are proud to share that this capability, labeled as IP Geo Destination, is now available to all GreyNoise customers via the Visualizer and API endpoints as of today.
What IP Geo Destination Can Show You
Using the new IP Geo Destination feature, we can delve deeper into anomalies in scanning traffic.
Multi-Destination Results
Recently, there has been an uptick in scan activity related to scanning for DB2 databases as highlighted by the trends page. Using this as a starting point organizations can begin to investigate further to better understand why there is a sudden increase in scan activity.
DB2 Scanner Tag observes irregular traffic patterns. Source: GreyNoise
Using the GreyNoise command line tool, we can search ‘.metadata.destination_countries’ to derive where this activity is pointing to. The traffic seen from the DB2 Scanner in the last 7 days reveals an even distribution of traffic across GreyNoise sensors in 41 different countries (see our docs for a list of all countries where we have sensors today).
Distribution of destination countries for the previous 7 days of activity for the DB2 Scanner tag. Source: GreyNoise
Further investigating IPs active in the last seven days that are scanning for DB2 instances shows that all of them have been tagged as malicious in GreyNoise. Most of them have multiple tags associated with each IP address, several of which are related to various worms attempting to propagate across the systems connected to the internet.
Overview of the previous 7 days of activity and classification for IP’s tagged as a DB2 scanner. Source: GreyNoise
Single Destination Results
Threat hunters looking for more targeted activity can add the `single_destination` parameter to identify IPs focusing on a particular geographic region.
Filtering down results to look for IPs that are targeting a specific country. Source GreyNoise
In the example above, by entering the search `tags:"DB2 Scanner" destination_country:Ukraine single_destination:true `, you can filter results to show onlyactivity that is targeting a single country, in this case, Ukraine. Defenders that work for the government, non-profit organizations, or are generally interested in a specific country or region can utilize this to focus on localized activities and potential threats.
----
With the additional data provided by IP Geo Destination, GreyNoise users can better understand how attacks impact different geographic regions. Our destination data is built off of our own sensor network so the geographic information being provided is first-hand. This feature is designed for cyber defenders to connect geopolitical motivations with scan and attack traffic and help responders quickly prioritize and triage alerts.
If you have questions about this feature or are interested in getting a demo contact our sales team.
You may have noticed an anomalous uptick of PUT requests in the GreyNoise sensors these past couple of days (2023-01-22 → 2023-01-24). For those interested, we’ve put together a quick summary of the details for you to dive into.
The majority of PUT requests occurred from January 15, 2023, to January 26th, 2023. During this time period, 2,927 payloads were observed containing HTTP paths of randomly generated letters and either a “.txt” or “.jsp” file extension. Similarly, the body of the PUT requests contained a randomly generated string as text and another randomly generated string contained within the markdown of a Jakarta Server Page (JSP) comment field. We believe this to be a methodology attempting to insert a unique identifier into the target server to determine potential capabilities of further exploitation; such as the ability to upload arbitrary files, retrieve the contents of the uploaded file, and determine if the JSP page was rendered (indicative of possible remote code execution).
Sample of Decoded HTTP PUT Payload
The remaining path counts can be seen here:
Table of HTTP PUT Path Counts Observed by GreyNoise Sensors
The most common being "/api/v2…", a path often found in FortiOS authentication bypass attempts. Check out our blog to learn more about tracking this exploit. We’ve also seen variations of "/FxCodeShell.jsp…", which is indicative of a Tomcat backdoor usage. Each has their respective packet example below:
FortiOS Authentication Bypass Attempt
Tomcat Backdoor CVE-2017-12615
Inquiring into these paths led to a discovery for us as well! Having been formally unfamiliar with the "/_users/org.couchdb.user:..." path, we did some digging, which led to a new signature for CVE-2017-12635.
Instances of Apache CouchDB Remote Priv Esc Attempts
This highlights novel ways attackers are attempting to fingerprint exposed services using known vulnerabilities, and is a starting point for hunting for additional malicious activity related to these requests.
When digging into these anomalies, GreyNoise researchers noticed a pattern of randomly generated JSP checking to see if they can upload, and then access their uploaded files.
The FortiOS authentication bypass used both the "/api/v2" HTTP PATH prefix along with a header of "User-Agent: Node.js"
Researchers at GreyNoise Intelligence have added over 230 tags since January 1, 2022, which include detections for over 160 CVEs. In today’s release of the GreyNoise Intelligence 2022 "Year of Mass Exploits" retrospective report, we showcase four of 2022's most pernicious and pwnable vulnerabilities.
Activity around the Log4j remote code execution flaw, which burst on the scene in last 2021, continued apace, and has found its place in daily internet background noise along with a cadre of other “celebrity vulnerabilities”. During the initial exploitation period, every single GreyNoise sensor (over six hundred sensors handle traffic from over five thousand internet IP addresses) fielded Log4j exploit traffic, handling nearly one-million attempts within the first week alone. Attackers continue to hunt for newly exposed, vulnerable nodes, and for nodes that may have accidentally had mitigations or patches removed.
Log4j weekly activity in GreyNoise sensors
The Atlassian Confluence Object Graph Notation Library (OGNL) injection weakness was an especially rueful one since it gave anyone unauthenticated access to any fathomable query, and Confluence is the knowledge repository of countless organizations. Due to the way this API endpoint handles input, clever attackers used varying techniques to obfuscate exploit payloads like the one below to avoid detection:
At the height of exploitation attempts, the GreyNoise sensor network saw nearly 1,000 unique IP addresses looking for exposed vulnerable nodes. We continue to see a daily average of nearly 20 unique addresses hoping for unpatched Confluence instances.
Apache httpd's path traversal and Remote code execution one-two punch may have entered the ring in 2021, but this contender made our 2022 list due to a steady increase in traversal exploit volume throughout the year (nearly 3x as many attempts as when the vulnerability first emerged on the scene). Apache’s httpd server may not have the top spot anymore, but it is still highly prevalent, and patching of legacy instances tends to be very spotty.
The F5 Big IP iControl's REST authentication bypass made the cut for the report as it hit the sweet spot in terms of the GreyNoise Celebrity Vulnerability Hype Cycle model (which is detailed in the report):
GreyNoise "Celebrity Vulnerability Hype Cycle"
Finally, GreyNoise researchers took a hard look at CISA’s Known Exploited Vulnerability (KEV) Catalog releases in 2022 (through late-November):
Keen defenders had to deal with a KEV alert on an almost weekly basis in 2022.
The aggression against Ukraine added many legacy vulnerabilities and the increased threat of nation-state actors into organization threat models.
Popular enterprise software, across many versions, made regular appearances, forcing defenders to triage KEV lists against known installed software.
GreyNoise has tags for over 100 CVEs in the 2022 component of the KEV catalog. KEV CVEs without tags are ones where we would not see internet-facing remote exploit attempts (though there are a tiny number of KEV CVEs we're in the process of developing tags for).
Out of these 100+ CVEs, GreyNoise tag creation beat CISA's CVE updates 60% of the time, and we tied these updates 5% of the time. You can now search by CVE and set up GNQL like this one we recently published that covers CISA's published list of the top CVEs most used by Chinese state-sponsored attackers. Defenders can then use the pristine block lists (updated by the hour) to either remove the noise before it has a chance to reach them, or filter out the noise from events and alerts to enable significantly faster defense.
This blog will be updated as new information becomes available
Based on our current understanding of the vulnerabilities, CVE-2022-3786 and CVE-2022-3602, patched in OpenSSL 3.0.7, GreyNoise is unlikely to observe opportunistic mass exploitation in the wild.
What is being patched?
On Oct 25, 2022 the OpenSSL project authors announced via mailing list that OpenSSL 3.0.7 would become available on Nov 1st, 2022 between 1300-1700 UTC and include a high severity, marked HIGH, security-fix
The release occurred on Nov 1st, 2022, at 1600 ET and includes fixes for affected versions v3.0.x through v3.0.6. The patch, available here, addresses following issues:
Added RIPEMD160 to the default provider.
Fixed regressions introduced in 3.0.6 version.
Fixed two buffer overflows in punycode decoding functions. CVE-2022-3786 and CVE-2022-3602.
OpenSSL is a library that provides general purpose cryptographic functions. As with any usage of cryptographic operations, there is a reasonable expectation that operation involves sensitive data and any disclosure of information is highly problematic in nature.
The full change log provides the full description of both vulnerabilities as follows:
A buffer overrun can be triggered in X.509 certificate verification, specifically in name constraint checking. Note that this occurs after certificate chain signature verification and requires either a CA to have signed the malicious certificate or for the application to continue certificate verification despite failure to construct a path to a trusted issuer.
In a TLS client, this can be triggered by connecting to a malicious server. In a TLS server, this can be triggered if the server requests client authentication and a malicious client connects.
An attacker can craft a malicious email address to overflow an arbitrary number of bytes containing the `.` character (decimal 46) on the stack. This buffer overflow could result in a crash (causing a denial of service). ([CVE-2022-3786])
An attacker can craft a malicious email address to overflow four attacker-controlled bytes on the stack. This buffer overflow could result in a crash (causing a denial of service) or potentially remote code execution depending on stack layout for any given platform/compiler. ([CVE-2022-3602])
OpenSSL is a library and toolkit that can be used in a variety of ways. The most common integration scopes are via the System, or as a Dynamically or Statically linked library. The security vulnerabilities addressed in today’s patch address versions v3.0.x through v3.0.6. If you are not utilizing a version within that range then you are not affected by these vulnerabilities.
System
If OpenSSL is installed as a toolkit on your system you can quickly check by running the command openssl version which will report back the installed system version.
Dynamically or Statically Linked
When OpenSSL is utilized as a library in a larger program it can be linked Statically or Dynamically.
When OpenSSL is statically linked, the library is bundled into the resulting executable of program when it is compiled, making the single executable contain all of the needed functionality as a single file.
When OpenSSL is dynamically linked, the library is expected to already exist on the system for which the program is expected to run. When the program is executed it searches a list of filesystem paths to locate the OpenSSL library and loads it as needed.
If you have access to the source code for the program you wish to evaluate for this vulnerability, the best way way is check for usage of the openssl3 library in the dependencies.
If you do not have access to source code, we recommend reaching out to the software vendor to ask for an evaluation and corresponding announcement. There are operating system specific methods to attempt to evaluate this yourself, but they require a more complex understanding of how libraries are loaded when a program is run. We recommend reaching out to the software vendor and requesting an announcement if you believe the software may be impacted. The software vendor should be able to answer in confidence.
In a self-evaluation of all of GreyNoise’s infrastructure which included our wide array of honeypot style sensors spread across a large variety of operating systems and cloud providers we did not identify any usage of vulnerable versions of OpenSSL v3.0.x
This will not hold true of all organizations, but it is a data-point we can provide at this time.
What are next steps?
Evaluate your environment for usage of OpenSSL <v3.0.7
Update dependencies to utilize OpenSSL v3.0.7+
Contact software vendor for support if you believe a vulnerable version of OpenSSL is statically linked to software your organization runs.
Industrial Control System (ICS) is a term describing systems that monitor and control industrial processes, such as mine site conveyor belts, oil refinery cracking towers, power consumption on electricity grids, or alarms from building information systems. NIST references them as “encompass[ing] several types of control systems, including supervisory control and data acquisition (SCADA) systems, distributed control systems (DCS), and other control system configurations such as programmable logic controllers (PLC) often found in the industrial sectors and critical infrastructures.”
Why scan for ICS?
Governments often describe ICS as critical infrastructure; they are essential to societal and economic function. Their critical nature means changes, updates, and replacements are risky and costly endeavors. Put simply: ICSs are slow to change with a strong bias toward legacy technology and compatibility.
Many ICSs feature custom network serial-based protocols for coordinating industrial hardware. The rise of the modern internet came with worldwide networking standardization. Without security as a priority, many vendors simply packed their legacy protocols inside TCP or UDP and called their devices network or internet-ready.
ICSs critical nature – combined with lagging security – incentivizes attackers and defenders to scan the internet for exposed devices.
Can I see ICS scanning in GreyNoise?
GreyNoise Researchers have identified and created tags for the following ICS-related protocols:
On October 6th, Fortinet sent an advance notice email to selected customers notifying them of CVE-2022-40684, a critical severity vulnerability (CVSS: 9.6) authentication bypass on the administrative interface of FortiOS / FortiProxy.
How to track FortiOS Authentication Bypass Attempt
GreyNoise was contacted by Horizon3 for collaboration of their ongoing research into the FortiOS vulnerability. They graciously provided the necessary information needed to accurately tag this vulnerability.
GreyNoise users can track IPs attempting to exploit CVE-2022-40684 via:
As of October 13, GreyNoise has observed IPs attempting internet-wide exploitation of this vulnerability, with activity increasing quickly over the past 24 hours. We are aware of several Proof-Of-Concept (POC) code examples to exploit CVE-2022-40684 and expect related exploitative network activity to continue to increase now that these are publicly available.
FortiOS handles API calls by proxying all requests to an interface that is only accessible internally. This internal interface is responsible for verifying authentication and authorization. Proxied requests contain some additional parameters which can be used by FortiOS to bypass or authenticate internal requests. This allows an attacker to masquerade as an internal system API call, bypassing authentication on all externally-facing API endpoints.
Horizon3 has demonstrated leveraging the exploit to achieve authenticated SSH access to vulnerable devices as well as a blog on relevant Indicators Of Compromise (IOCs):
Independent of any knowledge of Horizon3’s collaboration with GreyNoise, one of our engineers (Ian Ling) got curious and spent some time over the weekend researching the vulnerability, leading to successful exploitation with a slightly different methodology.
Authentication bypass in FortiOS / FortiProxy (CVE-2022-40684) is trivial to exploit and users should patch or employ mitigations immediately.
Recommended next steps
If you need to buy time under SLAs: use a block list and apply mitigations, check for presence of IOCs, and work towards upgrading software.
Tenable partnership improves threat intelligence data quality for the entire cybersecurity industry
Today, Tenable announced its new Research Alliance Program to share vulnerability information prior to public disclosure. GreyNoise is proud to be an inaugural member of this program, which aims to reduce the window of opportunity for threat actors seeking to exploit newly discovered vulnerabilities.
At a high level, cyber threat intelligence is the craft of predicting what villains and miscreants are going to do on the internet—including how, why, and where they will do it. Unfortunately, most threat intelligence solutions have not delivered on this promise. Within the wider cybersecurity community, threat intelligence is often viewed as a commodity that brings unquantifiable business value and uncertain security value. Over time, this dynamic has caused the security community to lose faith in the entire concept.
Closing a gap in traditional threat intel
Here is the root of the problem: while many threat intelligence providers are great at cybersecurity, they are bad at providing data in a way that is useful for their customers. Generally speaking, the data provided by most threat intelligence solutions is of poor quality, because it is based on inaccurate assumptions. Some solutions even lack the conviction to provide guidance on how to make automated block decisions based on their data. And if a machine can’t use the data, how useful can it be?
As an industry, cybersecurity needs to get better at sharing information about threats–including what organizations are encountering and what they are doing to defend themselves. To compare with the airline industry, plane crash investigations are an enormous collaborative effort involving input from dozens of governmental organizations and industry partners. Their collaboration creates insights that improve flight safety for everyone, long into the future; cybersecurity can learn much from this approach.
Why data-sharing matters
As the primary source for understanding internet noise, GreyNoise believes that sharing data about threat intelligence with other industry partners will improve data quality for the entire industry. The combination of Tenable vulnerability data with the real-time mass exploit awareness that GreyNoise provides will help our mutual customers and industry partners to respond faster (and more accurately) to newly emerging vulnerabilities.
“Whenever a vulnerability is disclosed, the dinner bell sounds for good and bad actors alike, meaning organizations are already on their back foot,” explains Robert Huber, Tenable Chief Security Officer and Head of Research. “We know threat actors are monitoring disclosure programs in the same way we are, looking for newly announced vulnerabilities, studying all available information such as proof of concepts, but they’re looking to utilize the flaw. By giving our customers the tools to address these weaknesses when they’re publicly announced, we reduce that intelligence gap and hand the advantage back to the good guys.”
To ensure we have as much visibility into activity on the internet as possible, we regularly deploy new sensors in different “geographical” network locations. We’ve selected two sensors for a short “week in the life” series to give practitioners a glimpse into what activity new internet nodes see. This series should help organizations understand the opportunistic and random activity that awaits newly deployed services, plus help folks understand just how little time you have to ensure internet-facing systems are made safe and resilient.
The “Benign” perspective
Presently, there are three source IPv4 classifications defined in our GreyNoise Query Language (GNQL): benign, malicious, and unknown. Cybersecurity folks tend to focus quite a bit on the malicious ones since they may represent a clear and present danger to operations. However, there are many benign sources of activity that are always on the lookout for new nodes and services, so we’re starting our new sensor retrospective by looking at those sources first. Don’t worry, we’ll spend plenty of time in future posts looking at the “bad guys."
While likely far from a comprehensive summary, there are at least 74 organizations regularly conducting internet service surveys of some sort (we’ll refer to them as ‘scanners’ moving forward):
AdScore
Ahrefs
Alpha Strike Labs
Ampere Innotech
ANT Lab
Applebot
Arbor Observatory
Archive.org
BinaryEdge.io
BingBot
Bit Discovery
Bitsight
BLEXBot
Caida
Censys
CERT-FR
Cloud System Networks
Cloudflare
Cortex Xpanse
CriminalIP
cyber.casa
CyberGreen
cymru
dataplane
DomainTools
Dutch Institute for Vulnerability Disclosure
errata
ESET
Facebook Crawler
FH Muenster University
GoogleBot
Internet Census
InterneTTL
Intrinsec
IPinfo.io
ipip.net
ipqualityscore
Knoq
LeakIX
Mail.RU
Max Planck Inst.
Moz DotBot
Net Systems Research
NetCraft
netsystems
ONYPHE
OpenIntel.nl
openportstats
Palo Alto Crawler
Petalbot
pnap
Project Sonar
Project25499
Quadmetrics.com
Qualys
Qwant
Recyber
RWTH AACHEN University
scorecardresearch
SecurityTrails
Seznam
ShadowServer.org
Shodan.io
Sogou
spyse
Stanford Univ.
stretchoid
Technical University of Munich
threatsinkhole
UMich
University of Colorado
VeriSign
WithSecure
Yandex Search Engine
We were curious as to how long it took these scanners to find our new nodes after they came online and were ready to accept connections. We capped our discovery period exploration at a week for this analysis but may dig into longer time periods in future updates.
Out of the 74 known scanners, only 18 (24%) contacted our nodes within the first week.
As the above chart shows, some of the more well-known scanners found our new sensor nodes within just about an hour after being booted up. A caveat to this data is that other scanners in the main list may have just tried contacting the IP addresses of these nodes before we booted them up.
One reason organizations should care about this metric is that some of these scanners are run by “cyber hygiene” rating organizations, and you only get one chance to make a first impression that could negatively impact, say, your cyber insurance premiums. So, don’t deploy poorly configured services if you want to keep the CFO happy.
Benign infrastructure
It’s pretty “easy” to scan the entire internet these days, thanks to tools such as Rob Graham’s masscan, provided you like handling abuse complaints and can afford the bandwidth costs on providers that allow such activity. We identified each of these scanning organizations via their published list of IPs. We decided to see just how many unique IPs of each scanner we saw within the first week:
Bitsight dedicates a crazy amount of infrastructure to poke at internet nodes. Same for the Internet Census. By the end of the week, we saw 346 unique benign scanner IPs contact our sensors, which means your internet-facing nodes likely did as well. While you may not want these organizations probing your perimeter, the reality is that, while you may be able to ask them to opt you out of scanning, you cannot do the same for attackers (abuse complaints aren’t a great solution either). Some organizations, ShadowServer in particular, are also there to help you by letting you understand your “attack surface” better, so you are likely better off using our benign classified IPs to help thin down the alerts these services likely generate (more on that in a bit).
The chart above also shows that some services have definite “schedules” for these scans, and others rarely make contact. Just how many contacts can you expect per day?
Hopefully, you are using some intelligent alert filtering to keep your defenders from being overloaded.
What are the scanners looking for?
Web servers may rule the top spot of deployed internet-facing services, but they aren’t the only exposed services and they aren’t just hosted on ports 443 and 80 anymore. Given how many IP addresses some scanners use and how many times the node in the above example was contacted by certain scanners, it’s likely a safe assumption that the port/service coverage was broad for some of them. It turns out, that assumption was spot-on:
At least when it comes to this observation experiment, Censys clearly has the most port/service coverage out of all the benign scanners. It was a bit surprising to see such a broad service coverage in the top seven providers, although most have higher concentrations below port 20000.
If you think you’re being “clever” by hosting an internet-facing service on a port “nobody will look at," think again. Censys (and others’) scans are also protocol-aware, meaning they’ll try to figure out what’s running based on the initial connection response. That means you can forget about hiding your SSH and SMB servers from their watchful eyes. As we’ll see in future posts, non-benign adversaries also know you try to hide services, and are just as capable of looking for your hidden high port treasure.
Going beyond benign
If we strip away all the benign scanner activity, we’re left with the real noise:
We’ll have follow-up posts looking at “a week in the life” of these sensors to help provide more perspectives on what defenders are facing when working to keep internet-facing nodes safe and sound.
Remember: you can use GreyNoise to help separate internet noise from threats as an unauthenticated user on our site. For additional functionality and IP search capacity, create your own GreyNoise Community (free) account today.
These vulnerabilities are also being tracked by Zero-Day Initiative (ZDI), who demonstrated the exploit on Twitter, under ZDI-CAN-18333 and ZDI-CAN-18802.
Additionally, the write-up authors note that they “detected exploit requests in IIS logs with the same format as ProxyShell vulnerability.” Using this information, GreyNoise researchers searched historical sensor records from 2021-01-01 to 2022-09-29 for Proxyshell-related backend paths. GreyNoise has not observed any new backend paths in use since 2021-08-27.
The GreyNoise Analyzer shows that four of the IOC IPs have been observed by GreyNoise:
At this time, GreyNoise has not observed anything believed to be related to the vulnerability from these IPs in the past year.
Ongoing Monitoring
Microsoft indicated that CVE-2022-41040 could enable an authenticated attacker to trigger CVE-2022-41082 remotely. This vulnerability is similar to the 2021 ProxyShell vulnerability, which involved fabricating an authentication token. At this time, we lack the information necessary to determine if “ProxyNotShell” leverages a similar authentication token leak.
GreyNoise tags are described in the documentation as “a signature-based detection method used to capture patterns and create subsets in our data.” The GreyNoise Research team is responsible for creating tags for vulnerabilities and activities seen in the wild by GreyNoise sensors. GreyNoise researchers have two main methods for tagging: a data-driven approach, and an emerging threats-driven approach. Each of these approaches has three main stages:
Discovery
Research
Implementation
Data-driven approach
When using a data-driven approach, researchers work backward from the data collected by GreyNoise sensors. Researchers will manually browse data or create tooling to aid in finding previously untagged and interesting data. This method relies heavily upon intuition and prior expertise and has led to non-vulnerability-related discoveries such as a Holiday PrintJacking campaign. Using this approach, GreyNoise steadily works toward providing some kind of context for every bit of data opportunistically transmitted over the internet to our sensors.
During the discovery phase, researchers identify interesting data that does not appear to be tagged by manual or tool-assisted browsing of raw sensor data. Researchers will simply query the data lake for interesting words or patterns, using instinct to drive exploration of the data. Once they have identified and collected an interesting set of data, they begin the research phase.
During the research phase, the researcher works to identify what the data is. This could be anything from CVE-related traffic to a signature for a particular tool. They do this by scouring the internet for various paths, strings, and bytes to find documentation relating to the raw traffic. This often requires the researcher to be adept at reading formal standards, like Requests for Comments, as well as reading source code in a variety of programming languages. Once they have identified the data, the researcher will gather and document their findings before moving on to the implementation phase.
Using their research, the researcher will implement a tag by actually writing the signature and populating the metadata that makes it into a GreyNoise tag. Once complete, a peer will review the work, looking for errors in the signature and false positives in the results before clearing it for production.
Emerging threats approach
When using an emerging threats-driven approach, researchers seek out emerging threats observable by GreyNoise sensors. For the most part, GreyNoise only observes network-related vulnerability and scanning traffic. This rules out vulnerabilities like local privilege escalations. Using this method, GreyNoise can provide early warning for mass scanning or exploitation activity in the wild of things like CVE-2022-26134, an Atlassian Confluence Server RCE.
During the discovery phase, researchers monitor a wide variety of sources such as tech news outlets, social media, US CISA’s Known Exploited Vulnerabilities Catalog, and customer/community requests. Researchers identify and prioritize CVEs that customers and community members may be interested in due to their magnitude, targeted appliances, etc.
Similar to the data-driven approach, researchers will gather publicly available information regarding the emerging threat that will allow them to write a signature. Proof-of-Concept (PoC) code is often the most useful piece of information. On rare occasions, lacking a PoC, researchers will sometimes attempt to independently reproduce the vulnerability. Researchers will often attempt to validate vulnerabilities by setting up testbeds to better understand what elements of the vulnerability should be used to create a unique and narrowly scoped signature.
Finally, using all collected information, the researcher will seek to write the signature that becomes a tag. When doing this, researchers focus on eliminating false positives and tightly scoping the signature to the targeted data or vulnerability. When relevant for emerging threats, GreyNoise researchers will run this signature across all of GreyNoise’s historical data to determine the date of the first occurrence. This allows GreyNoise to publish information regarding when a vulnerability has first seen mass exploitation in the wild and, occasionally, if a vulnerability, like OMIGOD, was exploited before exploit details were publicly available.
How to use GreyNoise tags
GreyNoise provides insight into IP addresses that are scanning the internet or attempting to opportunistically exploit hosts across the internet. Tag data associated with a specific IP address provides an overview of the activity that GreyNoise has observed from a particular IP, as well as insight into the intention of the activity originating from it. For example, we can see that this IP is classified as malicious in GreyNoise because it is doing some reconnaissance but also has tags associated with malicious activity attempting to brute force credentials as well as traffic identifying it as part of the Mirai botnet.
GreyNoise tags are also a great way to identify multiple hosts that are scanning for particular items or CVEs. For example, querying for a tag and filtering data can show activity related to a CVE that is originating from a certain country, ASN, or organization. This gives a unique perspective on activity originating from these different sources.
Finally, tag data is accessible via the GreyNoise API and allows integrations to add this tag data easily into other products.
For approximately 12 weeks this summer, I got to work as an intern on the GreyNoise Intelligence research team. During my time in the GreyNoise internship program, I did great things with amazing people while learning a lot about the workplace (as well as myself).
GreyNoise intern team project - IoT vulnerability research
Given an arsenal of ideas, the intern team decided to centralize the primary goal of our summer internship project around finding a vulnerability in an Internet of Things (IoT) device, release a proof of concept, disclose the vulnerability, and then track the lifecycle of the vulnerability using the GreyNoise dataset. While we did not end up locating a vulnerability, the experience of attempting to achieve this task taught me many non-technical skills.
Walking into this program, I did not have prior work experience. Having previously done contracting, the process of working with a team – let alone communicating with a group – was a whole new experience for me. I had many opportunities to hone my communication skills (which I learned is an area that will always need improvement) and to grow relationships with the research team. Looking back, one of my favorite experiences was observing how everyone on the research team interacted both inside and outside of the office and how they supported each other throughout the day.
When I assisted the research team (and didn’t work on the internship project), I was able to contribute to a company mission that I feel passionate about, which isn’t a luxury that many people have. Working alongside the researchers gave me the opportunity to meet people from other departments (e.g., engineering, data science, sales), and I enjoyed seeing how the various teams interacted and how well everyone meshed together.
As related to the job function, I was able to learn about how the research team produces content for blogs, writes tags, and interacts with customers. I learned how to answer a customer’s request for technical support, and I researched the (now deprecated) EternalBlue tag to better understand what customers were experiencing.
In terms of personal betterment, I learned that while I used to be good at time management, I can easily unlearn that skill. I realized the importance of working on communication with others, staying focused, setting realistic expectations for myself and the speed at which I can work, and setting a structured schedule for when things need to be completed. In hindsight, I think the reason I was able to get other things done (like school assignments) was the fear factor, but I know that’s not practical in any setting and that milestones for progress should be set on my end without stressing myself out.
Key takeaways from my GreyNoise internship
Below are some of the key takeaways I’ve gleaned from my experiences during the summer internship program:
The intern program was a fantastic experience overall.
I had the chance to discover more about GreyNoise from an internal point of view.
I was able to learn about what each team does and how they do it.
The biggest challenge was time management; different factors ended up shortening the amount of time that was allocated to actually completing work.
The internship allowed me to grow as an individual, both technically and personally.
Technical growth:
I learned much about the project, how research functions, and how engineering operates.
I got to experience deep-diving into different rabbit holes (both research and non-research related) to see how those areas relate to the main product.
Personal growth:
I learned more about how I operate in a work environment, as well as an understanding of what I need to improve in order to successfully complete tasks within a timeline.
I experienced growth in my communication skills by interacting with the research team and participating in work-related social events (I tend to be either super-introverted or super-extroverted, so it was good to find a balance between these two traits).
I adapted skills from advice and mentorship that assisted me in communicating thoughts and opinions both inside and outside of the workplace.
Overall, I learned a great deal both technically and professionally from interning with the GreyNoise research team this summer. I discovered that I deeply enjoy conducting all sorts of research, then writing about the research. I obtained valuable workplace skills and realized that I have a lot more to learn about working in the real world. I’m extremely grateful to have had the experience of working at GreyNoise this summer, and I’m excited to see how the company grows – and I have absolutely loved being involved.
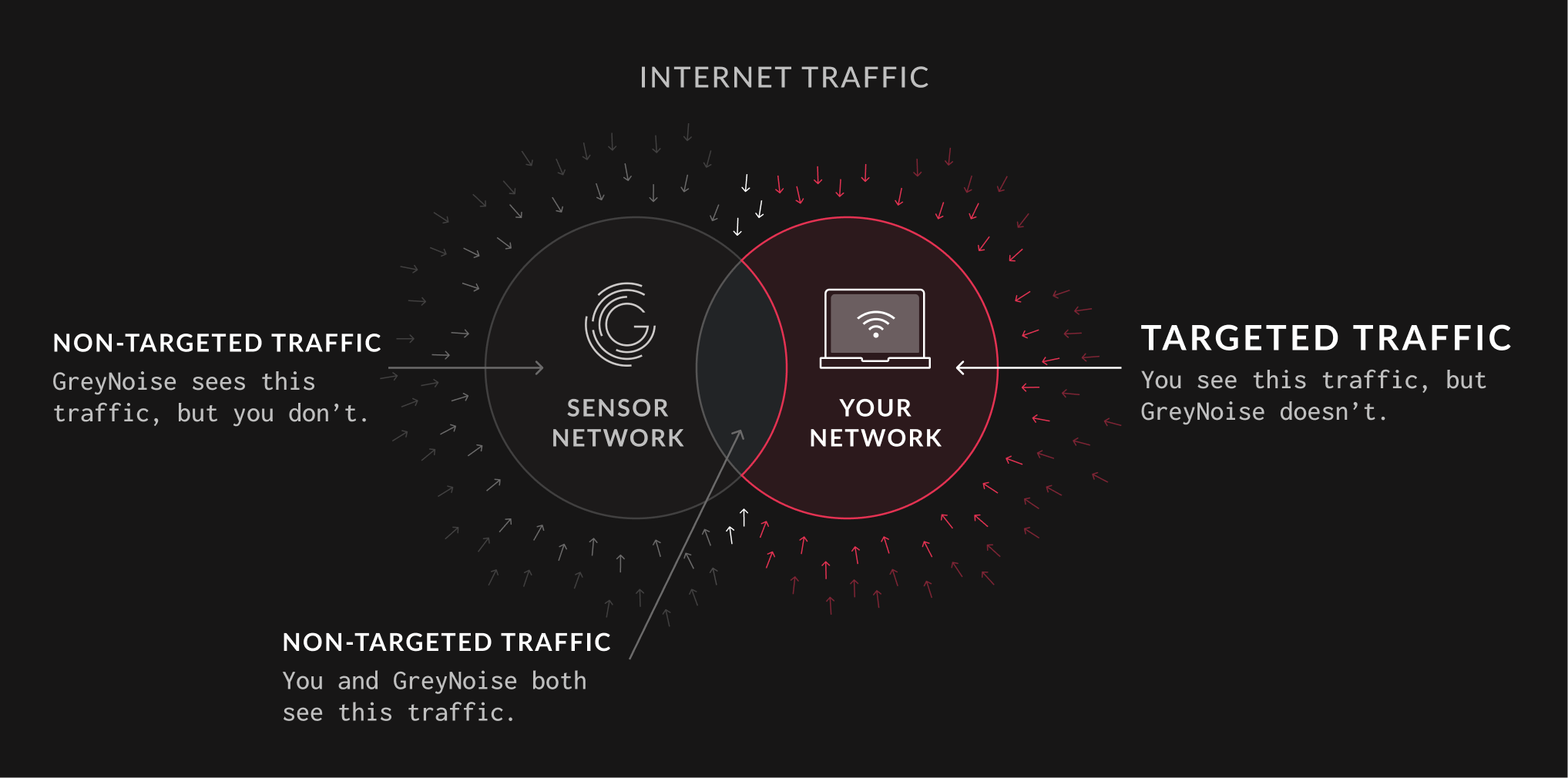
One of the most valuable attributes of GreyNoise is the ability to increase Security Operations Center efficiency by providing context, which allows the relevant security personnel to prioritize alerts. We listen and collect data from around the world from IP addresses that are opportunistically scanning the internet. We intentionally do not solicit traffic and rotate the IPs our services listen on frequently to preserve one of the most important attributes of the GreyNoise dataset: All traffic we observe is unsolicited in nature.
This attribute of our dataset allows us to quickly provide contextual information to answer the question, “Is my organization the victim of a targeted attack?”
On the left is the IP traffic GreyNoise can observe. On the right is the IP traffic a given organization may observe. Where these two groups overlap is the traffic seen by both GreyNoise and your organization. Unfortunately, this means that targeted network requests to your organization may frequently be outside of what GreyNoise can see.
If your organization observes traffic from an IP that has not been observed by GreyNoise, this traffic is likely targeted at your organization due to business verticals, software vendors in use, or implied value. Alerts falling into this category deserve a higher priority for investigation.
The largest volume of traffic targeted at your organization will likely be sourced from your desired user base or from automated tooling specific to your organization’s needs, such as API calls. As this is a near-constant occurrence, your security and infrastructure team are best equipped to recognize and identify what qualifies as normal.
Of course, there is also malicious network traffic targeted at your organization that GreyNoise may not have observed. Despite it being targeted, GreyNoise can still help provide context.
Consider that your organization has observed HTTPS traffic to the path “/v2.57/version” from an IP that GreyNoise has not observed. The GreyNoise Query Language (GNQL) supports wildcards, meaning that values and attributes of network requests that are specific to your organization, such as version differences in software, can be omitted in order to return query results that preserve the overall structure of the request.
This allows you to surface IPs and context that GreyNoise has observed that share structural similarities with traffic observed by your organization that GreyNoise has not observed.
While this type of context association is fuzzy in nature, we can still quickly ascertain that the traffic observed by your organization is likely to be targeting web-accessible containerization software.
Since the traffic observed by your organization was HTTPS, you can further combine and pivot stricter fingerprints such as JA3 hashes to rapidly create actionable documentation for investigations of targeted network traffic.
If you’ve worked in a SOC, you might know this scene:
You clock into work, open the SIEM, and see RAT alerts. Hundreds of them.
Scary, right? Until one of your coworkers goes, “Oh, the RAT alerts. Yeah, just close those out; those are all false positives.”
But how can you be sure?
Actually, you cannot be sure - or, not right away. First, it is crucial to look into how the RATs - Remote Access Trojans - are communicating with each other and their command and control servers.
What’s the difference between beaconing and crawling?
Remote Access Trojans (viruses used to establish persistent remote access to computers) are typically found using beacons. As you can imagine, there are many methods for beaconing multiplied across as many ports and protocols. In a single day, you might see a RAT “beaconing” via IRC, random UDP packets sent to a command and control server, feeding directly into a Discord bot, or even sending requests via Gopher protocol.
The broadest definition of beaconing is when a RAT communicates to its Command and Control (C2) server. This often appears as if the machine itself is communicating with the RAT C2.
Crawling
Crawling, broadly defined, is a server scanning known IP addresses for machines that have installed RATs. Before communicating with a command and control server, the operator will need to see which machines are infected and have communication open. For that purpose: they may crawl the internet, sending a message to every machine and network that might have been infected, hoping for a response from the RAT itself.
Beaconing
We will often observe beaconing and crawling for the same malware, with the beacon and crawl playing a game of call-and-response between the infected machine and a command and control server.
Beaconing can be hard to verify. Sometimes we have observed unique packets on a seemingly random UDP port, only to find out telemetry is being sent by a legitimate program. Crawling, on the other hand, can be easier to find. Typically a crawler tries to send a set payload in order to get a response from the RAT
This article focuses on what we can do with crawling activity.
On this page, many results appear (with mixed reputations). Some of them are from other security companies doing routine scanning for gh0st RAT traffic to monitor the spread of the RAT. However, others are from anonymous servers and may be malicious.
These detections are from a tag GreyNoise has written based on a common hex-encoded header that the crawler sends when checking for gh0st RAT-infected machines.
I found crawler traffic on my network. What should I do?
Using the example of gh0st RAT crawler traffic, there are a few things you may want to consider.
One consideration is the kinds of devices being scanned: gh0st RAT is typically found on Windows machines. Is the crawler coming from a benign source and hitting a Linux server? Perhaps don’t worry about that.
Another factor is where in the network your machine is positioned. It is common for edge devices (web servers and firewalls are two examples) to be constantly scanned at all times by any number of devices for any number of reasons. Is the crawling excessive? You may want to check the source of the crawler to verify if it is a legitimate source. If not, it doesn’t hurt to block them at the firewall.
Finally, are your machines responding? If so, you may want to review your network for signs of compromise. Take stock of any outbound traffic your machine is sending in response to the crawler. If you see that your machine is already ignoring the crawler, you may want to run a quick antivirus scan for peace of mind and carry on. If you’re seeing unfamiliar responses or traffic that’s not usual for your network: perhaps run a thorough antivirus scan, disable RDP on the machine in question, and block the IP address trying to contact you. You may also want to conduct an internal investigation to make sure no data has been exfiltrated if you’re sure that there was a successful connection between your machine and the server trying to communicate with it.
This is where GreyNoise can help your process: by integrating GreyNoise into your environment, you can look for this crawling traffic and determine the reputation of whoever is doing the crawling, taking some of the leg work out of your investigation and response. When minutes count, even saving a few clicks can help.
Practical takeaways from CISA's Cyber Safety Review Board Log4j report
The Cybersecurity and Infrastructure Security Agency (CISA)'s Cyber Safety Review Board (CSRB) was established in May 2021 and is charged with reviewing major cybersecurity incidents and issuing guidance and recommendations where necessary. GreyNoise is cited as a primary source of ground truth in the CSRB's first report (direct PDF), published on July 11, 2022, covering the December 2021 Log4j event. GreyNoise employees testified to the Cyber Safety Review Board on our early observations of Log4j. In this post, we'll examine key takeaways from the report with a GreyNoise lens and discuss what present-day Log4j malicious activity may portend.
Log4J retrospective
It may seem as if it's been a few years since the Log4j event ruined vacations and caused quite a stir across the internet. In reality, it's been just a little over six months since we published our "Log4j Analysis - What To Do Before The Next Big One" review of this mega-incident. Since that time, we've worked with the CSRB and provided our analyses and summaries of pertinent telemetry to help them craft their findings.
The most perspicacious paragraph in the CSRB's report may be this one:
Most importantly, however, the Log4j event is not over. The Board assesses that Log4j is an “endemic vulnerability” and that vulnerable instances of Log4j will remain in systems for many years to come, perhaps a decade or longer. Significant risk remains.
In fact, it reinforces their primary recommendation: "Organizations should be prepared to address Log4j vulnerabilities for years to come and continue to report (and escalate) observations of Log4j exploitation."(CSRB Log4j Report, pg. 6)
The CSRB further recommends (CSRB Log4j Report, pg. 7) that organizations:
develop strong configuration, asset, and vulnerability management practices
invest resources in the open-source ecosystems they depend upon
follow the lead of the Federal government and require and use Software Bill of Materials (SBOM) when sourcing software and components
This is all sound advice, but if your organization is starting from ground zero in any of those bullets, getting to a maturity level where they will each be effective will take time. Meanwhile, we've published three blogs on emerging, active exploit campaigns since the Log4j event:
Furthermore, CISA has added over 460 new Known Exploited Vulnerabilities (KEV) to their ever-growing catalog. That's quite a jump in the known attack surface, especially if you're still struggling to know if you have any of the entries in the KEV catalog in your environment.
While you're working on honing your internal asset, vulnerability, and software inventory telemetry, you can improve your ability to defend from emerging attacks by keeping an eye on attacker activity (something our tools and APIs are superb at), and ensuring your incident responders and analysts identify, block, or contain exploit attempts as quickly as possible. That's one area the CSRB took a light touch on in their report, but that we think is a crucial component of your safety and resilience practices.
Log4j today
Log4j is (sadly, unsurprisingly) alive and well:
This hourly view over the past two months shows regular, and often large amounts of activity by a handful (~50) of internet sources. In essence, Log4j has definitely become one of the many permanent and persistent components of internet "noise," and this is a further confirmation of CISA's posit that Log4j is here for the long haul. As if on queue, news broke of Iranian state-sponsored attackers using the Log4j exploit in very recent campaigns, just as we were preparing this post for publication.
If we take a look at what other activity is present from those source nodes, we make an interesting discovery:
While most of the nodes are only targeting the Log4j vulnerability, some are involved in SSH exploitation, hunting for nodes to add to the ever-expanding Mirai botnet clusters, or focusing on a more recent Atlassian vulnerability from this year.
However, one node has merely added Log4j to the inventory of exploits it has been using. It's not necessary to see all the tag names here, but you can explore these IPs in-depth at your convenience.
Building on the conclusion of the previous section, you can safely block all IPs associated with the Apache Log4j RCE Exploit Attempt tag or other emerging tags to give you and your operations teams breathing room to patch.
You are always welcome to use the GreyNoise product to help you separate internet noise from threats as an unauthenticated user on our site. For additional functionality and IP search capacity, create your own GreyNoise Community (free) account today.
Indian Computer Emergency Response Team (CERT-In) issued sweeping new directions to sub-section (6) of section 70B of the Information Technology Act, 2000.
Mandates include reporting of ANY cyber security incident to CERT-In, including targeted scanning of systems, within 6 hours of noticing such incidents.
Enforcement deadline is 25-Sep-2022 and applies to virtually all organizations with operations in India.
GreyNoise helps customers comply with targeted scanning reporting requirements by allowing them to separate irrelevant "mass scanners" from targeted scanners.
Ready for updated security incident reporting requirements from CERT-In?
On 28-April-2022, in light of escalating cyber attacks in India, the Indian Computer Emergency Response Team (CERT-In) issued new directions to sub-section (6) of section 70B of the Information Technology Act, 2000. Among other expanded requirements, the new directions mandate reporting of any cyber security incident, including targeted scanning of systems and data breaches, within 6 hours of noticing the incident to CERT-In. Prior to this change, CERT-In had been allowing organizations to report the incidents within “a reasonable time.”
The implications and sweeping nature of the changes caused quite a stir in the security community when initially released, especially since organizations ranging from service providers, intermediaries, data centers, government entities, and corporations, all the way down to small and medium businesses, need to follow CERT-In requirements.
The directions were to become effective 60 days from the date of issuance in April. However, after receiving a large volume of feedback from affected organizations, CERT-In extended the enforcement deadline to 25-September, 2022. Despite the reprieve on the enforcement deadline, responses to the CERT-In’s standing FAQ indicate that the national agency is not inclined to adjust the main provisions it introduced.
GreyNoise helps customers identify and respond to opportunistic “scan-and-exploit” attacks in real time. In the case of CERT-In’s new reporting mandate, GreyNoise helps customers filter opportunistic mass-scanning activity out of their alerts, so they can focus (and report on) targeted scanning activity. GreyNoise’s guidance on how to automate the process of detecting and reporting on targeted scanning/probing of critical networks and systems is below.
Section 70B directions scope
At a high level, the new CERT-In directions require organizations to:
Enable logs of all their Information and Communication Technologies (ICT) systems
Retain logs for 180 days
Synchronize time with National Informatics Centre’s Network Time Protocol
Define a special point of contact for this activity and share their credentials with CERT-In
Ensure that Virtual Private Server (VPS) providers, cloud service providers, and Virtual Private Network Service (VPN service) providers maintain accurate information, such as name of the subscriber and IP address for a minimum of five years
Report to CERT-In within 6 hours of any “qualified cybersecurity incidents,” which are summarized in the following excerpt from CERT-In Directions for Section 70B:
CERT-In defines “Targeted scanning/probing of critical networks/systems” as:
The action of gathering information regarding critical computing systems and networks, thus, impacting the confidentiality of the systems. It is used by adversaries to identify available network hosts, services and applications, presence of security devices as well as known vulnerabilities to plan attack strategies.
Not all scans are created equal
These days, every machine connected to the internet is exposed to scans and attacks from hundreds of thousands of unique IP addresses per day. While some of this traffic is from malicious attackers driving automated, internet-wide exploit attacks, a large volume of traffic is benign activity from security researchers, common bots, and business services. And some of it is just unknown. But taken together, this internet noise triggers potentially thousands of events requiring human analysis. Given the expansive wording and stringent timeline of the directions, it’s crucial to intelligently reduce the number of alerts that are in scope and quickly prioritize mass exploit and targeted activity.
Automate reports of targeted scanning with GreyNoise
Using GreyNoise, you can effectively identify IP addresses that are connecting to your network and prioritize those that are specifically targeting your organization (versus non-targeted, opportunistic scanning that can be ignored).
In this representative scenario, we have configured our perimeter firewalls to send logs to Splunk.
Using the GreyNoise App for Splunk (which you can install from Splunkbase), you can configure the gnfilter command to query the IP addresses against GreyNoise API and only return events that GreyNoise has not observed.
Important note - GreyNoise data identifies IP addresses that “mass-scan” the internet - so If GreyNoise has NOT observed an IP address, that means it is potentially “targeted" scanning activity.
For better presentation, the results are deduplicated and stored as a table.
Within Splunk Enterprise, adjust the query to reflect events in the last 6 hours:
By selecting Search, the query will enrich all the filtered IP addresses against GreyNoise data and return only those IP addresses that have not been observed across our distributed sensor network.
In our case, the query returned seven IP addresses for which GreyNoise has not seen activity.
Prioritize this filtered list for additional analysis to rule out targeted scanning on your infrastructure.
To automate this process going forward, save the query as an Alert. You can adjust the Cron Expression to set a query frequency. In this example, it is set to every 6 hours.
Before clicking Save, consider two other helpful actions for configuration: setting a destination email address for the alert, and then formatting the results as a CSV file.
With the alert configured, our query will run every 6 hours to ensure that any IP addresses that should be prioritized for analysis are packaged in a CSV format for review.
Next steps
To learn more about how GreyNoise can help you comply with the updated reporting mandates from CERT-In, reach out to schedule a demo with one of our technical experts.
Defenders have a remarkably tough job. They must understand — to the largest extent possible — which event needs investigating right now. There are many triggers for such events, but a major one is knowing when their threat landscape has changed. More specifically, defenders need to know when traffic (and actor) behavior has changed sufficiently to warrant taking notice or action.
Change detection comes in many forms. One such form comes under the lofty heading of "anomaly detection," which may also be referred to as "trend detection." Most modern detection and response solutions have some sort of anomaly detection capability.
GreyNoise has recently introduced a new trend detection feature in our platform that will help inform both researchers and organization defenders about potentially new or dangerous traffic behavior changes as quickly as possible. This gives researchers and defenders the necessary context to decide if further action is warranted.
Background on trends and anomalies
Our new Anomaly/Trend Detection feature operates on Tags, GreyNoise’s automated event labeling system. Our processing takes signatures developed by our Research team and applies tags to the packet traffic from our sensor network. These tags are used to add context from actor attribution to behavior, including scanning, crawling, or exploitation events. Each one represents a particular kind of traffic: malicious, benign, or as yet unknown. Each can also encompass one or more protocols, vulnerabilities, and/or exploits.
Monitoring tag behavior over time is a large part of GreyNoise’s value. Because we see how many sensors are hit with traffic events labeled with a particular tag every hour, we can assess which tags are becoming more popular, which ones are experiencing a near-term anomaly in traffic (possibly a notable event in itself), and which are going quiet. At GreyNoise, we look for opportunities to filter out the noise. Traffic that trends upward or exhibits an anomalous "spike" is noteworthy because it is "noisy.”
How it works
Detecting trends and anomalies is about finding deviation from previous behavior, particularly in a positive direction. Both tasks start with finding the average over a long period, at least ten days. The Trends tab looks at slower increases in traffic for a specific tag, comparing the long-term average to a short-term, more recent average, and doing the classic percent-change formula. This produces a value we can use to rank which tags are seeing the largest increase in average traffic.
Immediately above is one example of “trending” behavior.
Detecting an anomaly (as seen immediately above) is somewhat trickier, as we’re not interested in alerting on every recent anomaly. Indeed, it’s not inconceivable that a “quiet” tag that’s gone unseen for a while could suddenly start appearing intermittently (see below). That tag could very well get a separate report for each anomaly, even if each anomaly is not all that tall compared to its neighbors.
We have to find a single recent peak, and preferably the highest. We do so with two algorithms: first, we use a moving window to determine which sample(s) have the largest (positive) deviation from the average value for that window. Second, we check for a change in slope, as a peak signifies a change from increasing to decreasing behavior. Between the two algorithms, we can find peaks reliably, accurately, and precisely. The peak values are then subjected to the percent change formula, so we can compare anomalies and trends for each tag.
Ranking the output of these algorithms, we present the tags that have the largest recent increase in trend as well as the tallest recent peak, both relative to previous average behavior.
What to do about it
Loading up our Tag Trends page, you’ll see trending tags and anomalies: lists of the tags exhibiting each of the behaviors the strongest out of our vast collection of known tags.
Trending tags are showing a marked increase in average traffic; that is, the average now is relatively greater than previously. This could continue over time, suggesting the possibility of the related vulnerabilities being more commonly exploited (or at the very least, more commonly seen in data from one’s inbound internet security perimeter). This raises the odds of seeing it on our customer’s own perimeter, and therefore increases the urgency for monitoring in more detail and patching, if possible.
Anomalies in a tag manifest sudden jumps in behavior–and could be more useful to see what already happened than for projection about future behavior. Anomalies, by our internal definition, have already started to ebb, so the real “peak” has passed. With the largest anomalies listed, though, we can note the timing of large events/incidents that may illuminate what happened and how. However, it is possible that repeated anomalies could signal a new behavior pattern of intermittent bursts of activity: then the timing between those anomalies could show coordination, how many groups are involved, or even in which time zones they likely operate.
What is particularly powerful is the ability to raise the conversation around tags (and therefore particular exploit vectors) as soon as they’re seen in numbers “in the wild,” instead of waiting for a particular exploit to hit the news. Additionally, each tag notes a particular approach. So, if a product has multiple potential exploits one could patch for, the tag (or tags) that are seeing the most traffic should be patched soonest.
All this being said, of course, these behaviors may not be seen on your perimeter. You may load the Tag Trends page and find that none of the “trending” tags are increasing their traffic for you, and you may be seeing traffic on other vectors. This is perfectly normal, and likely indicates that your firewall is doing its job, or that your attack surface is minimized to the threats and activity on the web at large. You may also be investigating a sudden wave of traffic of a particular type, and see that it didn’t make our Anomalies list. This means that, likely as not, your wave of traffic is more targeted than it may appear at first, and perhaps some caution may be warranted.
A note on data over time
There’s been some talk in the last few paragraphs about possibilities because this is largely cutting-edge research in cybersecurity. Already, we have seen tags which saw a drop in behavior that appear to be trending (as said drop passes out of the recent time window). The movement of the drop drags down the previous baseline, which makes the resumption of normal activity look like it’s trending to the algorithm. Perhaps it’s not trending upward from where it started, but the whole sample still exhibits notable behavior; sometimes the resumption of normal behavior out-trends the weaker actual “trending” tags. Notable behavior is notable behavior.
There are more exotic patterns lurking in the time series data that our researchers already know and recognize. For us, it’s a matter of building a statistical system around that recognition so we can further automate. No one knows all of what’s possible out there, but we’re listening, so we know better than many. As soon as GreyNoise finds something new, you can rest assured that our findings make their way into refining this feature and other features to come.
On April 20th, 2022, NVD published CVE-2022-27925, a vulnerability in Zimbra Collaboration Suite (ZCS) 8.8.15 and 9.0 that allowed an authenticated user with administrator rights to upload arbitrary files to the system, leading to directory traversal.
On August 10th, 2022, Volexity published a blog investigating CVE-2022-27925 and announcing their discovery of an authentication bypass. This bug was a result of an incomplete fix for CVE-2022-27925.
On August 12th, 2022, NVD published Volexity’s authentication bypass as CVE-2022-37042.
Attackers can chain CVE-2022-37042 and CVE-2022-27925 to bypass authentication and upload arbitrary files such as web shells, leading to remote code execution. As of August 18th, 2022, GreyNoise has observed these two exploits in the wild with varying parameters appended to their POST paths:
Images showing POST paths used for exploiting CVE-2022-37042 and CVE-2022-27925
At this time, GreyNoise has not validated which parameters are required for exploitation.
Most of these POST attempts contain a zip archive starting with the bytes “PK” (\x50\x4B) that deploys a JSP web shell to the following path:
These JSP files act as a backdoor that attackers can later access for remote code execution.
GreyNoise has observed two different JSP payloads. The first is a generic web shell that allows arbitrary command execution:
Generic web shell allowing arbitrary command execution
The second appears to only log the string “NcbWd0XGajaWS4DmOvZaCkxL1aPEXOZu” and delete itself:
Logging the string “NcbWd0XGajaWS4DmOvZaCkxL1aPEXOZu” followed by deletion
CVE-2022-31656: VMware Workspace ONE Access, Identity Manager, and vRealize Automation contain an authentication bypass vulnerability affecting local domain users. A malicious actor with network access to the UI may obtain administrative access without needing to authenticate.
CVE-2022-31659: VMware Workspace ONE Access and Identity Manager contain a remote code execution vulnerability. A malicious actor with administrator and network access can trigger remote code execution.
VMWare has published patched versions of the products to remediate the vulnerabilities.
GreyNoise has created tags for tracking and blocking exploit activity on these CVEs that are live and available to all users:
We have not observed either of these CVEs being actively exploited in the wild, as of the publication date of this blog.
Disclosure Discussion
On August 2, 2022, Petrus Viet, the researcher responsible for disclosing the vulnerabilities to VMWare, tweeted a screenshot demonstrating successful exploitation of the CVE-2022-31656 authentication bypass, but did not include proof-of-concept (PoC) code).
Based on the screenshot, GreyNoise researchers speculate that Petrus’ work was based on the Horizon3 CVE-2022-22972 PoC , a similar authentication bypass discovered in May 2022.
Figure 1: Comparison between Horizon3 CVE-2022-22972 PoC (left) to Petrus’ CVE-2022-31656 exploitation screenshot.
A blue teamer with a keen eye may note that the working directory for the CVE-2022-31656 exploit is “D:\Intellij\horizon”, perhaps hinting at Horizon3, in addition to several messages logged to the console that are similar to those from the Horizon3 CVE-2022-22972 PoC:
Extraction of “protected_state” from a WorkSpace ONE endpoint
A POST request to the auth endpoint
A resulting “HZN” cookie which is granted access to the workspace ONE application
The main difference appears to be where the “protected_state” is extracted. These similarities gave key hints to the paths in the application defenders should monitor for exploitation.
On August 9th, 2022, Petrus published a writeup ) for both vulnerabilities but did not provide any POC code. GreyNoise created tags for these CVEs based on paths from this writeup.
Figure 2: Path for Authentication Bypass (CVE-2022-31656)
Figure 3: Path for Remote Code Execution (CVE-2022-31659)
Mitigation Actions
GreyNoise tags for tracking and blocking this activity are live and available to all users:
Until you can install the patched versions of these VMWare products, GreyNoise offers a temporary mitigation you can apply:
Block mass exploit IP addresses - GreyNoise is monitoring these CVEs for mass exploit activity, including curating a dynamic list of IP addresses attempting to exploit this vulnerability over the past 24 hours. You can use this IP list to block temporarily until you have had time to install a patched version. The IP addresses can be downloaded in several formats, including JSON, CSV, TXT files, as well as dynamically updated URLs for use with Palo Alto Networks, Cisco, and Fortinet firewalls. The IP lists are available at the links above.